 Оценка 561
Оценка 561 
 Оценить
Оценить 





| Оценка 561 Оценить
|
В этом небольшом Q&A рассматривается «проблема» эскалации блокировок (lock escalation). Слово «проблема» намеренно взято в кавычки, так как на самом деле это никакая не проблема, а достаточно остроумное решение других потенциальных проблем. Сначала я попытаюсь объяснить, что же такое эскалация и для чего она предназначена, а потом будет разобрана реализация эскалации блокировок в Microsoft SQL Server 2000.
Как правило, в СУБД организация данных представляет собой некоторую иерархию. Например, «файл->база данных->таблица->страница данных->запись->поле в записи». Некоторые уровни этой иерархии могут быть переставлены местами или же чисто виртуальными, а то и отсутствовать вовсе. Все это зависит от особенностей конкретной реализации и даже используемой терминологии, и в данном случае имеет мало значения, важно лишь, что в том или ином виде подобная иерархия присутствует практически всегда. В СУБД реализующих механизм иерархических блокировок (multigranularity locking) для обеспечения параллельной обработки транзакций, наложить блокировку можно на объект, находящийся на любом уровне этой иерархии. При этом автоматически блокируются соответствующие объекты на нижележащих уровнях. Например, монопольная блокировка на страницу данных, блокирует все записи входящие в эту страницу. Но при этом, естественно, записи на соседних страницах ни коим образом не блокируются. Обычно, для обозначения объема блокируемых данных применяют термин «гранулярность» (granularity). Более крупная гранулярность означает блокирование объекта на более высоком уровне иерархии и, соответственно, всех входящих в него объектов обладающих меньшей гранулярностью.
Вот теперь мы собственно и подобрались к предмету обсуждения. Эскалация блокировок – это процесс, при котором множество блокировок с маленькой гранулярностью, конвертируются в одну блокировку на более высоком уровне иерархии с большей гранулярностью.
Действительно, на первый взгляд не надо. Интуитивно ход мыслей примерно таков: Блокировка на более высоком уровне иерархии вызывает блокирование объектов на более низком уровне, в том числе и тех, которых, в общем-то, блокировать не надо. А это ведет к уменьшению степени параллелизма транзакций и в конечном итоге к падению производительности. Но на самом деле эффект обратный. Если копнуть поглубже, то выясняется, что в некоторых случаях выгоднее блокировать объекты, с большей гранулярностью.
Традиционно выделяют три эффекта от наложения блокировок, приводящие к тому, что в некоторых случаях выгоднее блокировать на более высоком уровне упомянутой выше иерархии.
Locking overhead. Как бы быстро ни накладывались и снимались, и сколько бы мало места не занимали сами блокировки, все равно может наступить момент, когда выгоднее наложить одну блокировку с большей гранулярностью, чем несколько (или несколько тысяч) более мелких. Невзирая на издержки связанные с блокированием лишних объектов.
Data contention. Наложение одной блокировки - действие атомарное, однако, наложение нескольких блокировок уже таковым не является. Между наложением двух блокировок в одной транзакции сервер, руководствуясь соображениями наибольшей эффективности, может выполнить одну, или даже несколько, других транзакций целиком. Но если первая транзакция выполняется относительно долго и накладывает много мелких блокировок, то возможно возникновение неприятных побочных эффектов. Допустим, есть одна длинная транзакция T1, которая блокирует множество записей. В какой-то момент она стартовала и начала накладывать свои блокировки. К тому времени, когда T1 успела захватить несколько объектов, начинают выполняться транзакции Tx, которые, в свою очередь блокируют записи, которые T1 скоро понадобятся, но добраться до них T1 еще не успела. В итоге T1 вынуждена ждать, пока транзакции Tx отработают, при этом, пока она ждет одну из Tx, этих транзакций (захватывающих записи до которых T1 не успела добраться) может стать еще больше. Таким образом, время, затрачиваемое на выполнение T1, значительно возрастает. Положение усугубляется тем, что после начала выполнения T1 могут появиться транзакции Ty, которым нужны те объекты, которые T1 уже успела захватить, а поскольку время выполнения T1 растет, то растет и время ожидания транзакций Ty на объектах заблокированных T1.
Resource contention. Блокировки, помимо того, что просто занимают место, нуждаются так же и в некотором обслуживании, которое расходует системные ресурсы. Например, регулярная проверка графа ожидания транзакций на наличие взаимоблокировок (deadlock), занятие довольно-таки накладное. И чем больше блокировок, тем больше ресурсов расходуется на подобные проверки. Вдобавок, попросту существует предел количества транзакций, которые могут выполняться в системе одновременно без ущерба для производительности. В определенный момент множество одновременных транзакций сходятся в борьбе за процессорное время и другие ресурсы системы. Все это опять-таки приводит к увеличению времени отклика и общему падению производительности.
Таким образом, воздействие этих трех факторов приводит к тому, что в некоторых случаях, когда число блокировок велико и в системе выполняются довольно длинные транзакции, с точки зрения производительности, становится выгоднее блокировать объекты с большей гранулярностью. Уменьшается общее число блокировок, снижается время выполнения длинных транзакций и, как следствие, коротких, которые вынуждены ожидать длинные, расходуется меньше системных ресурсов. На рисунке 1 показаны качественные графики зависимости производительности от гранулярности блокировок для коротких и длинных транзакций.
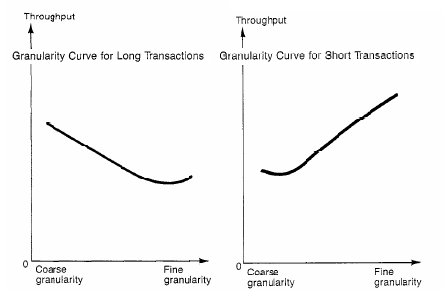
Рисунок 1. Графики зависимости производительности от гранулярности блокировок для коротких и длинных транзакций.
Основная проблема в том, чтобы определить, с какого момента считать транзакцию достаточно «длинной». К сожалению, не всегда можно определить стратегию наложения блокировок на этапе компиляции, поэтому иногда приходится выполнять увеличение гранулярности динамически, прямо в ходе выполнения запроса.
В качестве практической реализации механизма эскалации блокировок можно привести Microsoft SQL Server. В данном случае интересующая нас иерархия объектов такова: «таблица->страница данных->запись».
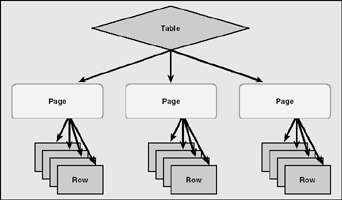
Рисунок 2. Иерархия объектов в MSSQL
По умолчанию, если не вмешиваться в логику работы сервера, он старается наложить блокировку на запись, то есть блокировку, обладающую наименьшей гранулярностью. Но если сервер посчитает, что блокировать на уровне отдельной записи не самое оптимальное решение, то он заблокирует больший объем. Однако можно указать явно, с какой гранулярностью блокировать, с помощью специальных подсказок оптимизатору (hints).
Если же в таблице построены индексы, то можно обойтись и без явного указания гранулярности в запросе. С помощью специальной системной хранимой процедуры, sp_indexoption, можно задать гранулярность блокировки индекса. Таким образом, все выборки из таблицы по этому индексу будут идти на заданном уровне иерархии без явных указаний.
| ПРИМЕЧАНИЕ На запросы, не использующие индексы, настройки sp_indxoption не действуют. Но если в таблице есть кластерный индекс, а в этом случае страницы данных являются частью индекса, то гранулярность, указанная для кластерного индекса, будет использоваться и для запросов, выполняющихся без участия индексов. |
Но по большому счету все эти настройки гранулярности работают только в одну сторону. Можно попросить сервер блокировать только на уровне записи, но если в процессе выполнения запроса ему покажется, что это слишком мелко, то он все равно эскалирует блокировку. Зато если указать, что нужна блокировка на уровне страницы, то на уровне записи блокировки не будет никогда, а только на уровне страницы или таблицы. Если же запросить табличную блокировку, указав это явно или через настройки индекса, то блокироваться всегда будет таблица целиком и никогда отдельная запись или страница.
Как уже говорилось, сервер может повысить гранулярность блокировки прямо в ходе выполнения запроса, при этом эскалация происходит всегда до уровня таблицы, даже если перед этим блокировались отдельные записи. SQL Server определяет необходимость эскалации исходя из следующих соображений: Если число блокировок наложенных одной транзакцией превышает 1250, или число блокировок на один индекс или таблицу больше 765, и если при этом больше сорока процентов памяти доступной серверу используется под блокировки, тогда сервер выбирает наиболее подходящую таблицу и пытается эскалировать блокировки до табличного уровня. В случае неудачи, если на некоторые записи таблицы наложены несовместимые блокировки других транзакций, сервер не ждет, а продолжает работать на прежнем уровне гранулярности до следующей попытки. Таким образом, исключается возможность взаимоблокировки непосредственно по вине эскалации.
Не сложно заметить, что вследствие эскалации блокировок, никогда нельзя быть уверенным с какой гранулярностью сервер будет блокировать объекты. Поэтому никогда не следует на это полагаться.
Хотя и существуют два способа запретить эскалацию:
Способ первый, «почти хакерский». Если мы хотим, чтобы на определенной таблице никогда не происходило эскалации блокировок, то необходимо выполнить нижеприведенный запрос в отдельной транзакции, но завершить эту транзакцию надо вместе с закрытием приложения.
SELECT * FROM <таблица_без_эскалаций> WITH(UPDLOCK)WHERE 1 = 0
|
Такой, на первый взгляд бессмысленный запрос, вызовет наложение IX блокировки на таблицу. Эта блокировка не совместима ни с S, ни с U, ни, тем более, с X блокировками. Таким образом, из-за невозможности наложить блокировку на таблицу эскалация на нее не пройдет. Однако другие запросы, с блокировками меньшей гранулярности, пройдут, в общем-то, без проблем. Единственный побочный эффект заключается в том, что будет невозможно даже явно наложить блокировку на эту таблицу целиком.
Способ второй, «официальный». Можно также, не используя хитрых обходных приемов, запретить эскалацию вообще, даже не в отдельной базе, а целиком в отдельно взятом экземпляре (instance) SQL Server’а. Для этого существует специальный флаг трассировки - 1211. Выполнение команды DBCC TRACEON(1211), запретит эскалацию в отдельном экземпляре всерьез и надолго, до следующей команды DBCC TRACEOFF(1211).
Но, несмотря на возможность, пользуясь полулегальными и вполне документированными способами, запретить эскалацию блокировок, я бы очень не рекомендовал поступать подобным образом. Эскалация – это хорошо отлаженный внутренний механизм сервера, помогающий добиваться максимальной производительности даже при тяжелой нагрузке. И лезть в этот механизм руками без крайней на то необходимости не рекомендуется.
Можно так же попытаться разбить длинную транзакцию на множество мелких, что, в общем-то, всегда полезно, даже если не принимать во внимание эскалацию, так как в большинстве случаев это только на пользу серверу. Да и в целом, чем оптимальнее написаны транзакции и запросы, тем меньше риск эскалации блокировок. Но, я опять повторюсь, никогда нельзя быть уверенным, что эскалация не произойдет. С другой стороны, как правило, эскалация блокировки это звоночек о том, что в приложении есть узкое место и его неплохо бы переписать оптимальнее.
Если же для каких-либо случаев необходимо быть уверенным, что будет заблокирован только один объект или надо блокировать абстрактные объекты типа «документ», то для этого существуют пользовательские блокировки, работать с которыми можно через пару системных хранимых процедур, sp_getapplock и sp_releaseapplock. С помощью этих процедур сервер предоставляет возможность сторонним приложениям пользоваться менеджером блокировок сервера в своих нуждах. Реализовывать же собственный механизм блокировок – занятие хлопотное и, вследствие эскалации, малоперспективное.
sp_getapplock: http://msdn.microsoft.com/library/en-us/tsqlref/ts_sp_ga-gz_5gh5.asp
sp_releaseapplock: http://msdn.microsoft.com/library/en-us/tsqlref/ts_sp_ra-rz_9p2h.asp
sp_indexoption: http://msdn.microsoft.com/library/en-us/tsqlref/ts_sp_ia-iz_5t7y.asp
Locking hints: http://msdn.microsoft.com/library/en-us/acdata/ac_8_con_7a_1hf7.asp
Resolving Blocking Problems That Are Caused by Lock Escalation in SQL Server: http://support.microsoft.com/default.aspx?scid=kb;en-us;323630
[1] Concurrency control and recovery in database systems. Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman.
[2] Inside Microsoft SQL Server 2000. Kalen Delaney
| Оценка 561 Оценить
|