 Оценка 160
Оценка 160 
 Оценить
Оценить 





| Оценка 160 Оценить
|
| Вместо введения Отслеживание запросов на изменение Контроль версий Сбор метрик Документирование деятельности CM Выбор инструментария Заключение Использованные источники |  |
Перед вами вторая часть статьи про управление конфигурацией программных средств. В части первой было рассказано о том, какие задачи решает управление конфигурацией программных средств (software configuration management, CM). Там же было рассмотрено, как управление конфигурациями позволяет стабилизировать результаты работы и определять базовые конфигурации разрабатываемых приложений.
В этой части речь пойдет о том, как надо отслеживать изменения в конфигурациях и какие средства для этого используются. Кроме того, будет показано, как практики CM определяют порядок отслеживания изменений при работе в команде. Также не обойдем вниманием некоторые формальные вещи, такие как сбор метрик и документирование CM-деятельности.
Итак, в части первой мы выяснили, что задача управления конфигурацией – определение того, что будет изменяться в проекте, и того, как именно мы будем отслеживать изменение. Рассмотрим вторую задачу.
Для начала, как вообще возникают изменения в рамках работы над проектом? Вариантов несколько:
Первые два вида иногда объединяются, несмотря на то, что это по смыслу разные вещи. Конечно, бывает, что для исправления ошибки нужно сделать рефакторинг или же написание функциональности устраняет некоторые проблемы. Но в этих случаях всё сводится к тому, какой процесс работы над изменениями и какая терминология приняты в рамках проекта.
Изменяться может любой компонент проекта – это могут быть как исходные коды, так и требования, тесты – в общем, всё то, что перечислялось в первой части. Важно, что это всё изменяется и надо производимые изменения контролировать.
В зависимости от вида и продукта изменения различается и источник его запроса. В случае новой функциональности это будет, скорее всего, один из менеджеров или конечный пользователь. При рефакторинге – технический руководитель или разработчик проекта. При исправлении ошибки – любой пользователь системы, но, как правило, это тестер.
Итак, есть потребность в изменениях, и есть тот, кто эту потребность озвучит. Остается начать движение. Началом движения является подача запроса на изменение. Запрос на изменение – это предложение об усовершенствовании продукта, выраженное в виде записи в системе отслеживания запросов на изменения.
|
В англоязычных источниках такие запросы называются change request (CR). Встречается также термин problem or change request (PCR). В дальнейшем будем использовать аббревиатуру CR. |
В свою очередь, система отслеживания запросов на изменения – это программная среда, позволяющая производить учет предложений на изменения продукта и управление ответственностью за них. Ключевые слова во всей цепочке терминов: запрос, изменение, и отслеживание ответственности.
|
В русскоязычных источниках часто используется термин «система отслеживания ошибок». В англоязычной литературе встречаются change request management system, bugtracking system, issue tracking system. |
Как правило, хранилищем в подобных системах выступает БД, где один CR – это одна запись (чаще – связанный набор записей) в ней. CR после создания имеет следующую обязательную информацию:
Также может быть добавлена просто полезная информация (она может быть объявлена как обязательная, в зависимости от принятого процесса разработки):
Далее весь жизненный цикл записи – это последовательное назначение ответственного на разных этапах работы и добавление информации, необходимой для решения задачи. Как правило, устройство систем отслеживания можно свести к двум типам:
Системы второго типа встречаются чаще, чем первого. Их наибольшее различие – во внутреннем устройстве. Внешнее различие выражено только тем, можно ли добавлять новую структурированную информацию по ходу работы над CR. Но, независимо от типа системы, работа над записями в целом одинакова. Ведь главное – это организация процесса разработки, а инструменты – это следствие его выбора и оптимизации.
Посмотрим на типовой сценарий. Запись заведена, нужно начинать работать. Однако никакие изменения не должны вноситься бесконтрольно. Поэтому перед началом работы нужно получить одобрение менеджмента, который отвечает за функциональность, затронутую запросом на изменение. Роль менеджмента выполняет Configuration Control Board (группа контроля конфигурации) – группа, обладающая в рамках проекта правами на управление изменениями в рамках проекта. Также иногда используется термин Change Control Board и сокращение CCB.
Для дальнейшей работы возьмем систему отслеживания в виде машины состояний – так будет более наглядно. Набор состояний на схеме 1 – минимально необходимый, он может быть расширен и разбит на несколько шаблонов жизненных циклов. Этот набор возьмем для дальнейшего описания.
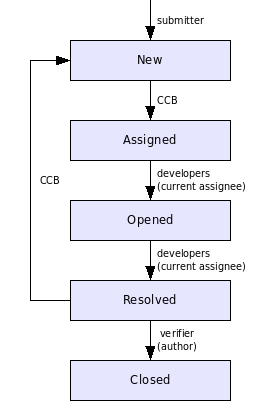
Схема 1. Жизненный цикл запроса на изменение
Первое состояние, в которое попадает любая запись, — начальное. На схеме 1 это New. На этом этапе создатель записи вносит все начальные данные, требуемые проектным процессом разработки. Далее CR попадает в поле зрения группы контроля конфигурации. Она принимает решение, кому из разработчиков отдать проблему для решения.
Для того, чтобы отдать CR в работу, запись необходимо перевести в следующее состояние – Assigned («приписано к ответственному»). Одновременно запись «назначается» на разработчика – т.е. он становится за неё ответственным.
Однако приписывание задачи кому-либо – ещё не означает, что задача сразу же начнет решаться. На одного разработчика ведь может быть назначено несколько задач – одна важней другой и все надо сделать ещё вчера. Поэтому когда разработчик на самом деле начинает заниматься задачей – он переводит запись в состояние Opened («работа начата»). CCB, отслеживающее работу, видит, что задача взята в оборот. Сама задача при этом, как правило, остается «приписанной» к разработчику.
По ходу работы ответственные могут меняться, в зависимости от того, кто владеет кодом, который влияет на описанное в CR поведение. Переназначения делает CCB. Кроме того, может выясниться, что проблема уже кем-то найдена и на неё был заведен свой CR. В этом случае проблема дуплицируется, т.е. закрывается, и в соответствующем поле добавляется номер записи, которая была заведена ранее. С этого момента запись считается закрытой. Может также выясниться, что описанная проблема не является ошибкой в работе (т.е. это WAD, works as designed) или же запрошенная функциональность не может быть реализована в силу разных причин. В этом случае запись терминируется, т.е. закрывается с комментариями о том, почему работа над проблемой продолжена не будет.
Если же всё-таки работа продолжается, то рано или поздно она заканчивается: разработчик внёс необходимые изменения и готов отдать их на дальнейшую интеграцию. В этот момент он переводит запись в состояние Resolved («исправлено» или «решение найдено»). Этим шагом инженер, назначенный для решения, снимает с себя ответственность и показывает те изменения, которые, по его мнению, должны решить задачу. В этом состоянии CCB вновь должна назначить ответственного. Он проверит, что задача, поставленная в CR, действительно решена правильно и всё работает как минимум, не хуже, чем было до её решения. Поэтому на данном этапе ответственным назначается или кто-то из тестеров, или же сам автор записи. После назначения проверяющий («verifier»), которым зачастую является автор запроса, начинает проверку. Результатом является следующее:
После чего изменения интегрируются в основной код продукта. За это отвечает уже СМ-инженер проекта и на него заводится отдельная запись в системе.
Кстати, стоит добавить, что системы отслеживания запросов на изменения также используются как системы назначения и отслеживания задач проекта. Ведь любая подобная задача требует отслеживания со стороны руководства. Да и результат большинства задач – это, опять же, какие-то изменения. Поэтому логично для всех целей использовать одну систему. Если предложенный жизненный цикл не подходит по каким-то причинам, большинство систем отслеживания позволяют этот цикл модифицировать и создавать несколько видов жизненных циклов – столько, сколько нужно для решения повседневных задач. Часто именно поэтому для отслеживания разработки новой функциональности создаются одни виды шаблонов, а для отслеживания процесса исправления ошибок — другие. А из-за того, что при разработке новых возможностей требуется ещё и разработка требований, дизайна, тестов, и также для удобства работы, вводятся промежуточные состояния или поля для перечисленных целей.
Реализация систем отслеживание запросов на изменения – едва ли не любимейшее занятие программистов всего мира. Кто-то считает, что его система-то уж точно затмит все имеющиеся. Кто-то уверен, что в остальных чего-то не хватает из того, что надо ему. А кто-то просто делает это ради собственного удовольствия. Каждому – своё. Тот, кто не захочет изобретать своё двухколесное средство передвижения, может ознакомиться с существующим велопарком по ссылке [2]. Ну и подобрать бицикл, что лучше всего подходит для его задачи. К слову, автору довелось принять некоторое участие в разработке упомянутого в приведенном списке eTraxis [3]. Его и порекомендую, пользуясь случаем.
Запросы на изменение отслеживать научились. И далее на CM-инженерах проекта лежит ответственность за:
Подробнее об использовании систем отслеживания запросов, а также об их совмещении с системами контроля версий, будет рассказано в соответствующей части.
Системы отслеживания внедрили, правила отслеживания запросов на изменение описали. Пора бы научиться отслеживать сами изменения как таковые и производить их интеграцию. Для этого существует контроль версий элементов конфигурации.
В первой части статьи уже было обозначено, что такое элемент конфигурации (configuration item, CI). Это – тот атомарный элемент, который будет под контролем CM’ной деятельности. Теперь надо дать возможность создавать версии и управлять их появлением, обеспечивая одновременную бесперебойную работу всей команды.
Определение версии было дано в начале статьи. Система контроля версий – это программное обеспечение, позволяющее создавать версии элементов и работать с этими версиями, как с самостоятельными элементами. Работа предполагает как создание самих версий, так и структуры для их хранения. Как правило, это или цепочки, или деревья.
|
В англоязычных источниках используется термин version control systems, сокращенно VCS. |
Далее будут описаны основные техники, реализованные в подавляющем большинстве систем контроля версий. Как они реализуются в приложениях, которые использует читатель, оставим на откуп многочисленным руководствам пользователя, how-to, FAQ и прочим документам, коих можно найти без труда. Главное – понять, по каким принципам и зачем оно работает именно так.
Прежде чем работать с элементами и их версиями, надо эти элементы создать, т.е. дать указать системе контроля версий взять имеющиеся объекты и поместить их под свой контроль. Вместе с самим элементом всегда создается и его первая версия.
Чаще всего в качестве элементов для контроля версий выступают
Внутри системы контроля элементы могут размещаться по-разному – это зависит от архитекторы VCS. Пользователю важно лишь знать, что элемент помещается внутри хранилища и работа с ним идет с помощью команд выбранного инструментария.
Как уже было сказано, системы контроля должны предоставлять структуры для хранения версий. Самым распространенным представлением подобной структуры является дерево версий. Это такая организация версий элемента, при которой на основе любой версии элемента конфигурации может быть создано несколько наборов последовательностей его версий. При этом отдельный набор, происходящий из версии, называется веткой. И поскольку ветка содержит версии, то каждая из версий может быть источником для создания других веток.
Название модели говорит само за себя: у растений (элементов) появляются почки и листья (версии), из них, в свою очередь, ветки. На ветках – листья (другие версии) и другие ветки. На них, опять же, произрастает всё та же растительность. В результате растет дерево, у которого крона – это множество версий. Один элемент – одно дерево.
Зачем нужна вся эта конструкция? Неужели нельзя просто наращивать версии одну за другой? Конечно, можно. Однако это сразу ограничит возможности использования подобной системы. Если версии появляются одна за одной, то в один момент времени создать новую версию сможет только один из пользователей, работающих с системой, остальные вынуждены будут подождать. Более того, когда появится новая версия, каждому надо будет соединить свои изменения с текущими наработками. И так – пока все желающие не поместят свои наработки в цепочку версий. При этом каждый должен будет убедиться, что слияние версий не привело к поломке системы. И, кроме того, пока все изменения не будут помещены таким образом под контроль, всем из ожидающих придется сохранять промежуточные результаты где-то локально, не смешивая с тем, что находится в настоящий момент в работе. И ладно, если пара человек работает над десятком элементов – они всегда смогут договориться. А если масштабы гораздо больше? Добавим десяток человек (даже не увеличивая количества элементов) – и подобные простые цепочки полностью застопорят работу. В общем, линейная структура версий порождает множество сложностей.
Итак, ясно, что без веток не обойтись. Но ведь не растить же ветку на малейший чих разработчика? Посмотрим, в каких же случаях отращиваются ветки. Типовые примеры веток таковы:
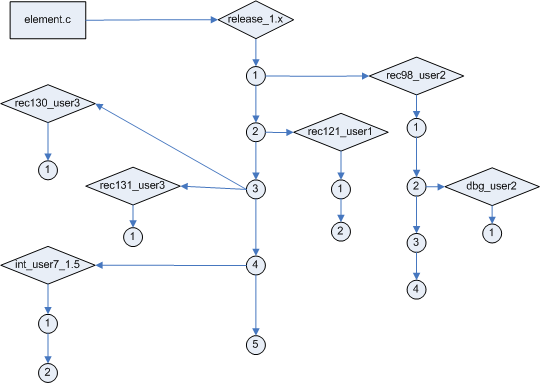
Схема 2. Дерево версий элемента element.c
На схеме 2 изображен пример дерева версий. У файла element.c создана релизная ветка release_1.x, куда складываются стабилизированные версии этого элемента (1-5). Для сохранения дельты по каждому запросу на изменения заводится отдельная ветка со специальным форматом имени. В нашем случае формат имеет вид rec<номер_записи>_<имя_пользователя>, где номер_записи – это ID запроса на изменение в системе отслеживания. Для объединения дельты от разных разработчиков создаются интеграционные ветки с названиями вида int_<имя_пользователя>_<суффикс>, где суффикс хранит описание интеграции или номер стабилизируемой конфигурации. Также можно увидеть ветку для отладки, чаще всего они именуются как dbg_<имя пользователя>_<произвольный_комментарий> - на неё выкладываются проверочные варианты изменений. Подробнее про отращивание каждой ветки из примера будет рассказано ниже по тексту.
Каждый проект может иметь свои способы создания и именования веток, однако основные из них были перечислены выше. Если используются продуктовые линейки, то становится необходимым использование всех перечисленных видов.
Дерево версий растет и ширится, и рано или поздно надо результаты работы объединять. Например, разработчик отрастил ветку у одного из элементов для работы над запросом на изменение. На неё он положил несколько версий, и последняя является той, которая содержит отлаженный и протестированный код. В то же время есть релизная ветка, где лежат версии, выпускаемые в рамках базовых конфигураций и стабильных релизов. Необходимо соединить результаты.
Для этого используется механизм слияния версий. Как правило, он подразумевает создание новой версии элемента, для которой в качестве основы берется базовая версия на выбранной ветке (база), и к ней применяются изменения, содержащиеся в выбранной сторонней версии (источнике).
|
В англоязычных источниках используется термин merge («мёрж»). |
Ветка с версией-источником может быть отращена как от версии-источника, так и от его более ранних предков.
Существующие VCS позволяют делать слияние как вручную, так и автоматически. Причем второй способ является основным. Ручное слияние запрашивается лишь в случае конфликтов.
Конфликты слияния возникают в случае, если в обоих версиях элемента меняется один и тот же фрагмент. Такая ситуация возникает когда предок версии-источника не является версией, от которой будет расти новая версия. Типичным примером такого конфликта может служить история изменений (revision history), которая добавляется в начало файла исходников, чтобы в каждой версии можно было сразу видеть, кто последним менял и что было сделано. В случае слияния версий, выросших от разных источников, эта строчка точно будет вызывать конфликт, и решается он лишь вставкой обеих строчек в историю. Когда возникает более сложный случай – разработчик или эксперт в затронутом коде должен внимательно вручную произвести нужные изменения.
К вопросу об общих предках и о слиянии изменений: кроме ручного и автоматического, слияние может быть произведено двухпозиционным и трёхпозиционным способом. Двухпозиционное слияние производится простым сравнением двух версий и сложением их дельты (разницы между версиями элемента). Алгоритм работает по принципу diff'а или приближенно к нему: взять дельту и вставить/удалить/изменить нужные строки.
Трехпозиционное слияние учитывает «общего предка» обеих версий и высчитывает дельту исходя из истории изменения элемента в соответствующих ветках. Соответственно, при возникновении конфликта слияния разработчику предлагается 3 версии элемента – общий предок и 2 варианта, что с этим предком стало с течением времени и изменений. Такой подход помогает оценить степень и важность дельты на обеих ветках и принять решение о необходимости интеграции конфликтного куска часто даже без участия авторов изменений.
После того как слияние проведено, информация о нём должна быть сохранена, если это возможно. Как правило, большинство зрелых VCS имеют возможность сохранить «стрелки слияния» – метаинформацию о том, откуда, куда и в каком момент времени сливались изменения и кто это делал.
Рассмотрим пример – дерево версий элемента на схеме 3, продемонстрировав порядок отращивания и слияния веток на нём. Как уже можно догадаться, дерево целиком взято со схемы 2, но к нему добавлены стрелки слияния.
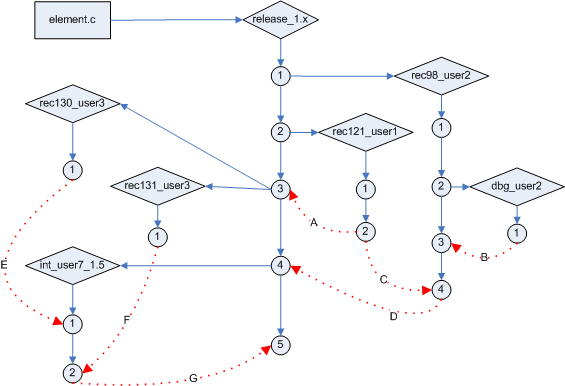
Схема 3. Пример слияния изменений между разными ветками
Итак, в проекте производится некий продукт, в который входит файл element.c. Чтобы хранить стабилизированные версии, в команде принято соглашение о том, что все стабильные или базовые версии хранятся на ветке «release_1.x». Это будет называть «релизная ветка». Наш элемент не исключение, и на релизной ветке создается начальная версия 1.
Для простоты обозначения будем описывать ветки, как если бы это были директории на диске. Соответственно, первую версию назовем /release_1.x/1.
Далее, кто-то из менеджеров в системе отслеживания запросов на изменение (далее будем называть эту систему просто «багтрекер») завел запись номер 98, где описал новую функциональность продукта. И, конечно же, назначил ответственным за эту задачу одного из пользователей – пусть это будет user2. user2 подумал немного и начал эту задачу решать, а по истечении какого-то времени решил поместить получившиеся исходники в систему контроля версий. Согласно стандартам именования, принятым в рамках проекта (CM-политикам), ветку для внесения изменений в нашем проекте называют rec<номер-записи>_<пользователь>[_<комментарии>]. Поэтому новая ветка была названа rec98_user2, а от комментариев её создатель воздержался. Работа кипит, появляется версия /release_1.x/rec98_user2/1, а потом и /release_1.x/rec98_user2/2. На этом пока оставим разработчика user2, пусть думает над задачей.
Ведь пока он работал, в багтрекере была зарегистрирована запись (CR) за номером 121, в которой описали новую ошибку, найденную тестерами. Запись эта была закреплена за пользователем user1, и он начал успешно описанную ошибку исправлять. По мере исправления он решил завести ветку для сохранения результатов. Новую ветку, согласно проектным политикам, пользователь назвал rec121_user1. Заметим, что на момент начала работы и создания ветки кто-то уже добавил очередную стабильную версию на релизную ветку – /release_1.x/2. Поэтому ветка отращивается от последней на тот момент версии (второй). Ветка создана – можно создавать на ней версии. Конечный результат – версия /release_1.x/rec121_user1/2.
Что дальше? Ошибка исправлена, исправление протестировано (эту плоскость работ мы пока оставим за кадром) – пора делать эти изменения частью стабильной конфигурации и, возможно, новой базовой конфигурацией. Здесь начинает работу CM-инженер или тот участник команды, который выполняет эту роль. С помощью лома и кувалды... пардон, с помощью команды слияния он создает новую версию на релизной ветке – /release_1.x/3. Обратите внимание на стрелочку A – она отображает как раз процесс слияния.
Вернемся к пользователю user2 – он как раз надумал сделать некоторые изменения, однако решил сначала на скорую руку проверить, что получится, и дать коллегам посмотреть на своё решение. Для этого он создает отладочную ветку. CM-политика проекта говорит, что она должна называться dbg_<пользователь>[_<комментарий>]. Соответственно, новая ветка будет именоваться /release_1.x/rec98_user2/dbg_user2. На ней пользователь и создает версию /release_1.x/rec98_user2/dbg_user2/1. Было решено взять полученное решение в основной код, поэтому автор сделал слияние новой дельты и той версии, от которой отращивалась ветка. Вместе с тем, пользователь почистил и оптимизировал код, чтобы было не стыдно отдавать его на интеграцию – в результате получилась версия /release_1.x/rec98_user2/3. Ну а яркая стрелочка B наглядно обрисовывает процесс слияния.
Однако user2 узнает, что за время его работы была исправлена серьезная ошибка, для которой был заведен CR #121. И это исправление может повлиять на работу новой функциональности. Принимается решение соединить обе дельты и посмотреть, что из этого получится. Делается версия /release_1.x/rec98_user2/4, созданная на базе /release_1.x/rec98_user2/3, куда будут применены изменения из /release_1.x/rec121_user1/2. Ну и стрелочка слияния C также появляется. Эта новая версия проверяется на работоспособность и наличие ошибок, и принимается решение – надо интегрировать! CM-инженер снова берет свои инструменты и создает версию /release_1.x/4, рисуя к ней соответствующую стрелку D.
Однако жизнь не стоит на месте. Пока наши два разработчика вносили и сливали вместе дельту, другие участники команды уже изменили тот же самый файл. Было заведено два CR'а – 130 и 131, закрепленных затем за пользователем user3. Он их успешно закончил и сделал две ветки – по одной на запись. Поскольку задачи ставились и решались в разное время, то и ветки для их решения отращивались от разных версий на релизной ветке. В итоге получились версии /release_1.x/rec130_user3/1 и /release_1.x/rec131_user3/1, отращенные от версии /release_1.x/3.
Есть изменения – надо их объединить, стабилизировать и сделать базовой конфигурацией, если всё нормально. Для этой цели CM-инженером, который в системе контроля версий проходит под оперативным псевдонимом user7, создается интеграционная ветка, имеющая в данном проекте вид int_<пользователь>_<номер-будущего-релиза>. Стало быть, появляется ветка /release_1.x/int_user7_1.5. В неё сливаются вместе обе дельты. Сначала изменения для записи 130, с образованием версии /release_1.x/int_user7_1.5/1. Затем – для записи 131, для неё создается версия 2 на той же ветке. Для всех операций рисуются стрелочки слияния.
Финальный аккорд CM-инженера – слияние версии /release_1.x/int_user7_1.5/2 на релизную ветку с образованием версии /release_1.x/5. Впоследствии эта ветка станет частью базовой конфигурации продукта.
Вот такое вот немаленькое описание маленькой картинки. Один рисунок стоит сотен слов – правду говорят.
У внимательного читателя в голове наверняка крутится вопрос – если у нас всё делается через ветки и стрелки слияния – откуда взялась версия /release_1.x/2? Ведь к ней не ведет ни одной стрелки ни от одной ветки! Закономерный вопрос. Ответ тоже закономерен. Да, бывают ситуации, когда изменения вносятся напрямую в релизную ветку. Например, была найдена страшная ошибка, внесенная вместе с первой версией – забыли внести в раздел revision history комментарий о том, кто же внёс изменения! Конечно, это шутка, никто не будет нарушать политику ради вот таких вот мелочей. Однако и такое случается. Главное – точно знать, кто создал новую версию, и зачем он это сделал. Лучше всего, если система контроля версий позволяет ограничивать права на создание версий для каждой ветки в отдельности. В этом случае мы дополнительно обезопасим проект тем, что дадим права на добавление версий на релизной ветке только CM-инженеру. По крайней мере, с подобным ограничением будет проще найти крайнего.
После изложенного выше, надо ли говорить, что возможность работы с ветками является фактически базовой функциональностью любой зрелой системы контроля версий? Без веток система контроля версий может считаться таковой только с формальной точки зрения – просто потому, что она умеет хранить и выдавать версии, но не более.
Итак, дерево версий растет, работа команды идет своим чередом. Возникает необходимость стабилизировать результаты работы и определить базовую конфигурацию, которую в любой момент времени любой участник команды сможет взять из системы контроля версий. Стабилизация производится путем слияния версий – об этом будет рассказано чуть ниже. А вот на определении базовой конфигурации остановимся подробнее.
Получение базовой конфигурации – это по сути своей выявление набора стабильных версий и определение способа их однозначной идентификации. Для этих целей в системах контроля версий существует механизм «навешивания меток». Метка – это цифро-буквенное обозначение, однозначно определяющее конфигурацию. Имея метку, нужно всегда уметь точно и недвусмысленно выделить конфигурацию.
|
В англоязычных источниках в основном используются термины label и tag. |
Если метка – это обозначение для конфигурации, то и каждая из версий конфигурации должна однозначно определяться этой меткой. Таким образом, по метке будет выбираться элемент в той своей версии, которая помечена нужным образом.
Реализация концепции меток может различаться в разных системах. В одних (от CVS до ClearCase) метка – это атрибут версии элемента. Например, на схеме 3 метка бы вешалась прямо на одну из версий, т.е. была бы просто биркой рядом с кружком. В других системах (Subversion) под меткой понимается всего лишь одна из разновидностей веток. Каждому – своё, главное, чтобы вкладываемый смысл оставался одним и тем же.
Что ещё хотелось бы отметить: одна конфигурация может быть помечена несколькими метками. Например, рассмотренные в первой части статьи компоненты могут быть помечены как компонентными метками (для определения базовых конфигураций компонентов), так и продуктовыми – для того чтобы официально становиться частью базовой конфигурации продукта. Получается, что базовая конфигурация каждого компонента помечается, как минимум, два раза – один раз компонентной меткой, второй – продуктовой.
В целом, метки – это средство обозначения конфигураций, поэтому по большей части они являются инструментом работы CM-инженеров. Разработчики лишь используют уже сделанные метки для того, чтобы регулярно получать базовые конфигурации для дальнейшей работы.
Для полноты картины использования систем контроля версий осталось рассказать о распределении этого контроля между командами разработки, расположенными в разных географических точках.
Итак, есть система контроля версий, обслуживающая несколько команд. В какой-то момент возникает необходимость сделать доступным центральное хранилище локально в одном из центров разработки – для ускорения работы и обхода ограничений по трафику или пропускной способности. Скажем, есть две команды, расположенные территориально в разных местах и часовых поясах – скажем, Дальний Восток России и Центральная временная зона США, их разделяет полмира. Работа идет над одним проектом, и есть необходимость менять одни и те же части продукта. Предположим, что сервер системы контроля версий стоит в США – соответственно, разработчикам в России для создания каждой новой версии приходится отправлять изменения через половину земного шара. Да и любая операция вроде перехода на другую ветку со взятием целиком всей выбранной конфигурации, будет отнимать слишком много времени. Ведь высокоскоростной Интернет есть пока не везде, на и стабильность соединения в некоторых уголках мира ещё пока оставляет желать лучшего. В общем, в подобных ситуациях централизованное хранилище – не самый удобный вариант.
Поскольку проблема не нова и актуальна, со временем были сформулированы разные подходы к решению задачи. А точнее – два подхода к построению распределенных систем контроля.
Открытое распределение – это принцип построения, при котором каждая рабочая копия конфигурации может иметь свой набор дочерних версий, и обмен созданными версиями происходит по выбору создателя изменений.
Плюсом подобных систем является то, что работа на отдельной рабочей станции может идти независимо от других экземпляров хранилища. Собственно, хранилища может и не быть – сколько копий, столько и хранилищ. Не удивительно, что подобные системы нашли применение в первую очередь в Open Source. Отсутствие необходимости содержать отдельный сервер дает возможность обмениваться только той информацией, которая нужна, и не перегружать хранилище и трафик той дельтой, которая может кому-то никогда так и не понадобиться.
Минус подобного подхода в том, что обмен дельтой рабочих продуктов плохо поддается контролю. Получается некоторое броуновское движение, которое многим менеджерам, привыкшим к централизации, может быть не по душе.
Примерами подобных систем могут быть BitKeeper, git, Mercurial (Hg).
Распределение путём репликации предусматривает создание равноценных копий центрального хранилища данных на всех распределенных серверах. Здесь можно провести аналогию с базами данных и их репликацией. Для каждого разработчика хранилище версий, к которому он подключается, является основным. Все версии и ветки создаются только в центральном хранилище. Для распределения данных делается копия хранилища на удаленном сервере и часть разработчиков переключается на него. При необходимости обмена результатами работы происходит репликация хранилища – оба сервера обмениваются метаинформацией.
Плюсом подобного подхода можно считать централизацию работы в рамках одного местоположения команды. Также стоит добавить, что имеется возможность оградить часть накопленной информации от синхронизации с другими командами, но в то же время делать её доступной одновременно всей локальной команде. Это бывает важно, когда код разрабатываемых подсистем не должен попадать наружу – даже к другим командам, работающим над этим же продуктом.
Минус – необходимость настройки механизмов репликации. Но, как правило, системы, использующие такой подход, предусматривают инструменты эффективного обмена данными. Кроме того, для кого-то может быть минусом тот факт, что все операции с версиями производятся на одном сервере, а не на локальном компьютере разработчика. То есть «распределённость» системы проявляется на уровне команд и их местоположения, но никак не на уровне простого разработчика.
Примерами систем с репликацией служат ClearCase и Perforce.
Оба типа (открытый и репликационный) схожи между собой – в обоих случаях происходит обмен информацией между разными копиями одного множества элементов и их версий. Разница между ними – в масштабах. В системах с репликацией минимальной единицей реплики, как правило, является репозиторий или его значимая часть, обрабатываемая как единое целое. В системах с открытым распределением минимальная единица обмена информацией – это отдельная версия отдельного элемента.
Для обоих типов распределения характерна общая проблема. Это необходимость введения четкого соглашения об именовании элементов и их веток, а также меток для обозначения полученных конфигураций. При соединении результатов работы не должны получаться разные файлы с одним и тем же именем и метаинформацией (ветками, метками, атрибутами). Поэтому все разработчики и команды, работающие отдельно друг от друга, должны придерживаться общих стандартов. В разных системах бывают предусмотрены различные механизмы для обеспечения этого условия. К примеру, при работе с ClearCase создаются триггеры на создание любой метаинформации, проверяющие её на соответствие стандарту – для всех создаваемых веток ставится необходимым наличие в имени ветки кода (или идентификатора) того сайта (команды), где ветка была создана.
Кроме того, системы с открытым распределением фактически оставляют на усмотрение каждого отдельного разработчика, что он отдаст команде в виде дельты, а что не станет выставлять на общее обозрение. Плохо это или хорошо, зависит от культуры, принятой в рамках проекта. В более централизованных системах с репликацией репозитариев эта проблема принимает другую форму. Когда все обязаны вносить свои изменения в центральную (для своей команды) систему контроля версий, база метаинформации быстро разрастается в размерах, что сказывается как на стоимости хранения, так и на скорости репликации разнесенных в пространстве баз.
Какой из подходов лучше, конечно, нельзя сказать сразу и для всех проектов. Приспосабливать для работы броуновское движение git'а или остановиться на более стабильном состоянии – решать менеджменту каждого проекта. Единого решения для всех команд и проектов нет и быть не может. Кому интересно посмотреть на различия разных систем и моделей – см. ссылку [5]. Кроме того, стоит прочитать статью [9] о рисках, связанных с распределенными системами контроля.
Кстати, распределенными могут быть не только системы контроля версий, но и системы отслеживания запросов на изменение. Логика работы совершенно аналогична. Вот только основная модель работы – репликационная. Пример – IBM Rational ClearDDTS. Поскольку подобные системы не очень распространены, останавливаться на них подробно не будем.
После глобальных вопросов мироздания, управления конфигурациями и веткостроения, перед тем как закончить рассказ об основах CM, остановимся ещё на паре вопросов. Они менее важны с точки зрения простого разработчика, но много значат с точки зрения управления проектом.
Что важно для менеджера, когда перед его глазами должна развернуться вся картина происходящего в рамках проекта? Конечно, это цифры. Для контроля над ситуацией руководитель должен видеть не только то, что имеется в настоящий момент, но и то, что было ранее. Соответственно, только имея это целостное видение, можно прогнозировать будущее проекта, корректировать сроки – в общем, вести нормальную управленческую деятельность.
При чем здесь CM? Он контролирует изменения. Если учесть, что любой проект — это изменение рабочих продуктов, то через CM проходят все изменения всего проекта. Стало быть, именно средства управления конфигурацией ПО могут давать менеджерам видение того, как изменяется проект во времени. Обычно подобное видение выражается в виде чисел.
Какие же числовые показатели (метрики) можно получить из того, что проходит ежедневно через руки CM-инженеров?
В первую очередь, это всё, что касается учета запросов на изменение продукта:
Всегда интересна общая информация о коде, как-то: количество строк кода продукта и компонентов. Обычно они считаются в CLOC, NCLOC.
Далее – всё, что касается вносимых изменений:
Возможны более экзотические варианты запросов, в зависимости от возможностей инструментария и потребностей проекта:
Также могут быть интересны отчеты по произведенной работе самих CM-инженеров:
Разумеется, все данные выдаются не только в виде текстовых отчетов, но и в виде самых разных диаграмм – благо, видов их придумали много. Также по многим показателям можно отследить развитие величин во времени.
Итого: сбор метрик – вещь неотъемлемая от CM в рамках больших проектов.
Все политики, процедуры и правила, которые устанавливает CM-инженер проекта, должны быть доведены до всех участников проекта. Форма предоставления этой информации не очень важна – главное, чтобы она вообще была предоставлена в срок и была постоянно доступна всем желающим. Как правило, всё, что описывается и формализуется в CM, принято объединять термином «план управления конфигурацией проекта».
|
В англоязычных источниках используется аббревиатура SCMP – Software Configuration Management Plan. |
Этот план описывает всё, чем оперирует управление конфигурацией проекта. Сюда входит следующая информация:
SCMP может быть оформлен и как отдельный документ, и как серия публикаций в используемой системе документооборота команды разработчиков – например, в Wiki. Главное, чтобы информация была полной, своевременной и доступной для конечного потребителя.
Как писал классик, «серебряной пули нет». Я с ним полностью согласен. Конкретный инструмент выбирается под конкретную задачу. Поэтому здесь не будет рассказа о том, в каких случаях какие инструменты применять. Остановимся лишь на общих рекомендациях. Кому-то они покажутся банальными, но ведь мы говорим об основах.
В первую очередь, при выборе инструмента надо смотреть на контингент, который его будет использовать:
Проект с 20 участниками, из которых 10 контент-редакторов, 2 дизайнера, 3 тестера, 4 менеджера и только один программист, явно не нуждается в промышленной системе контроля версий вроде IBM Rational ClearCase. Им вполне хватит CVS. Однако им вполне может потребоваться специфичная система отслеживания запросов на изменения – ведь именно изменениями будет заниматься больше десятка человек всё рабочее время. Возможно, им даже придется покупать лицензии на систему вроде JIRA, соединенную с Confluence. А если при этом команда раскидана по 3 офисам в разных городах, возможно, им проще будет купить хостинг для такого решения. Тогда они не будут зависеть от приходящего админа для сервера или перебоев с интернетом в головном офисе, где, как правило, устанавливаются всё подобное обеспечение.
Следующий аспект – инфраструктура, используемая для работы. Причем под инфраструктурой надо понимать не только ОС на серверах, где будет работать разрабатываемая система. Участники проекта ведь также работают за определенными компьютерами. Стало быть, чтобы выбрать что-то, что их всех объединяет, надо учитывать и то, что уже существует и поменяется не сразу (если вообще поменяется). К инфраструктуре можно отнести:
Если компания ведет разработку, используя продукты и инфраструктуру от Microsoft, включая средства разработки, то нет смысла пересаживать всех на open-source аналоги, достаточно грамотно задействовать уже имеющиеся продукты, на которые куплены лицензии. К примеру, для контроля версий вполне подойдет Team Foundation Server, а в качестве хранилища выпускаемых стабильных конфигураций, вместе с их release notes, использовать MS Sharepoint. Его же, после обработки напильником, можно сделать и системой отслеживания запросов на изменения.
Ну и, конечно же, на используемые инструменты накладывает свой отпечаток и сама разрабатываемая система:
Представьте коммерческий продукт – сотовый телефон – состоящий из нескольких десятков компонентов, общий объем исходных кодов которых исчисляется сотнями мегабайт. И всё это в команде, состоящей в общей сложности из нескольких сотен человек, рассредоточенных по нескольким разбросанным по всему миру командам. В этом случае выбор будет сделан в сторону промышленных и далеко не бесплатных решений. Один из подобных примеров – Motorola, с которой мне довелось поработать. ClearCase, распараллеленный на десятки серверов Sun, развитый build management на его основе, Compass и Perforce на части проектов – вот лишь некоторые крупные коммерческие продукты, применявшиеся в пору моей работы. Под такие задачи можно уже подгонять и остальные параметры – каналы связи и программно-аппаратное обеспечение.
Вот, вкратце, те параметры, на которые надо обращать внимание при сравнении любых инструментов для SCM. Более узкие критерии и рекомендации выбираются исходя из класса инструментов. К примеру, кому-то может понадобиться подробное разграничение прав в системе контроля версий – например, давать права на создание версий на релиз-ветках только CM-инженерам.
Кстати, по ссылкам [2] и [5] можно найти сравнительное описание большинства самых известных систем отслеживания запросов на изменение и систем контроля версий. Так что выбирайте и, лучше всего, пробуйте в тестовых режимах те системы, которые вам по каким-то причинам понравились. От одного призываю воздержаться – от написания своих инструментов с нуля без очень веских на то оснований. Не усложняйте проблему выбора инструментов своим потомкам.
Пора заканчивать. Теоретические основы CM изложены, подведем итог. Для начала, что осталось неохваченным.
При всей подробности изложения, всё-таки остались вещи, которые лучше оставить для дальнейшего обсуждения.
Как уже мог заметить внимательный читатель – в статье практически не упоминаются конкретные продукты. Наблюдение верное. Описание существующих систем, а также сравнение их возможностей – предмет для написания целой книги или хотя бы серии статей. Так что ваша любимая поисковая система легко подскажет, где искать подобные сравнения. Добавлю только, что следовать описанным практикам можно с использованием практически любого из приложений, имеющихся в современном велопарке. Посмотреть примерный список существующих аналогов можно по ссылке [5].
Кроме систем контроля версий и отслеживания ошибок есть большая область систем build management – управления сборкой программных средств. Наладка процесса сборки продуктов из исходников – функция CM-инженера проекта или того, кто выполняет эту роль. Собирать продукты должен иметь возможность и рядовой разработчик. Однако настроить сам процесс – задача CM.
Рассказывая про компонентный подход и CM, нельзя не упомянуть отслеживание зависимостей в проектах. Для больших продуктов, особенно с распределенной командой разработки, вопрос этот стоит зачастую остро. Решение задач по отслеживанию зависимостей лежит, в основном, на менеджменте проекта – его технических руководителях и архитекторах. CM-инженеры выполняют в основном прикладные задачи: инструментальную поддержку и отслеживание выполнения задуманных мероприятий. Кроме того, интеграция взаимозависимых компонентов также ложится на их плечи – вместе со всеми связями и зависимостями.. В общем, задача эта сложна, и ей можно посвятить немало страниц текста и диаграмм.
Также в статье обойдены вниманием CM-аудиты – проверка процессов в рамках проекта, связанных с CM. Вещь эта довольно формальная и применима только в крупных компаниях, как правило, внедривших промышленные стандарты качества – ISO или CMMI.
В целом, в обеих статьях были рассмотрены основы управления конфигурацией ПО. Как применять эту теорию с конкретными инструментами – зависит от проекта. Если в вашем проекте возникнут вопросы, затронутые в этих статьях – вы знаете, куда копать.
| Оценка 160 Оценить
|