 Оценка 240
Оценка 240 
 Оценить
Оценить 





| Оценка 240 Оценить
|
В сети можно найти достаточное количество материалов, посвященных сравнению производительности кода, сгенерированного различными компиляторами С++ на различных аппаратных платформах для определенного сорта тестовых задач (например обзор на сайте coyote gulch, [1]). Такие материалы выпускают и производители компиляторов, стараясь привлечь внимание к своим продуктам. Нет никаких сомнений в полезности подобных работ – они позволяют учитывать фактор абсолютной производительности сгенерированного кода при выборе инструмента разработки.
Однако на этапе, когда выбор компилятора уже сделан, перед разработчиком довольно часто встает вопрос о выборе в пользу того или иного подхода к реализации конкретных фрагментов программного обеспечения. Поскольку компиляторы C++ с успехом справляются и с кодом С, то всегда есть выбор – воспользоваться новыми языковыми конструкциями, предлагаемыми C++, или реализовать ту же функциональность средствами C. Другими словами возникает вопрос о накладных расходах, вносимых использованием новых языковых средств, или насколько хорошо реализован соответствующий механизм C++ в конкретном компиляторе.
Сравнений производительности кода на C++ и эквивалентного ему по функциональности кода на C, сгенерированных одним и тем же компилятором, не так много. Хорошо известен фактически только один источник – это Technical Report on C++ Performance комитета WG21 (см. [2]). В отчете приведены конкретные результаты и код, на котором производилось сравнение, однако исследуемые компиляторы остаются анонимами. Понять комитет по стандартизации можно, однако практикующим инженерам нужны более точные сведения.
За основу статьи взят материал упомянутого выше отчета. Набор тестов был немного расширен, в некоторых случаях предложенный код модифицирован, а также приведен более подробный анализ возникающих накладных расходов. В большинстве случаев приведены конкретные результаты для конкретных пар компилятор – платформа. В результате читатель сможет получить ответ не только на вопрос «чем я плачу за использование этой языковой конструкции?», но и на вопрос «сколько именно я плачу?».
В таблице ниже представлены протестированные аппаратные платформы, компиляторы и операционные системы.
| Аппаратная платформа | Компиляторы | Операционная система |
|---|---|---|
| Intel, 32 бита | gcc 2.95.3, gcc 3.3.4, gcc 4.1.1, Intel C++ compiler 9.1.038 | Linux |
| Intel, 64 бита | gcc 2.96, gcc 3.3.4, gcc 4.1.1, Intel C++ compiler 9.1.038 | Linux |
| ARM11, 32 бита | gcc 3.4.3 (кросскомпилятор) | Linux |
| Sun UltraSPARC-II, 64 бита | gcc 2.95.3, gcc 3.3.4, gcc 4.1.1 | Sun OS |
Один и тот же компилятор (многоплатформенный) может потенциально показать совершенно разные результаты производительности сгенерированного кода на различной аппаратуре. Результат сильно зависит от блоков кодогенерации и оптимизации для конкретной аппаратуры, поэтому один и тот же компилятор, по возможности, тестировался на разной аппаратуре.
Стоит сказать, что при разработке исходного кода тестов и окружения для их запуска прилагались усилия для сокращения требований к программному обеспечению, доступному на конкретном компьютере, и облегчению процесса добавления нового компилятора в число тестируемых. Фактически, главное требование – это наличие утилиты make. Конкретно использовались GNU-версия make, awk и bash в качестве интерпретатора команд.
Компилятор gcc серии 2 включен в список тестируемых для того, чтобы иметь возможность проследить развитие компиляторов gcc. Несмотря на то, что эта версия все еще используется, скорее это относится к языку C, чем к C++. Как только речь заходит о C++-проектах, то многие разработчики предпочитают использовать более свежие версии компилятора gcc.
Версия компилятора gcc серии 2 на платформе IA-64 отличается от версий компилятора этой же серии на других платформах. Это связано с проблемами установки gcc 2.95.3 на платформе IA-64: скрипт установки не поддерживает эту платформу. Однако поставщиком Linux предоставлялся компилятор gcc версии 2.96. Именно эта версия и использовалась для тестов на платформе IA-64.
В большинстве случаев использовалась следующая схема оценки результатов:
Таким образом, число в ячейке таблицы интерпретируется как выигрыш кода на C++, если число больше 100, и проигрыш кода на C++, если число меньше 100. В тех случаях, когда способ оценки языковых механизмов отличается от описанного выше, в соответствующих местах дается отдельное описание.
Можно выделить три типа накладных расходов, которые могут возникать в связи с использованием C++ вместо C:
Для современных систем память, как оперативная, так и дисковая, перестает быть очень дорогим ресурсом для всё более и более широкого класса задач. Поэтому самым интересным остается вопрос о производительности сгенерированного кода. Накладные расходы времени компиляции часто нивелируются тем, что используется кросс-компиляция на мощных компьютерах. По крайней мере, имеются различные пути для устранения проблем, связанных с накладными расходами времени компиляции.
В связи с вышесказанным, основное внимание уделяется производительности сгенерированного кода, а сведения о размерах исполняемых файлов будут приводиться скорее в справочных целях.
К таким конструкциям относятся пространства имен и явные приведения типов.
Что касается пространств имен, то, строго говоря, они могут внести накладные расходы в виде увеличения времени компиляции. Однако это увеличение пренебрежимо мало, чтобы о нем говорить серьезно.
Для приведения типов C++ предоставляет четыре новые конструкции: static_cast, const_cast, reinterpret_cast и dynamic_cast. Первые три конструкции влияют только на стадию компиляции, а dynamic_cast может приводить к накладным расходам времени выполнения. Эти накладные расходы связаны с обращением к информации о типах времени выполнения (RTTI) и будут обсуждаться далее в главе, посвященной RTTI.
Александр Степанов, изобретатель STL, разработал набор тестов для оценки накладных расходов, связанных с введением дополнительных уровней абстракции. В тесте последовательно оценивается время выполнения семантически одинаковых действий тринадцатью различными способами. В качестве задачи выбрано вычисление суммы значений массива из 2000 величин типа double. Для введения дополнительных уровней абстракции используется обертка вокруг double-значения.
struct Double
{
double value;
Double() {}
Double( constdouble & x ) : value( x ) {}
operatordouble() { return value; }
};
double data[ 2000 ];
Double Data[ 2000 ];
|
Аналогичным образом вводятся обертки double_pointer и Double_pointer для указателей на double и на Double. Вычисление суммы производится следующими способами:
0. for ( size_t i = 0; i < 2000; ++i ) result += data[ i ]; 1. accumulate( data, data + 2000, 0 ); 2. accumulate( Data, Data + 2000, Double( 0 ) ); 3. accumulate( double_pointer( data ), double_pointer( data + 2000 ), 0 ); 4. accumulate( Double_pointer( Data ), Double_pointer( Data + 2000 ), 0 ); 5. Используя reverse_iterator< double *, double > 6. Используя reverse_iterator< Double *, Double > 7. Используя reverse_iterator< double_pointer, double > 8. Используя reverse_iterator< Double_pointer, Double > 9. Используя reverse_iterator< reverse_iterator< double *, double >, double > 10. Используя reverse_iterator< reverse_iterator< Double *, Double >, Double > 11. Используя reverse_iterator< reverse_iterator< double_pointer, double >, double > 12. Используя reverse_iterator< reverse_iterator< Double_pointer, Double >, Double > |
С каждым новым способом вычисления уровень абстракции повышается. Время вычисления каждого способа соотносится со временем вычисления по способу 0, а накладные расходы дополнительных уровней абстракции вычисляются как среднее геометрическое полученных соотношений:
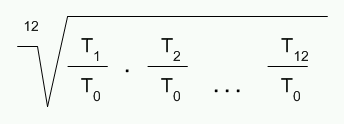
Рисунок 1. Среднее геометрическое соотношений времени вычисления суммы чисел с плавающей точкой
Результирующий коэффициент характеризует качество оптимизации компилятора – чем он меньше, тем лучше компилятор справляется с накладными расходами, связанными с дополнительными уровнями абстракции. Значения больше единицы означают проигрыш в быстродействии с введением дополнительных уровней абстракции.
В таблицах ниже приведены полученные результаты.
| Оптимизация | gcc 2.95 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|
| -O0 | 11.78 | 8.5 | 9.16 | 12.12 |
| -O2 | 1.07 | 1.14 | 1.03 | 1.06 |
| -O3 -fomit-frame-pointer | 1.06 | 1.12 | 1.03 | 1.06 |
| Оптимизация | gcc 2.96 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|
| -O0 | 2.1 | 4.68 | 4.26 | 3.51 |
| -O2 | 1.18 | 0.94 | 1.11 | 0.99 |
| -O3 -fomit-frame-pointer | 1.18 | 0.94 | 1.05 | 2.04 |
| Оптимизация | gcc 2.95 | gcc 3.3 | gcc 4.1 |
|---|---|---|---|
| -O0 | 5.43 | 7.79 | 7.42 |
| -O2 | 0.53 | 1.25 | 1.12 |
| -O3 -fomit-frame-pointer | 0.53 | 1.25 | 1 |
| Оптимизация | gcc 3.4 |
|---|---|
| -O0 | 5.32 |
| -O2 | 0.76 |
| -O3 –fomit-frame-pointer | 0.76 |
Дополнительный ключ оптимизации -fomit-frame-pointer введен для того, чтобы дать компилятору возможность как можно эффективнее использовать имеющиеся регистры процессора.
Результаты показывают, что при включении оптимизации современные компиляторы хорошо справляются с устранением накладных расходов, возникающих при введении дополнительных уровней абстракции. Неожиданные результаты продемонстрировал компилятор gcc серии 3 на платформе IA-64 и ARM. При анализе “в лоб” получается, что с ростом уровня абстракции повышается и производительность. Скорее всего, полученный результат связан с тем, как был сгенерирован код для C-версии, то есть для способа 0. Компилятор компании Intel также продемонстрировал неожиданный результат – на платформе IA-64 при усиленной оптимизации возросли накладные расходы. При детальном анализе выяснилось, что в этом случае чрезвычайно выросла производительность кода C, а производительность кода C++ осталась без изменений.
Однако общая картина остается радужной для современных компиляторов C++. Сгенерированный код практически не уступает по производительности функциональному эквиваленту C.
В некоторых случаях дополнительные уровни абстракции могут дать преимущества коду на C++ перед кодом на C. Это относится, например, к случаю использования функторов вместо указателей на функции. При вызове функции qsort ей необходимо передать указатель на функцию, предоставляющую способ сравнения элементов. Для C++ варианта можно воспользоваться стандартным алгоритмом std::sort, передавая ему различные варианты способов сравнений элементов.
В таблицах ниже приведены результаты сравнения производительности сортировки.
| Оптимизация | Контейнер | Способ сравнения | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|---|
| -O0 | массив | указатель на функцию | 187 | 191 | 135 | 169 |
| standard functor | 178 | 253 | 229 | 184 | ||
| native operator < | 302 | 375 | 317 | 274 | ||
| std::vector | указатель на функцию | 187 | 107 | 88 | 84 | |
| standard functor | 178 | 129 | 130 | 84 | ||
| native operator < | 294 | 153 | 147 | 112 | ||
| -O2 | массив | указатель на функцию | 220 | 251 | 315 | 265 |
| standard functor | 460 | 605 | 577 | 706 | ||
| native operator < | 557 | 572 | 611 | 706 | ||
| std::vector | указатель на функцию | 220 | 245 | 305 | 302 | |
| standard functor | 460 | 542 | 577 | 662 | ||
| native operator < | 557 | 572 | 577 | 662 | ||
| -O3 -fomit-frame-pointer | массив | указатель на функцию | 253 | 267 | 360 | 265 |
| standard functor | 520 | 582 | 673 | 706 | ||
| native operator < | 577 | 582 | 631 | 662 | ||
| std::vector | указатель на функцию | 247 | 267 | 348 | 302 | |
| standard functor | 520 | 521 | 631 | 706 | ||
| native operator < | 577 | 550 | 673 | 662 |
| Оптимизация | Контейнер | Способ сравнения | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|---|
| -O0 | массив | указатель на функцию | 93 | 78 | 61 | 50 |
| standard functor | 146 | 116 | 95 | 76 | ||
| native operator < | 158 | 158 | 130 | 140 | ||
| std::vector | указатель на функцию | 93 | 37 | 34 | 28 | |
| standard functor | 146 | 45 | 43 | 38 | ||
| native operator < | 158 | 52 | 48 | 50 | ||
| -O2 | массив | указатель на функцию | 145 | 144 | 147 | 107 |
| standard functor | 187 | 220 | 221 | 179 | ||
| native operator < | 212 | 220 | 220 | 178 | ||
| std::vector | указатель на функцию | 145 | 139 | 146 | 107 | |
| standard functor | 188 | 180 | 200 | 173 | ||
| native operator < | 214 | 180 | 201 | 176 | ||
| -O3 -fomit-frame-pointer | массив | указатель на функцию | 150 | 145 | 154 | 104 |
| standard functor | 190 | 218 | 219 | 176 | ||
| native operator < | 218 | 221 | 219 | 177 | ||
| std::vector | указатель на функцию | 150 | 139 | 152 | 106 | |
| standard functor | 192 | 180 | 220 | 173 | ||
| native operator < | 216 | 180 | 219 | 175 |
| Оптимизация | Контейнер | Способ сравнения | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|---|
| -O0 | массив | указатель на функцию | 74 | 81 | 68 |
| standard functor | 115 | 104 | 94 | ||
| native operator < | 160 | 187 | 179 | ||
| std::vector | указатель на функцию | 73 | 46 | 38 | |
| standard functor | 115 | 49 | 45 | ||
| native operator < | 160 | 63 | 55 | ||
| -O2 | Массив | указатель на функцию | 69 | 63 | 75 |
| standard functor | 232 | 268 | 402 | ||
| native operator < | 291 | 341 | 402 | ||
| std::vector | указатель на функцию | 68 | 63 | 72 | |
| standard functor | 232 | 252 | 353 | ||
| native operator < | 281 | 309 | 368 | ||
| -O3 -fomit-frame-pointer | массив | указатель на функцию | 72 | 63 | 81 |
| standard functor | 309 | 273 | 520 | ||
| native operator < | 334 | 363 | 505 | ||
| std::vector | указатель на функцию | 71 | 63 | 77 | |
| standard functor | 321 | 269 | 491 | ||
| native operator < | 334 | 327 | 505 |
| Оптимизация | Контейнер | Способ сравнения | gcc 3.4, % |
|---|---|---|---|
| -O0 | массив | указатель на функцию | 186 |
| standard functor | 180 | ||
| native operator < | 293 | ||
| std::vector | указатель на функцию | 72 | |
| standard functor | 71 | ||
| native operator < | 86 | ||
| -O2 | Массив | указатель на функцию | 234 |
| standard functor | 371 | ||
| native operator < | 396 | ||
| std::vector | указатель на функцию | 236 | |
| standard functor | 359 | ||
| native operator < | 371 | ||
| -O3 -fomit-frame-pointer | массив | указатель на функцию | 235 |
| standard functor | 369 | ||
| native operator < | 388 | ||
| std::vector | указатель на функцию | 235 | |
| standard functor | 364 | ||
| native operator < | 369 |
Анализ результатов показывает существенный выигрыш в скорости кода C++, который может достигать 600% в отдельных случаях. При этом выигрыш на платформе IA-32 гораздо существеннее выигрыша на других платформах. Скорее всего, это свидетельствует о недостаточной “зрелости” компиляторов для других платформ.
В большинстве случаев использование указателя на функцию в качестве объекта, определяющего порядок сортировки, снижает производительность. Это говорит о том, что в тех случаях, когда есть выбор между использованием функторов и указателей на функции, предпочтительнее использовать функторы.
Стоит отметить, что сортировка с использованием встроенного оператора сравнения (::operator < (…)) почти всегда выполнялась быстрее, чем другие варианты.
Во время выполнения воплощенные шаблоны работают с точно такой же скоростью, что и нешаблонные классы, поэтому накладные расходы времени выполнения будут точно такими же, как уже обсуждалось в главе «накладные расходы, связанные с дополнительными уровнями абстракции».
Во время компиляции, напротив, шаблоны могут внести существенные накладные расходы, связанные со временем компиляции. Кроме того, могут возникнуть накладные расходы дискового пространства, связанные с эффектом «разбухания» кода.
Существуют три основные схемы реализации механизма воплощения шаблонов компиляторами C++:
Работа механизмов воплощения шаблонов может сильно зависеть от схемы сборки приложения или библиотеки. Предположим, что сборка основана на использовании двух классических компонентов – компилятора и компоновщика. Компилятор преобразует исходный код в объектные файлы, которые содержат машинный код и перекрестные ссылки на другие объектные файлы и библиотеки. Компоновщик создает исполняемые программы или библиотеки, соединяя объектные файлы в одно целое, разрешая содержащиеся в них перекрестные ссылки. Компиляторы C и C++ обрабатывают каждую единицу трансляции независимо. В случае шаблонов, при “лобовом” подходе, для каждой единицы трансляции будут воплощены шаблоны невстраиваемых функций. Таким образом, есть шанс, что в нескольких объектных файлах окажутся тела функций с одинаковыми именами. Этап компоновки в таком случае, скорее всего, закончится неуспешно.
Рассмотрим подробнее, как каждая из упомянутых выше схем реализации механизма воплощения решает эту проблему, и какие накладные расходы при этом возникают.
Схема “жадного” воплощения (от английского instantiate - прим.ред.) допускает создание дубликатов в нескольких объектных файлах, однако для таких дубликатов вводятся специальные пометки (например, подлежащие компоновке воплощенные шаблоны). Когда компоновщик обнаруживает помеченные дубликаты, он оставляет только один, отбрасывая остальные. Описанная схема обладает, по крайней мере, следующими недостатками:
Имеются и достоинства:
Таким образом, накладными расходами в случае “жадной” схемы воплощения будут увеличенное время компиляции и компоновки, а также, вероятно, некоторое увеличение размеров объектных файлов и конечного исполняемого файла. Кроме того, есть вероятность получения не самого оптимального кода в качестве конечного.
Эта схема предусматривает создание и поддержку специальной базы данных, совместно используемой при компиляции всех единиц трансляции, имеющих отношение к программе. В нее заносятся сведения об воплощенных специализациях шаблонов, а также о том, от какого элемента исходного кода они зависят. Сами сгенерированные специализации также обычно сохраняются в этой базе данных.
В случае воплощения по запросу нет случаев, когда компилятор выполняет лишнюю работу. Однако, несмотря на простоту схемы, ее реализация наталкивается на следующие трудности:
Основным накладным расходом для схемы воплощения по запросу будет дисковое пространство, занимаемое базой данных специализаций шаблонов.
Существуют различные способы реализации схемы итеративного воплощения шаблонов. Их общей особенностью является использование предварительного компоновщика. Один из вариантов итеративного воплощения реализован в компиляторе компании Comeau Computing. Последовательность выполняемых действий такова:
При первой компиляции воплощение шаблонов не выполняется, однако объектные файлы будут содержать отметки о том, какие шаблоны могли бы быть воплощены. Для каждой единицы трансляции, использующей шаблоны, создается файл запросов воплощения “.ii”.
Этап компоновки перехватывается предварительным компоновщиком. Он просматривает объектные файлы и принимает во внимание ссылки на воплощенные шаблоны, а также ссылки на шаблоны, которые потенциально могли бы быть воплощены.
Если предварительный компоновщик встречает ссылку на еще невоплощенный ни в одном объектном файле шаблон, он ищет объектный файл, который мог бы создать воплощение данной специализации. Когда подходящий файл найден, предварительный компоновщик делает запись в соответствующий “.ii” файл о необходимости создания недостающей специализации.
Для тех единиц трансляции, чьи “.ii” файлы были изменены, предварительный компоновщик снова вызывает компилятор.
Созданный в результате повторного запуска компилятора объектный файл будет расширен результатами компиляции специализаций шаблонов, указанных в “.ii” файле.
Предварительный компоновщик повторяет шаги 3-5 до тех пор, пока не будут обработаны все запросы воплощения.
Наконец, вызывается традиционный компоновщик для полученных объектных файлов.
Одна из вариаций заключается в том, что компилятор хранит отметки о возможных воплощениях не в объектных файлах, а в файлах запросов воплощения, храня в них также информацию о структуре объектного файла.
При использовании описанного подхода время компоновки может существенно увеличиться, по сравнению с другими схемами. Однако, поскольку на предварительном этапе компоновка не выполняется, это является не таким уж катастрофическим. Более того, файлы запросов воплощения могут быть повторно использованы для последующих компоновок, что уменьшает число перекомпиляций.
В тестах с шаблонами собиралась информация о времени компиляции и размерах исполняемого файла с информацией о символах и без таковой. Удаление информации о символах производилось с помощью утилиты strip.
Тестированию подвергались два варианта исходных текстов . Первый вариант создавал 40 экземпляров контейнерных классов std::list, а элементом контейнеров служили указатели на различные типы. Второй вариант создавал 40 экземпляров классов std::list, а элементом контейнеров служил указатель на один и тот же тип. Результаты тестов представлены в таблицах ниже.
| Оптимизация | Вариант исходного текста | Измеряемая величина | gcc 2.95 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|---|---|
| -O2 | 40 разных шаблонов | Время компиляции, сек | 212 | 20 | 3 | 11 |
| Размер до strip, килобайт | 505 | 87 | 10 | 145 | ||
| Размер после strip, килобайт | 222 | 83 | 6 | 109 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 265 | 22 | 1 | 6 | |
| Размер до strip, килобайт | 498 | 80 | 6 | 94 | ||
| Размер после strip, килобайт | 217 | 78 | 4 | 85 | ||
| -O3 -fomit-frame-pointers | 40 разных шаблонов | Время компиляции, сек | 371 | 20 | 3 | 11 |
| Размер до strip, килобайт | 602 | 87 | 8 | 145 | ||
| Размер после strip, килобайт | 320 | 83 | 6 | 109 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 518 | 22 | 2 | 6 | |
| Размер до strip, килобайт | 594 | 80 | 8 | 94 | ||
| Размер после strip, килобайт | 314 | 78 | 6 | 85 | ||
| -Os | 40 разных шаблонов | Время компиляции, сек | 227 | 24 | 4 | 10 |
| Размер до strip, килобайт | 505 | 88 | 29 | 148 | ||
| Размер после strip, килобайт | 222 | 83 | 10 | 105 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 294 | 27 | 1 | 6 | |
| Размер до strip, килобайт | 498 | 81 | 7 | 93 | ||
| Размер после strip, килобайт | 217 | 79 | 5 | 81 |
| Оптимизация | Вариант исходного текста | Измеряемая величина | gcc 2.96 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|---|---|
| -O2 | 40 разных шаблонов | Время компиляции, сек | 40 | 29 | 2 | 7 |
| Размер до strip, килобайт | 375 | 117 | 20 | 308 | ||
| Размер после strip, килобайт | 368 | 112 | 15 | 212 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 34 | 27 | 1 | 3 | |
| Размер до strip, килобайт | 360 | 106 | 11 | 124 | ||
| Размер после strip, килобайт | 356 | 104 | 8 | 116 | ||
| -O3 -fomit-frame-pointers | 40 разных шаблонов | Время компиляции, сек | 40 | 29 | 2 | 7 |
| Размер до strip, килобайт | 375 | 117 | 15 | 308 | ||
| Размер после strip, килобайт | 368 | 112 | 12 | 212 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 35 | 27 | 1 | 3 | |
| Размер до strip, килобайт | 360 | 107 | 15 | 124 | ||
| Размер после strip, килобайт | 356 | 104 | 12 | 116 | ||
| -Os | 40 разных шаблонов | Время компиляции, сек | 33 | 32 | 3 | 7 |
| Размер до strip, килобайт | 375 | 119 | 64 | 320 | ||
| Размер после strip, килобайт | 368 | 113 | 43 | 216 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 56 | 31 | 1 | 3 | |
| Размер до strip, килобайт | 360 | 108 | 13 | 128 | ||
| Размер после strip, килобайт | 356 | 105 | 10 | 116 |
| Оптимизация | Вариант исходного текста | Измеряемая величина | gcc 2.95 | gcc 3.3 | gcc 4.1 |
|---|---|---|---|---|---|
| -O2 | 40 разных шаблонов | Время компиляции, сек | 164 | 98 | 8 |
| Размер до strip, килобайт | 798 | 77 | 19 | ||
| Размер после strip, килобайт | 216 | 71 | 13 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 160 | 90 | 2 | |
| Размер до strip, килобайт | 785 | 64 | 8 | ||
| Размер после strip, килобайт | 206 | 61 | 5 | ||
| -O3 -fomit-frame-pointers | 40 разных шаблонов | Время компиляции, сек | 165 | 99 | 10 |
| Размер до strip, килобайт | 797 | 77 | 10 | ||
| Размер после strip, килобайт | 216 | 71 | 7 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 158 | 92 | 5 | |
| Размер до strip, килобайт | 784 | 64 | 10 | ||
| Размер после strip, килобайт | 205 | 61 | 7 | ||
| -Os | 40 разных шаблонов | Время компиляции, сек | 180 | 108 | 9 |
| Размер до strip, килобайт | 798 | 78 | 62 | ||
| Размер после strip, килобайт | 217 | 72 | 44 | ||
| 40 одинаковых шаблонов | Время компиляции, сек | 173 | 99 | 2 | |
| Размер до strip, килобайт | 785 | 65 | 9 | ||
| Размер после strip, килобайт | 206 | 62 | 6 |
| Оптимизация | Вариант исходного текста | Измеряемая величина | gcc 3.4 |
|---|---|---|---|
| -O2 | 40 разных шаблонов | Размер до strip, килобайт | 20 |
| Размер после strip, килобайт | 8 | ||
| 40 одинаковых шаблонов | Размер до strip, килобайт | 24 | |
| Размер после strip, килобайт | 8 | ||
| -O3 -fomit-frame-pointers | 40 разных шаблонов | Размер до strip, килобайт | 20 |
| Размер после strip, килобайт | 18 | ||
| 40 одинаковых шаблонов | Размер до strip, килобайт | 24 | |
| Размер после strip, килобайт | 18 | ||
| -Os | 40 разных шаблонов | Размер до strip, килобайт | 29 |
| Размер после strip, килобайт | 18 | ||
| 40 одинаковых шаблонов | Размер до strip, килобайт | 24 | |
| Размер после strip, килобайт | 18 |
Интересными результатами здесь является подтверждение факта, что компиляторы сделали значительный шаг вперед в плане уменьшения времени компиляции и уменьшения размера сгенерированного кода. В некоторых случаях время компиляции для gcc сократилось более чем в 100 раз при переходе с серии 2 к серии 4.
Для платформы ARM время компиляции не приводится. Поскольку использовался кросс-компилятор, время полностью зависело от производительности хост-системы (IA-32). Как таковые результаты только для одного компилятора для ARM не представляют существенного интереса, однако таблица приведена с надеждой на добавление новых колонок в будущем.
Вызов функции-члена приблизительно эквивалентен вызову функции с одним дополнительным параметром – указателем на объект. Рассмотрим три варианта, описанные в таблице ниже:
| Описание | Вариант C++ | Вариант C |
|---|---|---|
| Нотация “стрелка” | x->g( i ); | g( ps, i ); |
| Нотация “точка” | x.g( i ); | g( &s, i ); |
| Статическая функция член класса и свободная функция | X::f( i ); | f( i ); |
В тестах сравнивались вызовы функций с целочисленным параметром, который в таблице показан как i. Параметр ps в таблице – указатель, а s – объект.
В таблицах ниже приведены результаты сравнения производительности вызовов C++ и C.
| Оптимизация | Вариант теста | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 102 | 98 | 99 | 98 |
| Нотация “точка” | 101 | 98 | 96 | 101 | |
| Статическая функция-член класса и свободная функция | 105 | 100 | 100 | 100 | |
| -O2 | Нотация “стрелка” | 95 | 87 | 102 | 100 |
| Нотация “точка” | 110 | 90 | 100 | 104 | |
| Статическая функция-член класса и свободная функция | 101 | 100 | 100 | 153 | |
| -O3 –fomit-frame-pointer | Нотация “стрелка” | 106 | 95 | 104 | 90 |
| Нотация “точка” | 111 | 100 | 104 | 104 | |
| Статическая функция-член класса и свободная функция | 100 | 101 | 95 | 160 |
| Оптимизация | Вариант теста | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 81 | 95 | 95 | 100 |
| Нотация “точка” | 81 | 95 | 95 | 99 | |
| Статическая функция-член класса и свободная функция | 96 | 100 | 100 | 100 | |
| -O2 | Нотация “стрелка” | 38 | 270 | 117 | 86 |
| Нотация “точка” | 38 | 243 | 83 | 85 | |
| Статическая функция-член класса и свободная функция | 63 | 100 | 100 | 99 | |
| -O3 –fomit-frame-pointer | Нотация “стрелка” | 37 | 83 | 100 | 85 |
| Нотация “точка” | 36 | 83 | 207 | 85 | |
| Статическая функция-член класса и свободная функция | 63 | 100 | 33 | 100 |
| Оптимизация | Вариант теста | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 114 | 113 | 99 |
| Нотация “точка” | 114 | 85 | 100 | |
| Статическая функция-член класса и свободная функция | 100 | 99 | 99 | |
| -O2 | Нотация “стрелка” | 100 | 102 | 90 |
| Нотация “точка” | 100 | 99 | 87 | |
| Статическая функция-член класса и свободная функция | 92 | 87 | 99 | |
| -O3 –fomit-frame-pointer | Нотация “стрелка” | 99 | 100 | 100 |
| Нотация “точка” | 99 | 89 | 100 | |
| Статическая функция-член класса и свободная функция | 99 | 91 | 100 |
| Оптимизация | Вариант теста | gcc 3.4, % |
|---|---|---|
| -O0 | Нотация “стрелка” | 100 |
| Нотация “точка” | 99 | |
| Статическая функция-член класса и свободная функция | 100 | |
| -O2 | Нотация “стрелка” | 118 |
| Нотация “точка” | 112 | |
| Статическая функция-член класса и свободная функция | 89 | |
| -O3 –fomit-frame-pointer | Нотация “стрелка” | 100 |
| Нотация “точка” | 151 | |
| Статическая функция-член класса и свободная функция | 101 |
Производительность C++ на платформах IA-32, Sun и ARM в большинстве случаев не отличается от производительности C больше чем на 10%. На платформе IA-64 результаты менее ровные. Производительность C++ сильно зависит от конкретного случая и может варьироваться от подавляющего превосходства C++ (gcc серии 4 с максимальной оптимизацией для нотации “точка” – 207%), до сильного проигрыша (gcc серии 4 с максимальной оптимизацией для статических функций членов– 33%).
Виртуальные функции, также как и не виртуальные, могут вызываться с использованием нотаций “точка” и “стрелка”. Поскольку указатели на виртуальные функции хранятся в отдельной таблице, то вызов виртуальной функции будет приблизительно эквивалентен вызову функции с одним дополнительным параметром по указателю, хранящемуся в массиве. В таблице ниже представлены варианты вызовов для C++ и для C.
| Описание | Вариант C++ | Вариант C |
|---|---|---|
| Нотация “стрелка” | x->f( i ); | (p[1])(ps,i); |
| Нотация “точка” | x.f( i ); | (p[1])(&s,i); |
Здесь i – целочисленный параметр, p – массив указателей на функции, ps – указатель на объект, а s – объект.
В таблицах ниже приведены результаты сравнения производительности вызовов C++ и C.
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 92 | 87 | 114 | 91 |
| Нотация “точка” | 104 | 103 | 101 | 105 | |
| -O2 | Нотация “стрелка” | 89 | 92 | 90 | 97 |
| Нотация “точка” | 110 | 106 | 110 | 702 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 97 | 93 | 91 | 97 |
| Нотация “точка” | 122 | 106 | 500 | 702 |
| Оптимизация | Нотация | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 81 | 95 | 95 | 100 |
| Нотация “точка” | 81 | 95 | 95 | 99 | |
| -O2 | Нотация “стрелка” | 96 | 100 | 100 | 100 |
| Нотация “точка” | 38 | 270 | 117 | 86 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 38 | 243 | 83 | 85 |
| Нотация “точка” | 63 | 100 | 100 | 99 |
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 94 | 94 | 95 |
| Нотация “точка” | 158 | 112 | 152 | |
| -O2 | Нотация “стрелка” | 77 | 91 | 95 |
| Нотация “точка” | 224 | 207 | 206 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 81 | 85 | 93 |
| Нотация “точка” | 205 | 225 | 1234 |
| Оптимизация | Нотация | gcc 3.4, % |
|---|---|---|
| -O0 | Нотация “стрелка” | 90 |
| Нотация “точка” | 125 | |
| -O2 | Нотация “стрелка” | 96 |
| Нотация “точка” | 141 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 96 |
| Нотация “точка” | 498 |
Можно заметить, что производительность вызовов с использованием нотации “точка” для С++ почти всегда выигрывает у варианта для С. Иногда выигрыш достигает существенных величин – пяти-семикратного выигрыша С++. Вероятно, это связано с особенностями работы оптимизатора. Для С++, в случае нотации "точка", оптимизатор способен провести девиртуализацию, в то время как для C подобных попыток не делается.
Для нотации “стрелка” наблюдается небольшой выигрыш у C-варианта. Для платформы IA-32 без оптимизации вариант C++ у компилятора gcc серии 4 оказался производительнее. А компилятор компании Intel на платформе IA-64 без оптимизации показал провал производительности варианта C++.
Затраты на вызов виртуальной и невиртуальной функции для C++ могут отличаться. В таблицах ниже приведены результаты сравнения производительности вызовов виртуальных и невиртуальных функций. В ячейках таблиц указан процент производительности вызовов виртуальных функций по отношению к вызовам невиртуальных функций. Соответственно, число больше 100 означает, что вызов виртуальной функции, в среднем, обошелся дешевле вызова невиртуальной функции.
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 80 | 87 | 112 | 92 |
| Нотация “точка” | 99 | 99 | 100 | 101 | |
| -O2 | Нотация “стрелка” | 90 | 85 | 90 | 6 |
| Нотация “точка” | 98 | 100 | 100 | 100 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 81 | 83 | 16 | 6 |
| Нотация “точка” | 100 | 100 | 95 | 100 |
| Оптимизация | Нотация | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 77 | 79 | 77 | 42 |
| Нотация “точка” | 95 | 100 | 100 | 100 | |
| -O2 | Нотация “стрелка” | 150 | 70 | 59 | 77 |
| Нотация “точка” | 258 | 100 | 85 | 526 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 158 | 60 | 13 | 77 |
| Нотация “точка” | 273 | 100 | 100 | 699 |
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 52 | 70 | 64 |
| Нотация “точка” | 99 | 100 | 97 | |
| -O2 | Нотация “стрелка” | 36 | 41 | 46 |
| Нотация “точка” | 100 | 96 | 114 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 38 | 42 | 7 |
| Нотация “точка” | 100 | 111 | 99 |
| Оптимизация | Нотация | gcc 3.4, % |
|---|---|---|
| -O0 | Нотация “стрелка” | 72 |
| Нотация “точка” | 99 | |
| -O2 | Нотация “стрелка” | 64 |
| Нотация “точка” | 93 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 19 |
| Нотация “точка” | 119 |
Тот факт, что для нотации “точка” производительность вызовов виртуальных и невиртуальных функций оказалась приблизительно одинакова, можно объяснить тем, что компилятор смог произвести девиртуализацию вызовов функций.
В случае нотации “стрелка” виртуальные функции проигрывают невиртуальным в подавляющем большинстве случаев. Иногда проигрыш очень существенен – на платформе IA-32 компилятор компании Intel проиграл в 16 раз, а компилятор gcc серии 4 проиграл в 6 раз.
В некоторых ситуациях (например, Sun, gcc 4.1, -O3) сильный проигрыш в производительности вызовов виртуальных функций по сравнению с вызовами невиртуальных функций можно объяснить тем, что компилятор смог произвести встраивание невиртуальной функции и не смог встроить виртуальную функцию.
C++ предлагает альтернативу макросам языка C – встраиваемые функции. В таблицах ниже приведены результаты сравнения производительности этих механизмов для двух вариантов: нотаций “точка” и “стрелка”.
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 64 | 54 | 49 | 47 |
| Нотация “точка” | 31 | 49 | 36 | 35 | |
| -O2 | Нотация “стрелка” | 100 | 123 | 100 | 95 |
| Нотация “точка” | 97 | 98 | 100 | 104 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 97 | 82 | 100 | 100 |
| Нотация “точка” | 102 | 98 | 102 | 102 |
| Оптимизация | Нотация | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 108 | 64 | 74 | 68 |
| Нотация “точка” | 95 | 52 | 58 | 58 | |
| -O2 | Нотация “стрелка” | 101 | 33 | 99 | 33 |
| Нотация “точка” | 446 | 100 | 300 | 299 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 301 | 99 | 300 | 100 |
| Нотация “точка” | 447 | 100 | 33 | 200 |
| Оптимизация | Нотация | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|
| -O0 | Нотация “стрелка” | 63 | 64 | 58 |
| Нотация “точка” | 84 | 44 | 47 | |
| -O2 | Нотация “стрелка” | 99 | 100 | 99 |
| Нотация “точка” | 99 | 100 | 99 | |
| -O3 –fomit-frame-pointer | Нотация “стрелка” | 100 | 99 | 100 |
| Нотация “точка” | 100 | 100 | 100 |
| Оптимизация | Нотация | gcc 3.4, % |
|---|---|---|
| -O0 | Нотация “стрелка” | 48 |
| Нотация “точка” | 38 | |
| -O2 | Нотация “стрелка” | 120 |
| Нотация “точка” | 100 | |
| -O3 -fomit-frame-pointer | Нотация “стрелка” | 101 |
| Нотация “точка” | 83 |
Без включения оптимизации компиляторы, как правило, не пытаются встроить вызовы функций. Первые две строчки в каждой из таблиц подтверждают это предположение.
Результаты при включении оптимизации очень сильно различаются для различных платформ и случаев. Наиболее стабильные результаты показывает компилятор gcc серии 4 на платформе IA-32 – производительность встраиваемых функций и макросов оказалась одинаковой. Компилятор компании Intel демонстрирует провал производительности встраиваемых функций для нотации “стрелка” на платформе IA-32.
На платформе IA-64 возможен как выигрыш в производительности (например, компилятор компании Intel для нотации “точка”), так и существенный проигрыш (например, gcc серии 4 для нотации “точка” и оптимизации -O2).
Компилятор gcc, запущенный с ключом -O0, не производит встраивание функций, поэтому макросы оказываются эффективнее. Включение встраивания функций приводит к тому, что производительность макросов и функций становится примерно одинаковой.
При вызове виртуальных функций могут возникать накладные расходы времени выполнения по сравнению с вызовами обычных функций. При этом возможен расход как времени центрального процессора, так и оперативной памяти. В различных случаях наследования – одиночного и множественного – и даже при различном порядке наследования накладные расходы времени выполнения могут различаться.
Рассмотрим более подробно, что происходит в различных вариантах наследования для типичной реализации.
Предположим, что следующий тип используется в качестве базового (структура используется только для того, чтобы избежать использования ключевого слова public и тем самым сэкономить одну строку):
struct Base
{
Data d1;
virtualvoid f( void );
void g( void );
};
|
Экземпляры типа Base будут располагаться в памяти так, как показано на рисунке 2.
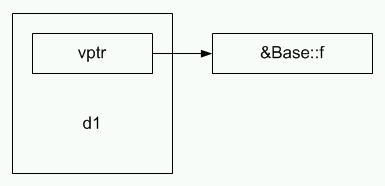
Рисунок 2. Размещение объекта с виртуальной функцией.
В таблице виртуальных функций для типа Base будет один указатель на виртуальную функцию, а данные будут расширены указателем на таблицу виртуальных функций. Какие именно элементы хранятся в таблице виртуальных функций несущественно. Это могут быть указатели, смещения для корректировки указателя this или что-нибудь еще.
Теперь предположим, что имеется тип Derived, наследующий от Base:
struct Derived : public Base
{
Data d2;
virtualvoid f( void );
virtualvoid h( void );
};
|
Размещение объектов типа Derived в памяти представлено на рисунке 3.
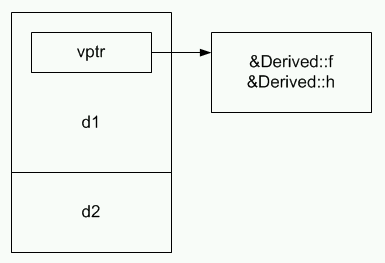
Рисунок 3. Размещение производного объекта с виртуальными функциями.
Данные базового типа будут располагаться в памяти сначала, за ними будут следовать данные производного класса. Таблица виртуальных функций будет расширена еще одним указателем &Derived::h, а указатель &Base::f будет заменен на &Derived::f.
Стоит заметить, что в случае размещения в памяти экземпляра типа Derived (т.е. одиночного наследования), адреса Base- и Derived-частей будут совпадать. Еще одной особенностью является потенциальная возможность хранить один экземпляр таблицы виртуальных функций для всех объектов типа. Это позволяет снизить накладные расходы оперативной памяти времени выполнения и, возможно, занимаемого дискового пространства.
Предположим, что имеются два базовых типа Base1 и Base2:
struct Base1
{
Data d1;
virtualvoid f( void );
};
struct Base2
{
Data d2;
virtualvoid f( void );
virtualvoid g( void );
};
|
Тип DerivedMultilpe наследует от Base1 и Base2:
struct DerivedMultiple : public Base1, public Base2
{
Data d3;
virtualvoid f( void );
virtualvoid g( void );
virtualvoid h( void );
};
|
Размещение объектов типа Base1 и Base2 аналогично размещению объектов типа Base, показанному на рисунке 2. Интерес представляет размещение объектов типа DerivedMultiple:
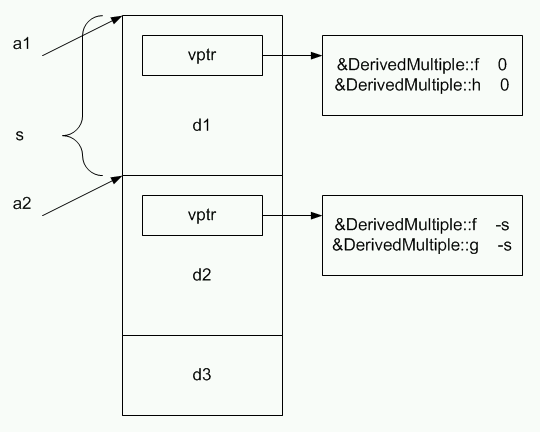
Рисунок 4. Размещения объекта с виртуальными функциями в случае множественного наследования.
На рисунке s означает размер, занимаемый экземпляром типа Base1 в памяти.
В памяти сначала будут располагаться данные базового типа Base1, затем данные базового типа Base2, и только после них – данные DerivedMultiple. Важным моментом здесь является то, что у объекта DerivedMultiple может быть два адреса, на рисунке адреса помечены как a1 и a2. Эти адреса появляются, если разработчик пишет код, подобный следующему:
DerivedMultiple * Object( new DerivedMultiple ); // Соответствует a1 Base1 * base1( Object ); // Также соответствует a1 Base2 * base2( Object ); // Соответствует a2 |
Однако при вызове виртуальной функции f ей необходимо передать правильный указатель this, то есть указатель на реально созданный объект – в нашем случае a1. Для указателя base2 потребуются дополнительные действия: необходимо указатель a2 скорректировать на размер, занимаемый base1, то есть s. В связи с этим в таблицах виртуальных функций на рисунке появился еще один информационный элемент – величина, на которую нужно изменять указатель this при вызове виртуальных функций.
Аналогичная ситуация возникает и при таком способе использования приведенной иерархии типов:
Base2 * base2a( new Base2 ); Base2 * base2b( new DerivedMultiple ); base2a->f(); base2b->f(); |
Здесь указатель Base2 * может указывать либо на объект Base2, либо на часть объекта DerivedMultiple. При вызове виртуальной функции f в первом случае будет вызвана Base2::f, а во втором – DerivedMultiple::f. Так как base2b указывает на подобъект типа DerivedMultiple, то для вызова base2b->f() указатель base2b надо подкорректировать, чтобы он определял объект типа DerivedMultiple. Величина корректировки составит s.
Из приведенного выше описания видно, что при использовании виртуальных функций возникают накладные расходы оперативной памяти на хранение дополнительных сведений и расходы процессорного времени, связанные с анализом этих данных и выполнением дополнительных действий. Механизм встраивания также не будет работать в случае использования виртуальных функций.
Стоит отметить, что довольно часто вызов виртуальной функции производится в контексте, когда у компилятора есть все сведения о типах, необходимые для замены виртуального вызова обычным. Такая оптимизация называется девиртуализацией и позволяет перейти от косвенного вызова через таблицу виртуальных функций к прямому вызову.
Что касается техники, используемой компиляторами для реализации виртуальных функций, то существует, по крайней мере, два подхода. Первый связан с хранением дельты для корректировки указателя this, как показано на рисунках выше. Второй способ подразумевает генерацию небольших фрагментов кода («thunk»), которые корректируют this. В случае отсутствия необходимости в корректировки соответствующий фрагмент получается пустым, чем достигается оптимизация вызовов виртуальных функций.
Как уже было отмечено, затраты на вызовы функций в случае одиночного наследования и множественного наследования могут отличаться. Накладные расходы могут различаться для виртуальных и невиртуальных функций. Также на величину накладных расходов может повлиять порядок наследования. Ниже приведены результаты сравнения производительности всех описанных случаев.
На диаграмме ниже приведены две иерархии типов, использовавшиеся в тестах. Для случая множественного наследования ветвь, относящаяся к базовому классу Base1, в дальнейшем будет именоваться, для краткости, первой ветвью наследования. А ветвь, относящаяся к базовому классу Base2 – второй ветвью наследования.
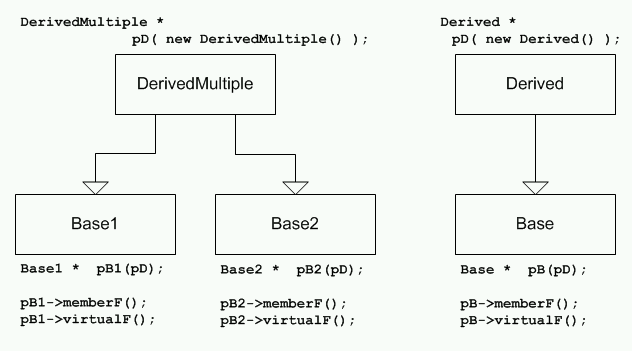
Рисунок 5. Использованные вызовы.
В тесте измеряется производительность вызовов виртуальных и невиртуальных функций в разных схемах наследования. В случае множественного наследования производительность замеряется дважды, для обеих ветвей наследования.
В таблице ниже сравнивается производительность вызовов функций в случае множественного и одиночного наследования. Соответственно число больше 100 означает, что вызов функции при множественном наследовании, в среднем, обошелся дешевле вызова функции при одиночном наследовании.
| Оптимизация | Тип функции | Ветвь наследования | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|---|
| -O0 | Невиртуальная | Base1 | 105 | 103 | 94 | 101 |
| Base2 | 98 | 99 | 94 | 96 | ||
| Виртуальная | Base1 | 100 | 100 | 100 | 99 | |
| Base2 | 88 | 82 | 90 | 61 | ||
| -O2 | Невиртуальная | Base1 | 102 | 102 | 100 | 100 |
| Base2 | 102 | 103 | 104 | 100 | ||
| Виртуальная | Base1 | 100 | 98 | 99 | 99 | |
| Base2 | 78 | 97 | 94 | 99 | ||
| -O3 -fomit-frame-pointer | Невиртуальная | Base1 | 102 | 99 | 102 | 100 |
| Base2 | 102 | 118 | 102 | 100 | ||
| Виртуальная | Base1 | 100 | 99 | 99 | 98 | |
| Base2 | 86 | 69 | 83 | 99 |
| Оптимизация | Тип функции | Ветвь наследования | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|---|
| -O0 | Невиртуальная | Base1 | 103 | 100 | 99 | 100 |
| Base2 | 95 | 92 | 95 | 96 | ||
| Виртуальная | Base1 | 100 | 100 | 99 | 99 | |
| Base2 | 124 | 93 | 96 | 62 | ||
| -O2 | Невиртуальная | Base1 | 36 | 99 | 116 | 100 |
| Base2 | 37 | 99 | 116 | 99 | ||
| Виртуальная | Base1 | 99 | 100 | 99 | 99 | |
| Base2 | 85 | 91 | 90 | 99 | ||
| -O3 -fomit-frame-pointer | Невиртуальная | Base1 | 298 | 100 | 100 | 99 |
| Base2 | 100 | 300 | 33 | 99 | ||
| Виртуальная | Base1 | 100 | 99 | 99 | 99 | |
| Base2 | 86 | 90 | 90 | 100 |
| Оптимизация | Тип функции | Ветвь наследования | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|---|
| -O0 | Невиртуальная | Base1 | 100 | 113 | 100 |
| Base2 | 108 | 94 | 97 | ||
| Виртуальная | Base1 | 88 | 98 | 100 | |
| Base2 | 90 | 82 | 84 | ||
| -O2 | Невиртуальная | Base1 | 99 | 100 | 99 |
| Base2 | 99 | 104 | 91 | ||
| Виртуальная | Base1 | 108 | 94 | 99 | |
| Base2 | 107 | 64 | 97 | ||
| -O3 -fomit-frame-pointer | Невиртуальная | Base1 | 100 | 100 | 100 |
| Base2 | 100 | 100 | 100 | ||
| Виртуальная | Base1 | 97 | 100 | 100 | |
| Base2 | 101 | 70 | 99 |
| Оптимизация | Тип функции | Ветвь наследования | gcc 3.4, % |
|---|---|---|---|
| -O0 | Невиртуальная | Base1 | 100 |
| Base2 | 92 | ||
| Виртуальная | Base1 | 100 | |
| Base2 | 85 | ||
| -O2 | Невиртуальная | Base1 | 77 |
| Base2 | 100 | ||
| Виртуальная | Base1 | 99 | |
| Base2 | 79 | ||
| -O3 -fomit-frame-pointer | Невиртуальная | Base1 | 100 |
| Base2 | 100 | ||
| Виртуальная | Base1 | 99 | |
| Base2 | 79 |
Можно заметить, что у современных компиляторов порядок наследования практически не влияет на производительность вызовов невиртуальных функций. Другая ситуация с виртуальными функциями. При включенной оптимизации для компилятора компании Intel стоимость вызова виртуальной функции не зависела от порядка наследования и оказалась практически равной стоимости вызова виртуальной функции при одиночном наследовании.
Для компиляторов gcc серий 3 и 4 при включенной оптимизации есть небольшая разница в производительности вызовов виртуальных функций для разных ветвей наследования. Потеря производительности вызовов виртуальных функций по второй ветви наследования в сравнении с вызовами виртуальных функций в случае одиночного наследования составляет от 10% до 30%. Такие потери практически отсутствуют для вызовов по первой ветви наследования.
В случае виртуального наследования структуры данных становятся еще более сложными. Рассмотрим пример такой иерархии типов:
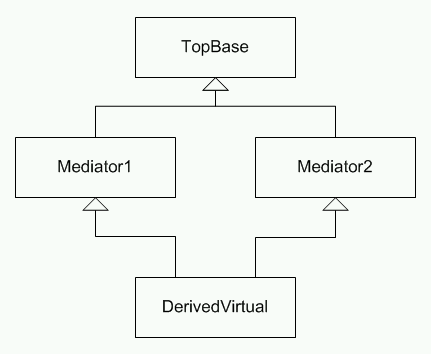
Рисунок 6. Иерархия типов с виртуальным наследованием
Здесь Mediator1 и Mediator2 виртуально наследуют от TopBase. Предположим, что соответствующие типы определены так:
struct TopBase
{
Data d1;
virtualvoid f( void );
};
struct Mediator1 : virtualpublic TopBase
{
Data d2;
virtualvoid f( void );
virtualvoid g( void );
};
struct Mediator2 : virtualpublic TopBase
{
Data d3;
virtualvoid f( void );
virtualvoid h( void );
};
struct DerivedVirtual : public Mediator1, public Mediator2
{
Data d4;
virtualvoid f( void );
virtualvoid g( void );
virtualvoid h( void );
};
|
Объекты типа TopBase будут располагаться в памяти способом, аналогичным представленному на рисунке 2. Расположение в памяти объектов типов Mediator1 и Mediator2 уже будет отличаться. На рисунке ниже приведен способ размещения объектов типа Mediator1 для типичной реализации. Объекты типа Mediator2 будут располагаться аналогичным образом.
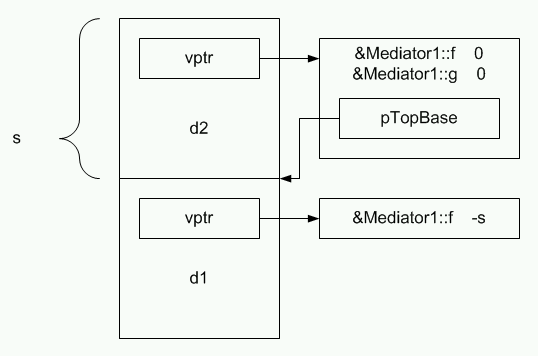
Рисунок 7. Размещение в памяти объекта с виртуальным базовым классом.
Здесь данные виртуального базового класса располагаются после всех остальных данных. Это делается для унификации действий, выполняемых во время выполнения, независимо от того, объекты каких типов были созданы (в примере Mediator1, Mediator2 или DerivedVirtual). Таблица виртуальных функций для Mediator1 расширяется еще одним элементом – указателем на реальное расположение данных виртуального базового класса. При этом доступ к данным виртуального базового класса будет осуществляться не напрямую, а через дополнительный указатель в таблице виртуальных функций. Это приводит к накладным расходам времени выполнения.
На рисунке 8 показано как будут размещаться в памяти объекты типа DerivedVirtual.
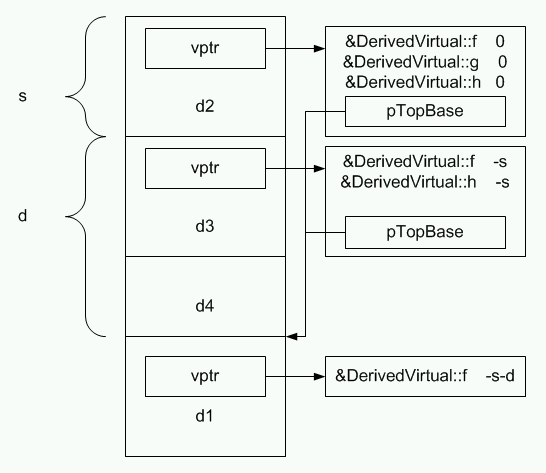
Рисунок 8. Размещение в памяти объекта с виртуальным базовым классом в случае множественного наследования.
Данные виртуального базового типа появляются только один раз при размещении объекта в памяти, поэтому точное их местонахождение известно только тому объекту, который реально создан. В связи с этим указатель на начало данных виртуального базового типа должен быть сохранен в таблицах виртуальных функций наследующих объектов.
Для описанной выше реализации, как в случае создания объектов Mediator1, Mediator2 или DerivedVirtual, доступ к данным виртуального базового типа будет осуществляться одинаково – через дополнительный указатель в таблице виртуальных функций. Это справедливо и для случая, когда создан объект типа DerivedVirtual и указатель на созданный объект преобразован к указателю на Mediator1 или Mediator2.
Некоторые реализации хранят указатель на начало данных виртуального базового типа не в таблице виртуальных функций, а как дополнительный член данных типа.
Использование механизма виртуального наследования может приводить к потере производительности по сравнению с обычным наследованием. Эффект может проявляться при вызовах функций членов или при доступе к данным виртуального базового класса.
Виртуальный базовый класс может иметь как виртуальные, так и невиртуальные функции. Производительность вызовов таких функций из производного класса может различаться.
Результаты тестирования подразделяются на относящиеся к невиртуальным и относящиеся к виртуальным функциям. Для невиртуальных функций приведены результаты сравнения производительности вызовов при виртуальном и одиночном наследовании. Вызов функции при виртуальном наследовании изменял переменную виртуального базового класса, а вызов функции при одиночном наследовании изменял переменную невиртуального базового класса. В таблице с результатами теста вариант вызова, изменяющий одну переменную базового класса, называется «Вариант 1». Для виртуальных функций также приведены результаты сравнения производительности вызовов при виртуальном и одиночном наследовании. Использовались два разных варианта вызова, проиллюстрированные рисунками ниже.
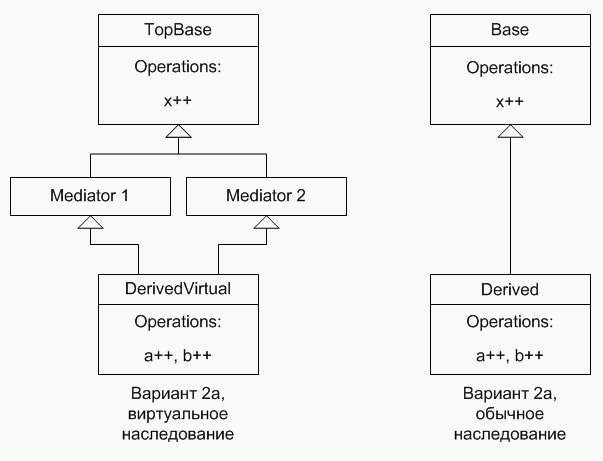
Рисунок 9. Вызов виртуальной функции, вариант 2а
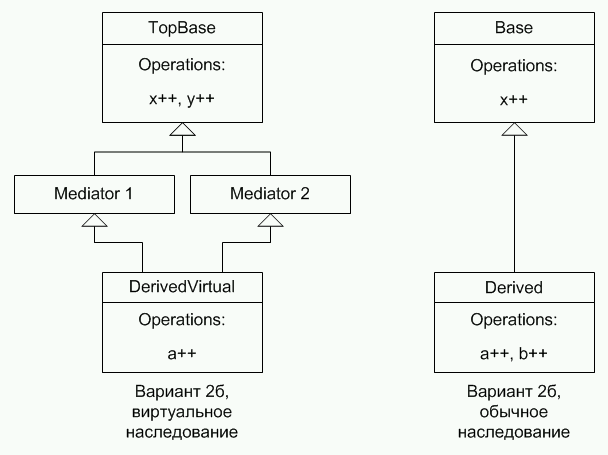
Рисунок 10. Вызов виртуальной функции, вариант 2б
В ячейках таблиц указан процент производительности различных вариантов вызовов функций при виртуальном наследовании, по отношению к производительности вызовов функций при обычном наследовании. Соответственно число больше 100 означает, что вызов функции при виртуальном наследовании, в среднем, обошелся дешевле вызова функции при обычном наследовании.
| Оптимизация | Вариант вызова функции | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Вариант 1 | 91 | 68 | 74 | 79 |
| Вариант 2а | 72 | 64 | 61 | 54 | |
| Вариант 2б | 69 | 54 | 57 | 50 | |
| -O2 | Вариант 1 | 83 | 57 | 62 | 74 |
| Вариант 2а | 75 | 54 | 57 | 62 | |
| Вариант 2б | 60 | 48 | 54 | 58 | |
| -O3 -fomit-frame-pointer | Вариант 1 | 28 | 48 | 27 | 74 |
| Вариант 2а | 76 | 47 | 48 | 62 | |
| Вариант 2б | 57 | 41 | 42 | 58 |
| Оптимизация | Вариант вызова функции | gcc 2.96, % | gcc 3.3, % | gcc 4.1, % | intel 9.1, % |
|---|---|---|---|---|---|
| -O0 | Вариант 1 | 95 | 79 | 77 | 45 |
| Вариант 2а | 123 | 75 | 76 | 35 | |
| Вариант 2б | 120 | 61 | 66 | 25 | |
| -O2 | Вариант 1 | 90 | 66 | 66 | 77 |
| Вариант 2а | 91 | 138 | 60 | 60 | |
| Вариант 2б | 139 | 116 | 50 | 50 | |
| -O3 -fomit-frame-pointer | Вариант 1 | 33 | 16 | 100 | 77 |
| Вариант 2а | 91 | 138 | 60 | 60 | |
| Вариант 2б | 139 | 116 | 50 | 49 |
| Оптимизация | Вариант вызова функции | gcc 2.95, % | gcc 3.3, % | gcc 4.1, % |
|---|---|---|---|---|
| -O0 | Вариант 1 | 94 | 96 | 85 |
| Вариант 2а | 101 | 61 | 73 | |
| Вариант 2б | 97 | 58 | 65 | |
| -O2 | Вариант 1 | 94 | 95 | 84 |
| Вариант 2а | 93 | 62 | 81 | |
| Вариант 2б | 91 | 57 | 71 | |
| -O3 -fomit-frame-pointer | Вариант 1 | 18 | 16 | 18 |
| Вариант 2а | 92 | 61 | 86 | |
| Вариант 2б | 83 | 56 | 70 |
| Оптимизация | Вариант вызова функции | gcc 3.4, % |
|---|---|---|
| -O0 | Вариант 1 | 76 |
| Вариант 2а | 58 | |
| Вариант 2б | 50 | |
| -O2 | Вариант 1 | 71 |
| Вариант 2а | 67 | |
| Вариант 2б | 54 | |
| -O3 -fomit-frame-pointer | Вариант 1 | 22 |
| Вариант 2а | 57 | |
| Вариант 2б | 48 |
Как для виртуальных, так и для невиртуальных функций производительность вызовов при виртуальном наследовании в большинстве случаев сильно уступает производительности вызовов при одиночном наследовании. Тот факт, что в подавляющем большинстве случаев «Вариант 2а» выполнялся быстрее «Варианта 2б», указывает на зависимость времени, затраченного на вызов функции, от числа обращений к данным виртуального базового класса внутри этой функции. Теоретически, этой зависимости можно было бы избежать, сохранив указатель на данные виртуального базового класса в начале функции.
Наиболее интересными случаями применения информации о типах времени выполнения являются попытки преобразования, связанные с анализом иерархии типов. Такой анализ выполняется, например, при использовании преобразования dynamic_cast. Язык C не поддерживает явного создания иерархии типов, поэтому сравнить функционально эквивалентный C- и C++-код представляется затруднительным. Поэтому ограничимся теоретическим рассмотрением возможной реализации механизма поддержки информации о типах времени выполнения и анализом возникающих при этом накладных расходов.
Предположим, что имеется иерархия типов, представленная на рисунке ниже (стоит заметить, что тип E должен быть полиморфным).
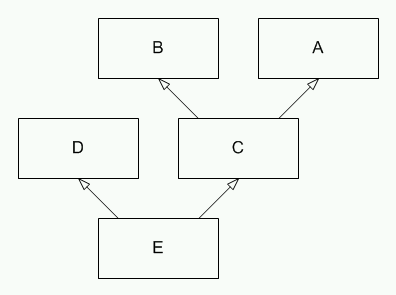
Рисунок 11. Иерархия типов для разбора механизма RTTI..
Теперь предположим, что имеется такой фрагмент кода на C++:
E * pE( new E ); B * pB( pE ); D * pD( dynamic_cast< D * >( pB ) ); |
Очевидно, что преобразование в последней строке должно завершиться успешно. Однако в качестве аргумента для преобразования передается указатель на объект типа B, который не является прямым базовым типом для D. Для корректного преобразования необходимо спуститься по иерархии типов до типа E и затем выполнить преобразование. Подобный обход иерархии типов может быть выполнен с помощью реализации поддержки информации о типах времени выполнения, представленной на рисунке ниже.
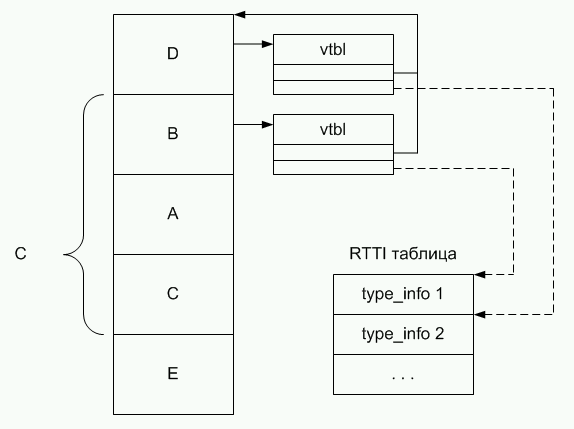
Рисунок 12. Возможная реализация механизма RTTI
Таблица виртуальных функций расширяется еще одним указателем, который позволяет получить информацию о типе. Сама информация обо всех типах хранится в памяти в отдельной таблице. При наличии указателя pB сначала осуществляется поиск начала реально созданного объекта, а затем находится таблица со списком информации о типах всех предков объекта. Далее производится последовательное сравнение type_info для типа-источника со списком типов из таблицы. Если на каком-то шаге type_info совпали, то преобразование возможно.
Таким образом, накладными расходами будут являться затраты памяти на хранение дополнительных указателей и хранение таблицы RTTI, а также накладные расходы процессорного времени на поиск таблицы и последовательные сравнения. Обычно сравнения не требуют дорогостоящих сравнений строк. Однако существуют реализации компиляторов C++, которые полагаются на строковые сравнения.
C++ предлагает механизм исключений в качестве способа обработки ошибок. Традиционные альтернативы языка С это:
Наиболее популярными способами реализации исключений являются следующие: табличный подход и подход, при котором генерируется дополнительный код.
В случае табличного подхода на этапе компиляции создаются таблицы, в которых в соответствие диапазонам значений счетчика команд ставятся действия, которые необходимо выполнить в случае возникновения исключительной ситуации. Это может быть передача управления соответствующему catch-блоку, вызов деструкторов локальных объектов, раскрутка стека и т. п. Основным накладным расходом времени выполнения при таком подходе будет оперативная память, в которой будут храниться подготовленные таблицы.
В случае подхода, при котором генерируется дополнительный код, описание действий, которые необходимо выполнить в случае возникновения исключения, формируется в темпе выполнения программы. Эти действия описываются примерно так же, как и при табличном подходе. Основной накладной расход времени выполнения при этом – процессорное время. Таблицы действий займут существенно меньше места в памяти, чем при табличном подходе, в силу их динамического характера.
Наиболее популярным и простым способом обработки ошибок в C является анализ кодов возврата функций. Код обычно похож на приведенный ниже:
int f( void );
. . .
{
int ReturnValue;
. . .
ReturnValue = f();
if ( ReturnValue != 0 )
{
/* Какая-то обработка ошибки */
}
/* Ошибок нет */ |
В приведенном выше фрагменте накладным расходом процессорного времени являются операции сравнения кода возврата с некоторой величиной и, возможно, выполнение перехода. Это сравнение выполняется независимо от того, закончилось ли выполнение функции f() ошибкой или успехом. В C++-коде, использующем механизм исключений, кодов возврата не будет, не будет и оператора if. Соответственно, накладных расходов процессорного времени при успешном завершении функции не будет. Однако при генерации исключения накладные расходы на его обработку будут, скорее всего, больше, чем накладные расходы кода на C. Можно оценить время, затраченное на обработку исключения в коде на C++, и время, потраченное на проверку кода возврата в коде на C. Отношение этих величин даст некоторое число. Это число показывает минимальное количество успешных вызовов функции, при котором код на C++ будет работать эффективнее с точки зрения потребления процессорного времени, чем код на C. Если, например, число равно 220, то это означает, что если исключение генерируется реже, чем один раз на 220 вызовов, то код с использованием механизма обработки исключений будет работать быстрее, чем код, основанный на анализе кода возврата. Если же исключение генерируется чаще, чем один раз на 220 вызовов, то анализ кода возврата будет эффективнее.
В таблицах ниже приведены результаты тестов с указанием отношения времени, затраченного на обработку исключения к времени анализа кода возврата.
| Оптимизация | gcc 2.95 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|
| -O0 | 265 | 396 | 394 | 491 |
| -O2 | N/A | 497 | 445 | 854 |
| -O3 –fomit-frame-pointer | N/A | 470 | 609 | 711 |
| Оптимизация | gcc 2.96 | gcc 3.3 | gcc 4.1 | intel 9.1 |
|---|---|---|---|---|
| -O0 | 164 | 232 | 202 | 465 |
| -O2 | 509 | 635 | 582 | 1445 |
| -O3 –fomit-frame-pointer | 512 | 646 | 505 | 1399 |
| Оптимизация | gcc 2.95 | gcc 3.3 | gcc 4.1 |
|---|---|---|---|
| -O0 | 87 | 88 | 84 |
| -O2 | 101 | 112 | 121 |
| -O3 –fomit-frame-pointer | 107 | 108 | 270 |
| Оптимизация | gcc 3.4 |
|---|---|
| -O0 | 100 |
| -O2 | 102 |
| -O3 –fomit-frame-pointer | 106 |
Частоты, приведенные в таблицах, могут быть использованы разработчиками при выборе в пользу того или иного способа обработки ошибок. Интересен факт, что на фоне сравнимых результатов различных версий компилятора gcc, компилятор компании Intel демонстрирует результаты в 2 – 2.5 раза хуже.
Компилятор gcc 2.95 на платформе IA-32 при включении оптимизации генерировал код, приводящий к аварийному завершению работы программы. В связи с этим, в соответствующих ячейках таблицы результаты отсутствуют.
Библиотека ввода-вывода C++ пользуется репутацией неэффективной библиотеки. На производительность потоков ввода-вывода C++ может влиять режим синхронизации с потоками ввода-вывода C. Этот режим по умолчанию включен.
В тестовых программах производились операции вывода в файл целых в десятичном и в шестнадцатеричном формате, вывод чисел с плавающей точкой. Все операции выполнялись в двух вариантах – с включенной и отключенной синхронизацией потоков. Затем подобным образом выполнялись операции ввода. На рисунках ниже представлены результаты тестов. По вертикальной оси отложено время, затраченное на операции. Чем больше время и выше столбик, тем хуже производительность.
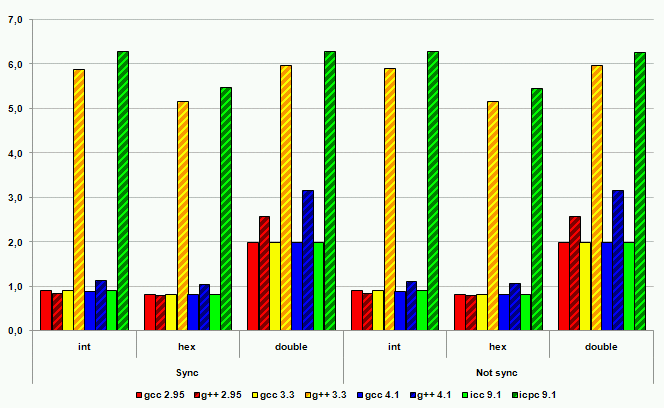
Рисунок 13. Операции ввода на платформе IA-32
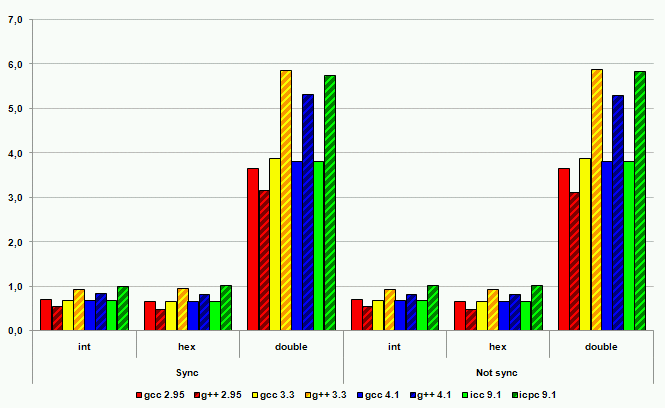
Рисунок 14. Операции вывода на платформе IA-32
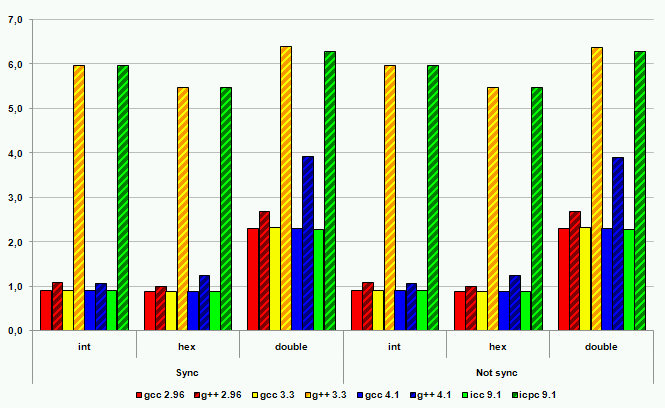
Рисунок 15. Операции ввода на платформе IA-64
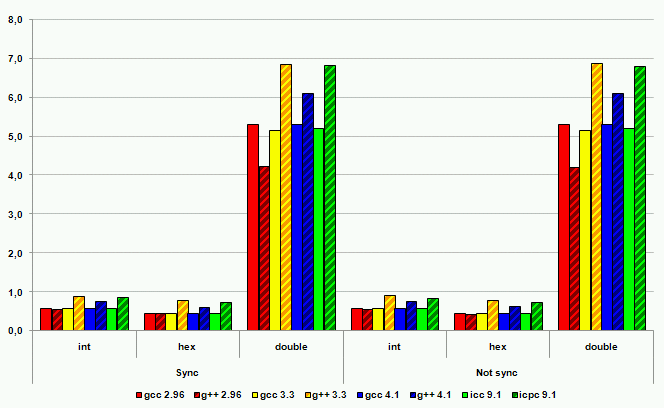
Рисунок 16. Операции вывода на платформе IA-64
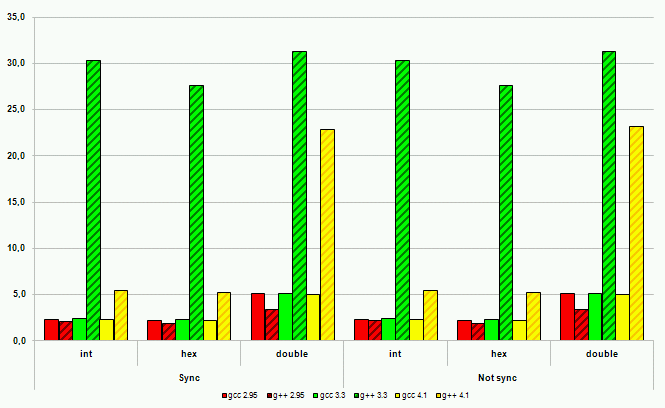
Рисунок 17. Операции ввода на платформе Sun
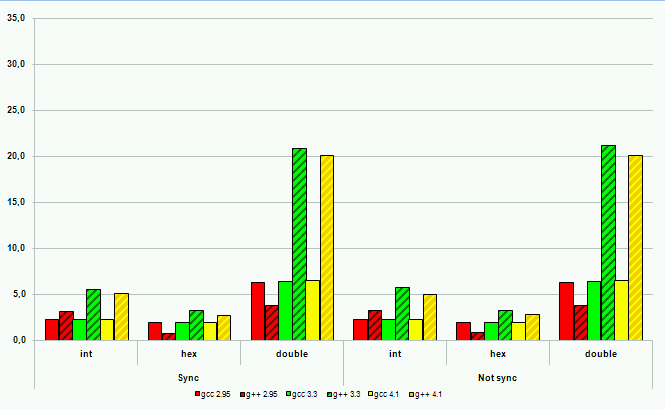
Рисунок 18. Операции вывода на платформе Sun
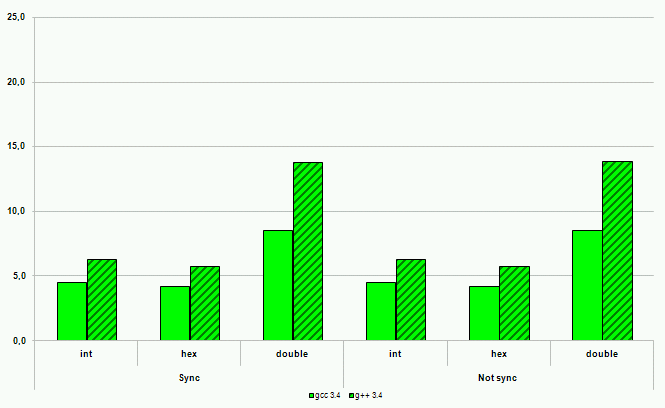
Рисунок 19. Операции ввода на платформе ARM
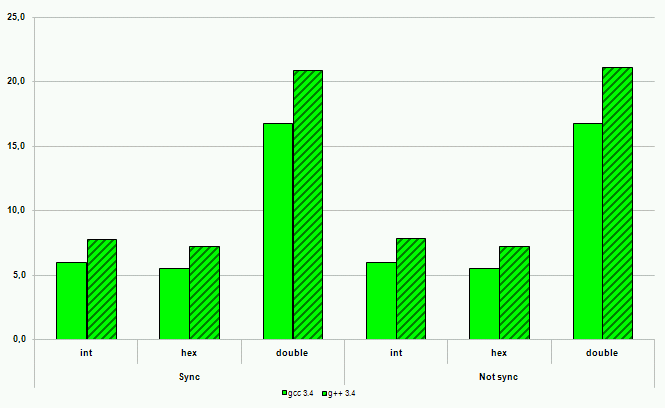
Рисунок 20. Операции вывода на платформе ARM
Производительность ввода-вывода с использованием потоков C++ во всех случаях, за одним исключением, оказалась хуже производительности ввода-вывода в стиле C. Наихудшие результаты – замедление порядка 600%. Исключение из правил, то есть лучшая производительность ввода-вывода в стиле C++, было продемонстрировано компилятором gcc серии 2. Однако это не дает поводов для оптимизма. Некоторые источники говорят о некорректной реализации ввода-вывода в стиле C++ в этом компиляторе с точки зрения соответствия требованиям стандарта. И, кроме того, этот компилятор на сегодняшний момент устарел и не рассматривается многими разработчиками как серьезный кандидат на работу с кодом C++.
Современные компиляторы C++ демонстрируют высокое качество реализации новых языковых механизмов на всех платформах. Код на C++ практически не проигрывает в производительности функциональному эквиваленту на C, а в некоторых случаях позволяет получить и более высокое быстродействие программ. Досадным исключением остается потоковый ввод-вывод в стиле C++. Однако для этой ситуации есть обходной путь – компилятор C++ справится и с кодом ввода-вывода, написанным в стиле C. Кроме того, всегда остается надежда на разработчиков компиляторов. Библиотека ввода-вывода C++ неизбежно будет становиться эффективнее и эффективнее. А у компиляторов C, учитывая поддержку языком C++ большего количества подходов к проектированию программного обеспечения, будет оставаться все меньше и меньше шансов на использование в сложных проектах.
Для облегчения сбора результатов тестов на различных платформах с использованием различных компиляторов и ключей оптимизации разработан набор скриптов. Скрипты легко расширить новыми тестами, компиляторами или наборами ключей оптимизации. Для этого необходимо сделать изменения в описанных ниже файлах.
Файл находится в корне предлагаемой структуры каталогов и содержит список тестируемых компиляторов. Например:
# File format: # first compiler vendor # second c compiler path # third c++ compiler path gcc4.1.1 /home/twinpeek/compilers/gcc/4.1.1/bin/gcc /home/twinpeek/compilers/gcc/4.1.1/bin/g++ intel9.1 /home/twinpeek/compilers/intel/9.1.038/bin/icc /home/twinpeek/compilers/intel/9.1.038/bin/icpc |
В примере определены названия и пути к двум компиляторам – gcc серии 4 и компилятору компании Intel. Строки комментариев начинаются с символа ‘#’. В файле допускаются пустые строки.
Файл также находится в корне предлагаемой структуры каталогов и содержит список каталогов проектов, которые участвуют в тестировании. Например:
# File format: # Pathes to the projects abstraction_penalty/stepanov_test abstraction_penalty/mitigation abstraction_penalty/templates_boat_diff abstraction_penalty/templates_boat_same |
В примере определены четыре проекта, которые заданы в виде относительных путей. Строки комментариев начинаются с символа ‘#’. В файле допускаются пустые строки.
Количество наборов ключей оптимизации, для которых выполняются тесты для каждого компилятора, определяется индивидуально для каждого проекта. Поэтому файл optimizations.info находится в каталоге каждого из проектов. Например, файл optimizations.info для проекта abstraction_penalty/stepanov_test может выглядеть так:
0 1 2 |
Каждая строка задает название набора ключей оптимизации. Здесь выбраны цифры в качестве названий.
Поиск ключей оптимизации компилятора, соответствующих каждому набору из файла optimizations.info производится следующим образом. Формируется имя файла по принципу:
<НазваниеКомпилятора>_opt<НазваниеНабораКлючей>.flags |
Например, для компилятора компании Intel и последнего набора ключей оптимизации будет сформировано имя:
intel9.1_opt2.flags |
Поиск этого файла будет производиться в каталоге flags соответствующего проекта. Если файл не найден в каталоге flags соответствующего проекта, то будет произведен поиск файла с таким же именем в каталоге flags, находящемся в корне предлагаемой структуры каталогов. В файле должны быть определены две переменные – для C- и C++-компилятора – с ключами оптимизации. Например, файл intel9.1_opt2.flags может быть таким:
CFLAGS=-O3 -fomit-frame-pointer CPPFLAGS=-O3 -fomit-frame-pointer |
Таким образом, поддерживается возможность иметь общие настройки ключей оптимизации для всех проектов и возможность тонкой индивидуальной настройки ключей оптимизации для конкретного проекта.
Запуск компиляции всех проектов и сбора результатов осуществляется командой
./do_test.sh > TestResults.log |
| Оценка 240 Оценить
|
