 Оценка 405
Оценка 405 
 Оценить
Оценить 





| Оценка 405 Оценить
|
Как моделировать иерархии в реляционных БД? На этот вопрос, как правило, способны ответить даже начинающие специалисты. Нужно добавить в таблицу столбец, который будет хранить значение первичного ключа родительской строки. Будем называть такой подход "Parent/Child". Хранить иерархии в таком виде очень удобно, а вот обрабатывать – не очень. С появлением в SQL Server 2005 рекурсивных CTE, работать с иерархиями стало намного проще. Задачи, которые раньше невозможно было решить без циклов, теперь легко укладываются в один небольшой запрос. Эффективность и читабельность такого кода значительно выросла. Казалось бы, проблема решена. Но нет, оказывается, есть и другие подходы к решению таких задачи, причем во многих случаях гораздо более эффективные.
В SQL Server 2005 появилась поддержка типа данных XML (надо сказать, что некоторая поддержка XML присутствовала еще в SQL Server 2000, но она в основном сводилась к экспорту реляционных данных в XML и обратно). Тип данных XML в SQL Server 2005 позволил не только хранить XML-данные в базе данных, но, что самое главное, эффективно с ними работать, то есть быстро находить и извлекать информацию, хранящуюся внутри XML документов, а также вносить в них изменения. Тип данных XML – еще один способ хранить иерархии в базе данных. Конечно, далеко не для всех случаев он подходит (правильнее было бы сказать, что подходит он для решения очень узкого круга задач). Microsoft (в BOL) рекомендует ограничиться только следующими сценариями:
Для того чтобы не выполнять парсинг XML-документа каждый раз, когда требуется в нем что-то найти, предназначен первичный XML-индекс. При создании такого индекса XML-документ сохраняется в базе данных в удобном реляционном виде, что потом позволяет гораздо эффективнее выполнять поиск по нему . Чтобы представить иерархию элементов, в этом индексе используется ORDPATH-схема (ORDPATH – hierarchical labeling scheme). Такой подход оказался в данном случае более эффективен, чем традиционный "Parent/Child".
Опыт использования ORDPATH-схемы для поддержки типа данных XML, видимо, сочли успешным, и теперь нам предоставлена возможность применить этот подход для реализации любых других иерархий. Для этого в SQL Server 2008 добавили новый тип данных, который реализует ORDPATH. Он называется HierarchyId.
Значение типа HierarchyId – это описание положения узла в иерархии. Другими словами, значение типа HierarchyId содержит список номеров всех узлов, которые нужно пройти, от корня иерархии до заданного узла. Уровни предлагается разделять символом "/". Номер каждого отдельного узла представляет собой набор числовых значений, разделенных точкой (в самом простом случае это одно число, подробнее о точках и других деталях будет сказано ниже). Давайте посмотрим на примеры корректных значений типа HierarchyId:
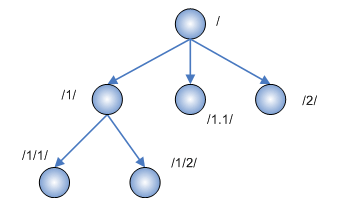
Рисунок 1.
Представленная выше форма записи HierarchyId значений является логической. Так HierarchyId значения преобразуются в символьные типы и обратно. В бинарном виде значения типа HierarchyId хранятся очень компактно.
Что же такого замечательного в этой схеме присвоения кодов узлам (ORDPATH-схеме)?
Прежде чем разбираться с тем, как формируются новые коды узлов при добавлении их в иерархию, давайте создадим тестовую табличку, которая будет хранить нашу иерархию:
CREATE TABLE dbo.HierarchyTable ( RowId HierarchyId not null primary key, Label varchar(100) not null, _Level as RowId.GetLevel() -- Для breadth-first индекса ) |
Код корневого узла иерархии может быть получен с помощью метода GetRoot() типа HierarchyId:
DECLARE @Root HierarchyId SET @Root = HierarchyId::GetRoot() INSERT dbo.HierarchyTable OUTPUT INSERTED.RowId, INSERTED.RowId.ToString() AS RowId_ToString, INSERTED.Label VALUES (@Root, 'Корень') |
Результат:

Для генерации кодов дочерних узлов предназначен метод GetDescendant. У него есть два параметра, определяющих, между какими двумя узлами следует поместить новый узел (любой из параметров может быть равен null). Если это первый дочерний узел, то оба этих параметра должны быть равны null:
DECLARE @Child_1 HierarchyId SET @Child_1 = @Root.GetDescendant(null, null) DECLARE @Child_1_1 HierarchyId SET @Child_1_1 = @Child_1.GetDescendant(null, null) INSERT dbo.HierarchyTable OUTPUT INSERTED.RowId, INSERTED.RowId.ToString() AS RowId_ToString, INSERTED.Label VALUES (@Child_1, 'Строка 1'), (@Child_1_1, 'Строка 1->1') |
Результат:
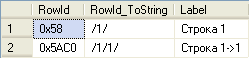
В отличие от схемы Parent/Child, добавление первого и последующих узлов выполняется по-разному. Действительно, если мы два раза выполним метод GetDescendant без параметров (а точнее передадим null в оба параметра) для одного родителя, то получим два одинаковых значения. А значения HierarchyId должны уникально идентифицировать узел в рамках иерархии. Поэтому новый дочерний узел надо добавлять до первого существующего дочернего узла, после последнего или между двумя соседними существующими дочерними узлами.
DECLARE @Child_2 HierarchyId SET @Child_2 = @Root.GetDescendant(@Child_1, null) DECLARE @Child_12 HierarchyId SET @Child_12 = @Root.GetDescendant(@Child_1, @Child_2) INSERT dbo.HierarchyTable OUTPUT INSERTED.RowId, INSERTED.RowId.ToString() AS RowId_ToString, INSERTED.Label VALUES (@Child_2, 'Строка 2'), (@Child_12, 'Строка 1><2') |
Результат:
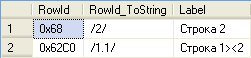
Давайте более подробно рассмотрим, как формируется код нового узла. Если мы хотим поместить новый узел перед первым или после последнего существующего узла, то новый код формируется из базового (относительно которого мы позиционируем новый узел) добавлением или вычитанием единицы из номера узла на листовом (последнем) уровне. Так, в примере выше, из номера узла /1/ получается следующий за ним номер узла /2/ (а, например, из номера /-1.5.3/3/5/6.3/ получился бы номер /-1.5.3/3/5/7/). Если мы хотим добавить новый узел между двумя существующими, то все немного хитрее. Как, например, впихнуть новый узел между /1/ и /2/? Очень просто: за основу берется код узла слева, и добавляется новый компонент номера узла, равный 1. То есть, в нашем случае, код нового узла будет равен /1.1/ (/1/ < /1.1/ < /2/).
Что будет, если отсортировать таблицу (выборку) по столбцу HierarchyId? Мы получим "правильное" линейное представление иерархии в привычном для нас виде. Например, давайте выполним следующий запрос:
SELECT RowId, RowId.ToString() AS RowId_ToString, RowId.GetLevel() AS RowId_GetLevel, Space(3 * RowId.GetLevel()) + Label AS Label FROM dbo.HierarchyTable ORDER BY RowId |
Результат:
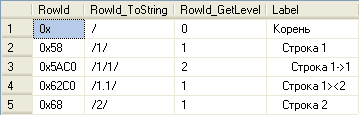
Свойство значений HierarchyId (выстраиваться в "правильном" порядке) является очень существенным аргументом в пользу использования этого подхода. Достаточно часто требуется получить иерархию именно в таком виде (например, для отчетов). Чтобы добиться этого от Parent/Child, приходится использовать рекурсивные CTE или другие такие же ресурсоемкие методы.
Для того, чтобы узнать, является ли некоторый узел дочерним (любого уровня) по отношению к другому узлу, предназначен метод IsDescendant типа HierarchyId. Соответственно, запрос, который отбирает все дочерние узлы некоторого узла с кодом @ParentId, будет иметь следующий вид:
SELECT RowId FROM dbo.HierarchyTable WHERE @ParentId.IsDescendant(RowId) = 1 |
Посмотрев на этот запрос, многие скажут, что он очень плох с точки зрения эффективности. Он приведет к сканированию всей таблицы (Table/Index Scan). А вот и нет!
Чтобы этот запрос работал эффективно, должен существовать индекс по колонке RowId. Такой индекс в BOL называется "depth-first" ("сначала в глубину"). Откуда взялось такое название, понятно из схемы обхода узлов при такой сортировке, приведенной на рисунке 2. Если нужный индекс есть, то SQL-сервер преобразует вышеприведенный запрос к следующему виду:
SELECT RowId FROM dbo.HierarchyTable WHERE RowId >= @ParentId And RowId <= @ParentId.DescendantLimit() |
В таком виде запрос выполняется очень эффективно (Index Seek). Метод DescendantLimit типа HierarchyId возвращает максимальный код, который может иметь дочерний узел заданного родительского узла. Этот метод объявлен как скрытый (private), так что вызвать его непосредственно из T-SQL нельзя.
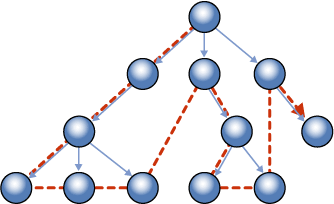
Рисунок 2.
Для этого типа выборок используется еще один метод типа HierarchyId - GetAncestor. Он возвращает код родительского узла. У этого метода есть числовой параметр, указывающий какого уровня родителя мы хотим получить (1 - непосредственный родитель). Итак, запрос выбирающий непосредственных потомков узла с кодом @ParentId будет иметь следующий вид:
SELECT RowId FROM dbo.HierarchyTable WHERE RowId.GetAncestor(1) = @ParentId |
Как и в предыдущем случае, выполнение этого запроса "в лоб" приведет к сканированию таблицы, что конечно же очень не эффективно. Для оптимизации работы этого запроса должен быть создан индекс по RowId.GetLevel(), RowId. Этот индекс в BOL называется "breadth-first" ("сначала в ширину"). Порядок обхода узлов в таком индексе приведен на рисунке 3. Если нужный индекс есть, то SQL Server, как и в предыдущем случае, преобразует вышеприведенный запрос к следующему виду:
SELECT RowId FROM dbo.HierarchyTable WHERE RowId.GetLevel() = @ParentId.GetLevel() + 1 And RowId >= @ParentId And RowId <= @ParentId.DescendantLimit() |
В таком виде запрос выполнится максимально эффективно.
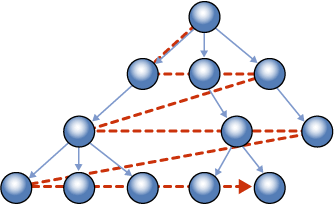
Рисунок 3.
Основным преимуществом построения иерархий на основе ORDPATH-схемы по сравнению с Parent/Child подходом является возможность избавиться от циклов и рекурсивных CTE при выполнении подавляющего большинства стандартных запросов по иерархически организованным данным. Таким образом, эффективность большинства запросов для ORDPATH схемы должна быть выше, чем для Parent/Child.
Недостатки у ORDPATH схемы тоже есть. Основные из них перечислены в следующем списке:
В первой части я рассказал о новом типе данных в SQL Server 2008 – HierarchyId, для чего он нужен, и как его можно использовать. Единственная незатронутая тема, заслуживающая, на мой взгляд, внимания – это физический формат хранения значений этого типа. Почему это важно? Потому что, в отличие от простого идентификатора, HierarchyId-значения содержат список номеров всех узлов, которые нужно пройти, от корня иерархии до заданного узла. А каждый номер узла может состоять из нескольких компонентов (чисел). То есть для больших иерархий HierarchyId значения могут быть достаточно длинными (принятое в SQL Server 2008 ограничение – 892 байт). Учитывая, что по этим значениям наверняка будут строиться индексы и выполняться многочисленные выборки, то чем они будут компактнее, тем лучше.
Таблица 1.
| Код диапазона | Первый байт От | Первый байт До | Диапазон значений От | Диапазон значений До | Длина (бит) - Значения | Длина (бит) - Всего |
|---|---|---|---|---|---|---|
| 000100 | 10 | 13 | -281 479 271 682 120 | -4 294 971 465 | 53 | 60 |
| 000101 | 14 | 17 | -4 294 971 464 | -4 169 | 36 | 43 |
| 000110 | 18 | 1B | -4 168 | -73 | 15 | 22 |
| 0010 | 20 | 2F | -72 | -9 | 8 | 13 |
| 00111 | 38 | 3F | -8 | -1 | 3 | 9 |
| 01 | 40 | 7F | 0 | 3 | 2 | 5 |
| 100 | 80 | 9F | 4 | 7 | 2 | 6 |
| 101 | A0 | BF | 8 | 15 | 3 | 7 |
| 110 | C0 | DF | 16 | 79 | 8 | 12 |
| 1110 | E0 | EF | 80 | 1 103 | 13 | 18 |
| 11110 | F0 | F7 | 1 104 | 5 199 | 15 | 21 |
| 111110 | F8 | FB | 5 200 | 4 294 972 495 | 36 | 43 |
| 111111 | FC | FF | 4 294 972 496 | 281 479 271 683 151 | 53 | 60 |
Напомню, что в логической (текстовой) форме HierarchyId-значения представляют собой список номеров всех узлов по пути от корня иерархии до некоторого заданного узла, разделенных символом «/». Каждый номер узла состоит из одного или нескольких компонентов (чисел), разделенных символом «.» (точка). Пример корректных HierarchyId-значений:
Физическая кодировка HierarchyId значений, очевидно, должна удовлетворять следующим требованиям:
В SQL Server 2008 HierarchyId-значения кодируются с использованием следующей схемы:
<Компонент номера узла 1><Битовый флаг перехода на следующий уровень 1> <Компонент номера узла 2><Битовый флаг перехода на следующий уровень 2> … <Компонент номера узла N><Битовый флаг перехода на следующий уровень N> |
То есть, например, значение /7/4.5/ кодируется согласно этой схеме так:
<7> /* Компонент номера узла */ <1> /* переход на следующий уровень */ <4> /* Компонент номера узла */ <0> /* нет перехода на следующий уровень */ <5> /* Компонент номера узла */ <1> /* переход на следующий уровень */ |
Пока все достаточно очевидно. Самое интересное – это способ кодирования компонентов номеров узлов. Для этого в SQL Server 2008 применен подход, похожий на тот, который используют архиваторы при сжатии данных. Отдельные компоненты номеров узлов кодируются битовыми последовательностями разной длины. Более вероятным значениям соответствуют более короткие битовые последовательности, а менее вероятным – более длинные последовательности.
Каждый компонент номера узла состоит из двух частей – кода диапазона и собственно значения. В таблице 1 представлены все используемые SQL-сервером диапазоны. Например, если требуется закодировать значение 11, то, согласно таблице, будет использован диапазон 8–15 и, соответственно, двоичное представление этого компонента будет равно:
101 /* код диапазона 8-15 */
011 /* значение, пересчитанное на начало диапазона (11 – 8 = 3) */
Согласно электронной документации по SQL Server 2008 (BOL), среднее количество бит, требуемых для представления узла в иерархии с N узлами и небольшим (в диапазоне 0-7) средним количеством дочерних узлов A (fanout), будет равно 6*logAN. То есть для иерархии из 100,000 элементов и средним количеством дочерних узлов равным 6, для кода узла потребуется примерно 38 бит или, после округления, 5 байт.
Очевидно, что битовые последовательности, кодирующие HierarchyId-значения, имеет переменную длину. Причем их длина совсем не обязательно будет кратна восьми битам (границам байт). Так как же определить длину HierarchyId-значения? Битовый флаг перехода на новый уровень в последнем компоненте последнего номера узла всегда равен единице. Дальше битовая последовательность дополняется нулями до границы байта. Соответственно, чтобы найти истинную длину HierarchyId-значения в битах, нужно просто найти первый равный единице бит справа в последнем байте – это и есть конец последовательности.
Давайте вспомним о требовании «правильной» сортировки HierarchyId значений. Согласно этому требованию, например, значение /1/ должно быть меньше значения /1.1/. Но если закодировать эти значения так:
/1/ <1> /* номер */ <1> /* битовый флаг */ /1.1/ <1> /* номер */ <0> /* битовый флаг */ <1> /* номер */ <1> /* битовый флаг */ |
то это условие выполнено не будет, так как первые компоненты номеров узлов равны, а дальше в первом значении идет единица, а во втором – ноль (флаг перехода на новый уровень). Получается, что второе значение меньше первого, а это неправильно. Чтобы решить эту проблему значения всех не последних в своем уровне компонентов номеров узлов имеют значения на единицу больше. То есть наши значения будут закодированы следующим образом:
/1/ <1> /* номер */ <1> /* битовый флаг */ /1.1/ <2> /* номер */ <0> /* битовый флаг */ <1> /* номер */ <1> /* битовый флаг */ |
Итак, давайте собирать все воедино. Попробуем закодировать какое-нибудь значение, а затем сравним наш результат с тем, что вернет SQL-сервер. Пусть это будет значение /5.11/3/
<6> /* номер 5 + 1 */ <0> /* битовый флаг */ // /* номер */ <1> /* битовый флаг */ <3> /* номер */ <1> /* битовый флаг */ |
6 /* диапазон 4-7 */ -> 100 /* код диапазона*/ 10 /* значение 6 - 4 = 2 */ 11 /* диапазон 8-15 */ -> 101 /* код диапазона */ 011 /* значение 11 - 8 = 3 */ 3 /* диапазон 0-3 */ -> 01 /* код диапазона */ 11 /* значение 3 - 0 = 3 */ |
100 10 0 101 011 1 01 11 1 |
или
1001 0010 1011 1011 1100 0000 92 BB C0 |
SELECT Convert(HierarchyId, '/5.11/3/') |
Результат:

Что и требовалось доказать.
| Оценка 405 Оценить
|
