Язык SQL в настоящее время повсеместно реализован в современных реляционных базах данных. Тем не менее, возможности SQL в части выборки данных (оператора SELECT, проще говоря), не обязательно должны использоваться только внутри СУБД. С точки зрения семантики языка, оператор выборки данных манипулирует таблицами и полями, безотносительно того, как они физически организованы и где расположены. Это наводит на мысль о возможности конструирования на основе SQL всевозможных специализированных языков выборки данных, применяемых в необходимых случаях аналогично тому, как обычно используются DSL языки (предметно-ориентированные языки программирования [1]).
Одним из типичных примеров подобного подхода является WQL – язык запросов к инфраструктуре WMI (Windows Management Instrumentation), реализованный компанией Майкрософт для Windows [2]. В качестве таблиц в запросах WQL выступают классы модели данных CIM (Common Information Model), которые содержат информацию о различных частях инфраструктуры предприятия. В практическом плане, эти запросы позволяют, «в стиле SQL», выбирать информацию об устройствах, конфигурации систем, работающих процессах, событиях и многом другом.
Другой хорошо известный пример – это язык HQL (Hibernate Query Language), используемый в O/R-mapper Hibernate от компании JBoss [3]. В отличие от предыдущего случая, HQL в обычно не выполняет запросы самостоятельно, а транслирует их в диалект используемой базы данных, на основе заданного отображения объектной модели в структуру таблиц. Таким образом, Hibernate обеспечивает не только хранение объектов в СУБД, но и механизм запросов, не зависящий от физической организации схемы данных. Это позволяет писать приложения, не привязываясь к конкретной СУБД, что является очень важным качеством в больших проектах.
Любопытно, что аналогичным образом работает и «1С:Предприятие», начиная с версии 8.0. Язык запросов 1С, если использовать латинские названия операторов, представляет собой все тот же SQL с небольшим количеством адаптированных объектных расширений, который транслируется сервером приложения 1С в последовательность запросов к используемой для хранения информационной базы СУБД. При этом поддержка DML не реализована, и изменение данных происходит из внутреннего скриптового языка, посредством объектов данных конфигурации, что в целом повторяет подход, применяемый в любых обычных ORM.
Еще одной областью применения SQL без СУБД, на которой хотелось бы остановиться подробнее, являются всевозможные драйвера для чтения данных из плоских файлов, которые используются через интерфейсы JDBC или ADO.NET. Поскольку и JDBC и ADO.NET проектировались для доступа к реляционным базам, технически такие источники данных подразумевают SQL интерфейс, имитирующий СУБД. Более того, теоретически поддержка SQL на уровне файла данных может оказаться эффективным инструментом их анализа. Дело в том, что хотя последовательное чтение таблицы (table full scan) в любой реляционной СУБД выполняется несоизмеримо быстрее чтения плоского файла, соответствующую таблицу перед использованием еще нужно загрузить в базу данных. И если вести речь о файле размером в пару гигабайт и более, то предварительная загрузка соответствующей таблицы во многих случаях будет значительно медленнее выполнения простого запроса на уровне файла данных.
Для иллюстрации сказанного рассмотрим следующую задачу. Имеем каталог логов доступа пользователей к Microsoft ISA Server в виде набора текстовых файлов, размером 2‑3 гигабайта. Требуется узнать общее количество трафика, который использовал конкретный пользователь по дням. Очевидными способами решения этой задачи являются либо написание специального скрипта, либо создание таблицы в базе данных и загрузка в нее содержимого каждого файла (серьезные решения для совсем больших объемов данных, вроде Apache Hadoop/Hive, не рассматриваем). Процессор SQL, способный, где это возможно, в потоковом режиме выполнять запросы к плоским файлам и имеющий механизм экспорта результатов, в этом случае мог бы стать неплохим подспорьем.
Идея выполнять аналитические запросы к плоским файлам без их загрузки в базу данных очевидным образом приводит нас к необходимости поддержки распределенных запросов к различным источникам данных. Предположим, что в нашей задаче требуется сформировать статистику в виде отчета по потреблению интернет трафика в разрезе подразделений. Проблема в том, что в логах ISA Server нет подразделений. В них нет даже фамилий пользователей, а есть только их имена в системе. Таким образом, было бы неплохо прочитать необходимые данные из ActiveDirectory, представив их в виде какой-то виртуальной таблицы и соединить ее с данными из файлов. Распределенные запросы так же полезны в случае, когда мы хотим выбрать ограниченный, но достаточно большой набор записей из списка. Например, мы имеем в Oracle большую таблицу, из которой для анализа информации требуется выбрать какие-то записи перечислением составных ключевых значений. Конечно, возможно написать соответствующий оператор SQL, но если список большой - это не слишком удобно, и скорее всего, потребуется промежуточная таблица. Поэтому, почему бы не сделать распределенный запрос, соединяющий нужную таблицу и файл электронной таблицы Excel, где поместить необходимый перечень значений.
На самом деле, механизм, позволяющий более-менее эффективно выполнять запросы SQL к разнородным данным, представимым в виде таблиц, открывает много интересных возможностей.
Эта статья о библиотеке QueryMachine, которая является «универсальным» драйвером ADO .NET предназначенным для выполнения SQL запросов выборки из любых источников структурированных данных. Она обеспечивает следующие возможности:
Сайт проекта размещен на CodePlex http://qm.codeplex.com. Код написан на C# и использует общую платформу с разработанным автором процессором XQuery [4]. Там же размещен QmConsole – WPF-клиент для выполнения запросов XQuery и SQL с возможностью экспорта результатов в различные форматы файлов и SQL базы данных.
Описываемая реализация определяет небольшое количество дополнений к стандартному синтаксису SQL-92:
Поскольку в SQL запросе можно использовать сразу несколько источников данных, для их именования в названии таблиц используется префикс.
Например,
SELECT * FROM TXT:"1.txt"
SELECT * FROM XLS:"Test.xls"."sheet1$" |
В первом рассматриваемом запросе с помощью встроенного парсера выбираются все поля из плоского файла 1.txt. Во втором запросе выбираются все поля электронной таблицы Test.xls из вкладки (Worksheet) sheet1. Для чтения данных из файла Excel в этом случае система использует драйвер OLEDB Microsoft JET 4.0. Следующая таблица описывает встроенные префиксы и соответствующие им источники данных:
|
|
|
|---|---|
|
XML |
Префикс для XML файлов, используемых как источники данных; |
|
DBF |
Таблицы в формате DBF. Для чтения данных используется MS JET 4.0; |
|
XLS |
Таблицы Excel. Имя таблицы состоит из имени файла и названия вкладки с суффиксом «$». Для чтения данных используется MS JET 4.0; |
|
TXT |
Плоский файл в формате CSV или Fixed-Length. Используется внутренний потоковой парсер исключающий предварительную загрузку данных в память; |
|
ADO |
Формат XML файла используемый ADO .NET DataSet. |
Перечисленные выше префиксы в качестве имени таблицы используют имя файла данных, либо только идентификатор без расширения и без кавычек. Если расширение не указанно, оно добавляется исходя из ожидаемого типа файла. Кроме того, если получившееся имя файла не является абсолютным, система ищет требуемый файл в заранее определенном списке каталогов.
Любые другие источники данных, доступные с помощью ADO .NET с помощью класса DatabaseDictionary могут быть связаны с выбранными префиксами и таким образом использованы в запросах. Более того, один из источников данных может быть отмечен как основной. Для основного источника данных указывать префикс не обязательно.
Например, предположим, что для СУБД Oracle и SQL Server сконфигурированы два источника данных с префиксами ORA и MSSQL соответственно. Также будем считать, что в Oracle необходимая таблица находится в схеме текущего пользователя и этот пользователь NORTHWND, а база данных SQLServer помечена как основная. Тогда будут допустимы следующие запросы:
SELECT * FROM ORA:Orders NATURAL JOIN "Order Details"
SELECT * FROM ORA:NORTHWND.Orders NATURAL JOIN MSSQL:"Order Details" |
| ПРИМЕЧАНИЕ Здесь, и далее в большинстве запросов используются данные из стандартного примера для MS SQL Server NORTHWND.MDB. Эти примеры можно попробовать в работе, настроив соединение к SQL Server из QmConsole. Для тестирования запросов к СУБД Оракул содержимое таблицы Orders можно переместить командой Move Data. |
Собственно SQL-92 не предусматривает возможности использовать какие-либо функции в выражениях, в том смысле, что правило value_expression_primary в BNF грамматике языка [5] декларирует только ссылку на колонки, результаты агрегации, скалярный подзапрос и операторы CASE и CAST. Данная реализация SQL добавляет в это правило функциональные выражения, которые вычисляются в коде и расширяют возможности системы без необходимости изменения грамматики. Имена функцией QueryMachine начинаются с префикса «$» (dollar sign).
Следующая таблица описывает имеющиеся в настоящий момент дополнительные функции:
|
|
|
|---|---|
|
$extract(dataSource, xpath) |
Извлекает фрагмент XML документа по заданному выражению XPath. |
|
$base64decode(string) |
Декодирует данные из кодировки base64 в byte[] |
|
$base64encode(byte[]) |
Кодирует данные из byte[] в кодировку base64 |
|
$systab(DbAlias, tablename) |
Возвращает таблицу tablename, вызывая DbConnection.GetSchema() для драйвера ADO .NET заданного префиксом DbAlias. |
|
$ldap(DomanServicePath, LdapQuery, PropertiesToLoad) |
Выполняет поиск в каталоге домена DomainServicePath с критерием, заданным LdapQuery. Пустая строка в DomainServicePath по умолчанию задает текущий домен. Возвращаемая таблица содержит колонки соответствующие набору свойств, который требуется получить для каждого найденного объекта. Набор свойств определяется строкой PropertiesToLoad, которая содержит имена свойств, разделяемые через запятую. Эта функция использует стандартный класс DirectorySearcher. |
|
$ldap_props(DomanServicePath, LdapQuery) |
Возвращает информационную таблицу, содержащую все доступные свойства объектов, выбираемых критерием LdapQuery. Эта функция использует стандартный класс DirectorySearcher. |
|
$text() |
Возвращает текстовое содержимое текущего XML элемента. |
|
$rownum() |
Возвращает текущий номер строки. Эта функция допускается только внутри оператора SELECT. |
|
$format(FormatStr, Arg1,…) |
Форматирует строку аналогично String.Format. |
|
$getfilename(Path) |
Возвращает имя файла из строки, представляющей полный путь файла. |
|
$getfilepath(Path) |
Возвращает каталог файла из строки, содержащей полный путь файла. |
|
$machinename() |
Возвращает имя системы. |
|
$userdomain() |
Возвращает имя домена текущего пользователя системы. |
|
$username() |
Возвращает текущее имя пользователя системы. |
Функциональные выражения так же могут использоваться для обращения к источникам данных, которые требуют определения дополнительных параметров. Например, для чтения информации из ActiveDirectory необходимо указать домен, фильтр Ldap и набор свойств, который передается для каждого найденного объекта. Поэтому такой источник данных удобно обозначить в виде функции $ldap, принимающей необходимые аргументы. Реализация этой функции в коде выполняет необходимый запрос к ActiveDirectory с помощью стандартного класса DirectorySearcher и возвращает результат в виде виртуальной таблицы, состоящей из полей соответствующих указанному набору свойств. Также заметим, что если какое-либо свойство объекта каталога имеет несколько значений, то в соответствующее поле помещается массив значений.
Следующий пример иллюстрирует простой запрос к ActiveDirectory, который выводит список пользователей в виде таблицы: «учетная запись», «ФИО» и «подразделение»:
SELECT * FROMTABLE $ldap('','(&(objectClass=person)(sn=*))','SAMAccountName,displayname,department') |
Применению этого подхода с формальной точки зрения препятствует невозможность использовать какие-либо выражения в операторе FROM, так как обычная грамматика SQL в правиле для table_reference допускает только название таблицы или подзапрос. Поэтому, в язык SQL для QueryMachine добавлена конструкция TABLE, определяющая динамическую таблицу по следующим правилам:
table_ref_spec
: table_name
| dynamic_table
| subquery
;
dynamic_table
: TABLE funcall
| TABLE column_ref
| TABLE '(' value_exp ')'
| TABLE xml_query
; |
Как видно из приведенной выше грамматики, в качестве динамической таблицы может выступать вызов функции, содержимое поля из таблицы, запрос XQuery или произвольное вычисляемое выражение. Ключевое слово TABLE, а так же скобки при использовании произвольного выражения (не функции) необходимы для исключения Shift/Reduce конфликтов в грамматике.
Динамические таблицы могут использоваться и в соединениях, коррелируясь с другими таблицами, участвующими в запросе. Предположим, нам необходим запрос, который выводит список учетных записей и идентификаторов групп, к которым относятся данные учетные записи.
Очевидный запрос, дающий информацию, возвращаемую нашей функцией, не будет корректным, поскольку поле memberof многозначное иявляется массивом String[] в случаях, когда одна и та же учетная запись относится к нескольким группам:
SELECT * FROMTABLE $ldap('', '(&(objectClass=person)(sn=*))','SAMAccountName,memberof') |
Чтобы выделить отдельные строки из массива memberof, можно воспользоваться синтаксисом для получения элементов по индексу:
SELECT SAMAccountName as username, memberof[1], memberof[2], memberof[3]
FROMTABLE $ldap('', '(&(objectClass=person)(sn=*))','SAMAccountName,memberof') WHERE memberof ISNOTNULL |
Этот запрос будет выполняться без ошибок, вне зависимости от количества элементов в любом из массивов memberof, так как операция получения элемента по индексу работает аналогично XQuery по следующим правилам:
Однако рассматриваемый запрос будет возвращать только идентификаторы максимум первых трех групп, и выдавать, вообще говоря, не те данные, которые требовались. Для получения нужного результата, соединим таблицу возвращаемую функцией $ldap, с новой динамической таблицей, формируемой по полю memberof:
SELECT SAMAccountName as username, m.node as memberof FROMTABLE $ldap('', '(&(objectClass=person)(sn=*))', 'SAMAccountName,memberof') dir, TABLE dir.memberof m |
Приведенный выше запрос требует дополнительных пояснений.
Во-первых, QueryMachine умеет внутри конструкции TABLE преобразовывать в таблицы любые перечисляемые типы данных. Результатом такого преобразования является виртуальная таблица, содержащая единственное поле – node, в которое и помещается элемент перечисления.
Во-вторых, система обнаруживает, что динамическая таблица является подчиненной и вычисляется из полей первой таблицы. Поэтому транслятор SQL создает специальный вид соединения — детальное соединение (detail join). Детальное соединение порождает новую динамическую таблицу, вычисляя выражение (в нашем случае она определяется содержимым поля memberof) для каждой строки мастер-таблицы, и выполняет декартово произведение строк мастер-таблицы на множество записей каждой порожденной таблицы. Множество полей получившейся соединённой таблицы будет являться объединением полей мастер таблицы и полей каждой из таблиц, порожденных в соединении. В рассматриваемом примере, все порождаемые таблицы имеют одну и ту же структуру, поэтому результатом соединения будет являться множество из трех полей: SAMAccountName, memberof и node.
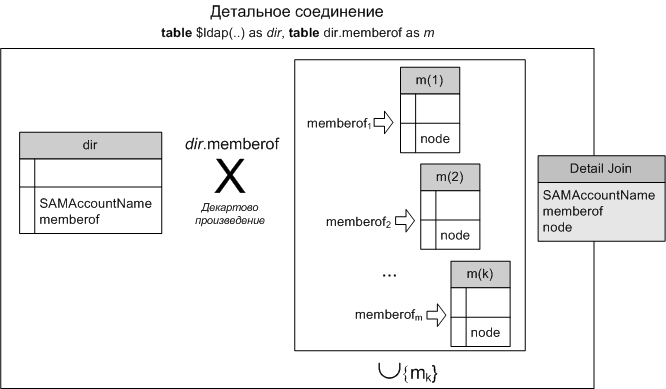
Рисунок 1
Детальное соединение является основным механизмом, с помощью которого в QueryMachine реализована поддержка XML.
При написании запросов к файлам данным зачастую требуется обрабатывать группы файлов. В рассмотренной ранее задаче анализа Microsoft ISA Server требуется обрабатывать группу файлов, так как события сервера разбиваются по нескольким лог-файлам с некоторым периодом времени, устанавливаемым системным администратором. Стандартным способом решения этой задачи будет разбиение запроса на части, соответствующие каждому анализируемому файлу и объединение результатов с помощью union all:
SELECT … FROM TXT:"file1.txt"
…
UNIONALLSELECT … FROM TXT:"file2.txt"
… |
Такие конструкции могут быть весьма громоздкими и требуют, чтобы набор файлов был заранее определен перед написанием запроса. Чтобы избежать необходимости дублировать фактически один и тот же запрос для разных файлов, в QueryMachine реализован механизм, позволяющий для плоских файлов и XML указывать вместо имени таблицы – маску, определяющую нужную группу файлов:
SELECT * FROM TXT:"file*.txt" |
Получающаяся в результате таблица содержит записи соответствующие каждому файлу и всегда состоит из двух полей: name – полное имя файла и node – его содержимое в виде внутренней таблицы. Далее, чтобы использовать данные каждого файла, просто извлекаем его таблицу с помощью детального соединения. Например, следующий простой запрос подсчитывает общее количество записей во всех файлах:
SELECT
COUNT(*) FROM TXT:"file*.txt" T, TABLE T.node |
Следует обратить внимание на то, что при детальном соединении происходит объединение полей всех порожденных таблиц, поэтому файлы, попадающие в группу, не обязательно должны быть одинаковой структуры. Более того, QueryMachine не буферизует целиком вложенные таблицы перед выполнением соединения, поэтому приведенный выше запрос будет работать на исходных данных абсолютно любого размера.
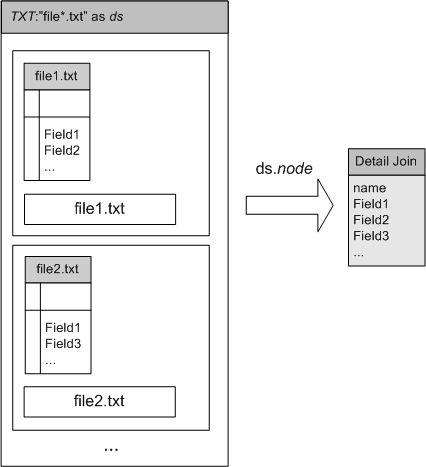
Рисунок 2
На приведенном выше рисунке видно, что в случае, когда в группе файлов мы имеем элементы file1.txt с полями {Field1, Field2, …} и file2.txt c полями {Field1, Field3,…}, то результатом детального соединения будет представление с полями {name,Field1,Field2,Field3,…}, при условии, что типы данных поля Field1 в обоих файлах совпадают. Таким образом, если name = “file1.txt” будут заполнены поля Field1 и Field2, а если name = “file2.txt” – поля Field1 и Field3.
Следует заметить, что расширения языка SQL для обработки XML [7] данных являются частью стандарта SQL:2003, а не SQL-92. Практически каждая известная СУБД реализует какие-то средства для поддержки SQL/XML. С точки зрения автора, одной из наиболее полных и близких к спецификации реализаций является Oracle XML DB [8].
Сутью спецификацию SQL/XML, с точки зрения идеологии, является добавление в язык SQL операторов, позволяющих использовать XML данные в SQL запросах и генерировать XML данные с помощью SQL запросов.
Начнем с генерирования XML данных в запросах.
QueryMachine реализует поддержку следующих операторов SQL/XML:
Эти операторы могут находиться в части SELECTSQL-запросаи комбинироваться между собой как функциональные выражения, примерно так же, как в Linq-to-XML для создания моделей DOM комбинируются конструкторы классов XElement, XAttribute и другие классы.
Например, запрос
SELECT XMLRoot(
XMLElement(rss,
XMLAttributes('2.0' AS version),
XMLElement(channel,
XMLElement(title, 'RSS Channel Title'),
XMLElement(description, 'RSS Channel Description.'),
XMLElement(link, 'http://www.example.com'),
XMLElement(item)))) |
будет возвращать таблицу, состоящую из единственного поля и одной строки, где разместиться экземпляр класса System.Xml.XmlDocument вот такого содержания:
<rss version="2.0"> <channel> <title>RSS Channel Title</title> <description>RSS Channel Description.</description> <link>http://www.example.com</link> <item /> </channel> </rss> |
Следующий запрос:
SELECT XMLElement(elem, XMLAttributes(OrderID, ProductID, Quantity)), OrderID, ProductID, Quantity
FROM "Order Details" |
выбирает таблицу из четырех полей: первое поле – это экземпляр класса System.Xml.XmlElement, a остальные поля значения из таблицы “Order Details”. Естественно, количество выбираемых запросом записей совпадет с размером этой таблицы.
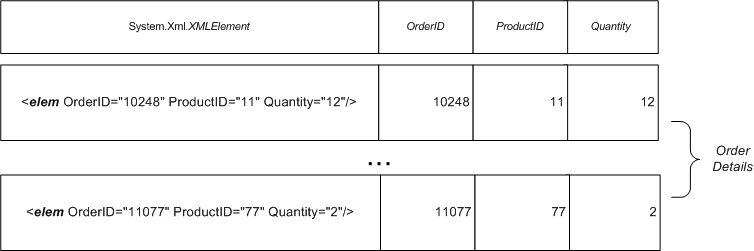
Рисунок 3
Таким образом, оператор XMLElement с двумя аргументами создает экземпляр класса System.Xml.XmlElement с именем элемента, определяемого первым аргументом и вычисляемым содержимым, задающимся во втором аргументе. Обратим внимание, что имя элемента – это не строковая константа, а идентификатор, аналогичный имени в операторе AS. Оператор XMLElement также может иметь более двух аргументов. В этом случае каждый последующий перечисленный аргумент вычисляется и добавляется к содержимому элемента.
Оператор XMLAttributes принимает любое число выражений – аргументов, которые представляет в качестве значений атрибутов текущего элемента. Каждое из этих выражений должно быть явно именовано с помощью оператора AS, за исключением случаев, когда выражение является ссылкой на колонку таблицы (так как колонка сама по себе имеет имя).
Оператор XMLForest работает аналогично XMLAttributes, но представляет значения выражений в виде дочерних элементов. Таким образом, запрос:
SELECT XMLElement(elem, XMLForest(OrderID, ProductID, Quantity))
FROM "Order Details" |
сформирует элементы вида:
<elem> <OrderID>10248</OrderID> <ProductID>11</ProductID> <Quantity>12</Quantity> </elem> |
Остальные элементы XMLPI, XMLRoot и XMLComment предназначены для создания корневого XML документа, комментария и инструкций обработки (processing instruction).
Для упрощения операторов XMLAttributes и XMLForest в QueryMachine добавлены конструкции выбора полей, не предусмотренные стандартом. Они работают аналогично соглашению выбора полей в обычном SQL:
SELECT XMLForest(*) FROM Orders
SELECT XMLElement(elem,XMLAttributes(t.*, Quantity * 2 as DoubleQuantity)) FROM "Order Details" t |
Другими словами, синтаксис SQL для QueryMachine позволяет в операторах XMLElement и XMLAttributes использовать символ * точно так же, как и в операторе select.
Предыдущие рассмотренные примеры дают представление о генерации фрагментов XML, однако выбирают нужные данные в разрозненном виде. Предположим, что нам требуется собрать записи таблицы Orders в один большой документ. Очевидный запрос:
SELECT XMLElement("order", XMLAttributes(*)) FROM Orders |
выберет нам таблицу фрагментов, по одному элементу на каждую запись из Orders. Чтобы собрать все фрагменты в один документ, спецификация SQL/XML предусматривает специальную операцию – агрегацию XML. Эта операция в каком-то смысле похожа на обычную агрегацию, только вместо суммирования или нахождения максимума для числового значения, оператор XMLAgg строит список XML элементов, «схлопывая» обрабатываемое множество строк в одну строку результата, содержащую весь список. Таким образом, следующий запрос возвратит одну запись, содержащую список всех фрагментов XML:
SELECT XMLAgg(XMLElement("order", XMLAttributes(*))) FROM Orders |
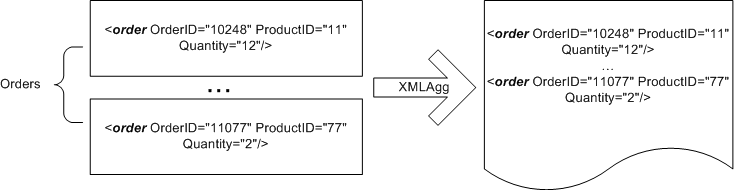
Рисунок 4
Полученный результат все еще не является правильным документом XML (well-formed document), поскольку XML документ должен иметь единственный корневой элемент (document element). Но это не очень большая проблема, так как оператор XMLAgg строит список фрагментов находящихся внутри оператора и может использоваться вместе с другими операторами SQL/XML. Таким образом, следующий запрос построит для нас необходимый XML документ:
SELECT XMLRoot(XMLElement(doc, XMLAgg(XMLElement("order", XMLAttributes(*)))))
FROM Orders |
Однако с оператором XMLAgg не все так просто, как может показаться на первый взгляд. Дело в том, что никакие ссылки на поля таблиц, участвующие в запросе не могут использоваться вне оператора XMLAgg, и, естественно, операторы XMLAgg не могут вкладываться друг в друга. Для того, чтобы понять суть проблемы, предположим, что требуется сформировать документ, содержащий записи таблицы Orders вместе с детализацией из Order Details вот такой структуры:
<doc> <order OrderID="10248" CustomerID="VINET" EmployeeID="5" ...> <detail OrderID="10248" ProductID="42" UnitPrice="9.8000" Quantity="10" /> <detail OrderID="10248" ProductID="11" UnitPrice="14.0000" Quantity="12" /> <detail OrderID="10248" ProductID="72" UnitPrice="34.8000" Quantity="5" /> </order> ... </doc> |
То есть требуется вложить в каждый элемент order соответствующие ему элементы из таблицы Order Details, связав их по внешнему ключу OrderID. Это означает, что в нашем запросе необходимо для каждой записи подзапросом сформировать вложенную таблицу, содержащую детальные записи, отбираемые по полям мастер-таблицы. Язык SQL допускает только скалярные подзапросы в выражениях, однако, так как мы используем XML агрегацию, подзапрос, обрабатывающий данные из Order Details, будет возвращать единственное значение – список элементов XML и таким образом будет допустимым с точки зрения SQL:
SELECT XMLRoot(XMLElement(doc,
XMLAgg(XMLElement("order",
XMLAttributes(*),
(SELECT XMLAgg(XMLElement(detail, XMLAttributes(*)))
FROM "Order Details" d
WHERE o.OrderID = d.OrderID)))))
FROM Orders o |
Здесь внутри XML элемента order находится директива XMLAttributes, устанавливающая атрибутами этого элемента поля строки таблицы Orders, и подзапрос, выбирающий данные из таблицы Order Details как одно значение - агрегированный список элементов detail. Основной запрос и вложенный запрос связаны между собой через алиасы таблиц, аналогично тому, как связываются обычные вложенные подзапросы в части WHERE.
Завершая обсуждение XML-агрегации, следует упомянуть, что поскольку SQL применяет ORDER BY после вычисления SELECT, получается, что сортировка фрагментов XML возможна только самим оператором XMLAgg, ведь обычная сортировка будет применяться к результату агрегации, всегда состоящему из одной строки. Поэтому оператор XMLAgg предусматривает возможность указания полей сортировки:
SELECT XMLAgg(XMLElement("order", XMLAttributes(*)) ORDERBY 1)
FROM Orders |
Синтаксис такой сортировки совпадает с обычным, но производится она оператором XMLAgg.
Описанная выше реализация SQL/XML в QueryMachine позволяет использовать ее как универсальный способ генерации XML данных, однако, с практической точки зрения, имеет небольшую ценность, так как основные СУБД уже включают подобные механизмы. Более интересной, с точки зрения автора, является обратная задача – извлечение табличных данных из существующих XML файлов.
Для иллюстрации сказанного, предположим, что в таблицу Orders требуется загрузить из XML документа, сформированного в предыдущем разделе, какие-то данные. Либо, к примеру, имеется несколько файлов, представляющих собой ордеры, переданные системой B2B через сервер интеграции, и требуется их проанализировать с целью отладки бизнес-процесса (скажем, проверить сумму и количество).
Эта задача встречается довольно часто и во всех известных автору системах решается с помощью проекции документа на необходимую структуру таблицы. Для использования проекции требуется определить множество XML-узлов, по которым будут создаваться строки таблицы, а затем для каждого узла, соответствующего строке – критерии отбора значений каждого поля. Таким образом, для построения таблицы мы разбиваем содержимое документа на строки, а затем каждую строку – на поля.
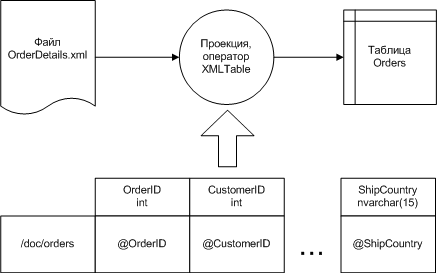
Рисунок 5
Например, для загрузки данных в таблицу Orders сопоставляем строкам – XML элементы order, для чего используем выражение XPath /doc/orders. Далее, предполагая использование каждого найденного элемента в качестве контекста, указываем простейшие XPath-выражения для отбора атрибутов {./@OrderID,./@CustomerID,...,./@ShipCountry}, значения которых присваиваем соответствующим полям каждой строки. Кроме критериев отбора, в карте преобразования, схематично показанной на рисунке 5, так же необходимы объявления типов каждого поля заполняемой таблицы.
Описанный выше подход реализуется в SQL/XML с помощью оператора XMLTable. Следующий пример 17-2 для СУБД Оракул приведен в [8] и дает представление об использовании этого оператора на практике:
SELECT lines.lineitem, lines.description, lines.partid,
lines.unitprice, lines.quantity
FROM purchaseorder,
XMLTable('for $i in /PurchaseOrder/LineItems/LineItem
where $i/@ItemNumber >= 8
and $i/Part/@UnitPrice > 50
and $i/Part/@Quantity > 2
return $i'
PASSING OBJECT_VALUE
COLUMNS lineitem NUMBER PATH '@ItemNumber',
description VARCHAR2(30) PATH 'Description',
partid NUMBER PATH 'Part/@Id',
unitprice NUMBER PATH 'Part/@UnitPrice',
quantity NUMBER PATH 'Part/@Quantity') lines |
Данный пример иллюстрирует основной недостаток оператора XMLTable – необходимость перед написанием запроса анализировать исходный XML документ и детально расписывать поля создаваемой таблицы. Поэтому, несмотря на то, что технически с помощью проекций можно извлекать любые необходимые данные, на практике этот подход не получил широкого распространения.
Между тем, пользователям XML редакторов, таких как Altova XMLSpy или XmlPad, хорошо известна табличная форма документов, в которой удобно просматривать и изменять XML файлы без всяких предварительных определений. Идея проста – представлять последовательность одинаковых XML элементов в виде таблицы, в колонках которой по названию группируются значения атрибутов и содержимое совпадающих дочерних элементов. В тех случаях, когда фрагмент документа не позволяет использовать подобную группировку, последовательность элементов представляется как таблица из одной колонки и несколько строчек, соответствующих каждому такому элементу.
Скриншот табличной формы рассматриваемого файла OrderDetails.xml можно увидеть рис.6 и рис.7. Табличная форма этого документа является таблицей размерностью 2 x 1, первая строка которой – декларация <?xml?> , а вторая – корневой элемент doc. Ячейка, соответствующая корневому элементу, в свою очередь является таблицей размерностью 800 x 15. Эта таблица содержит сгруппированные значения атрибутов элементов order и колонку для дочерних элементов detail. Поскольку каждый элемент order содержит несколько элементов detail, эти ячейки так же могут содержать еще одну вложенную таблицу сгруппированных атрибутов (см. рис 7).
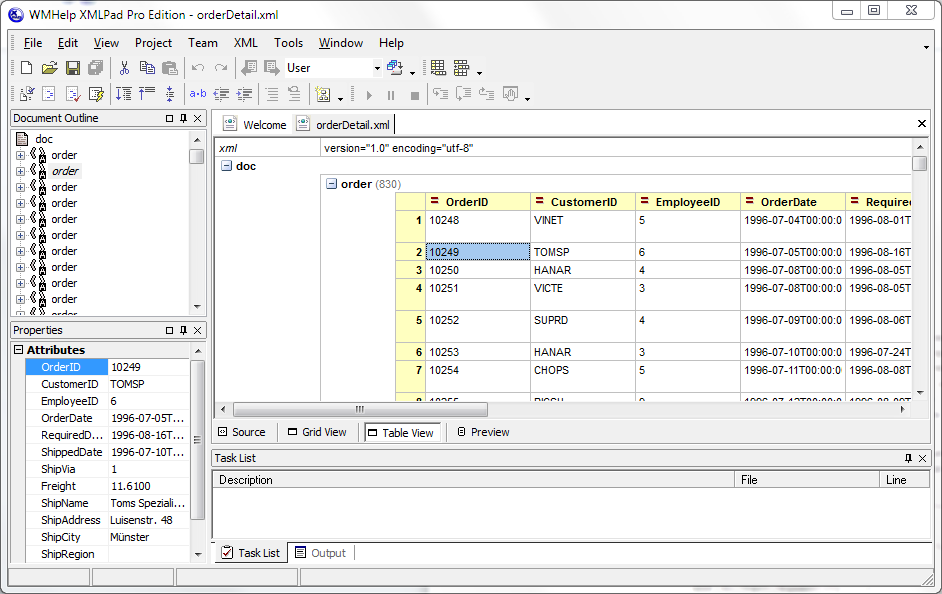
Рисунок 6
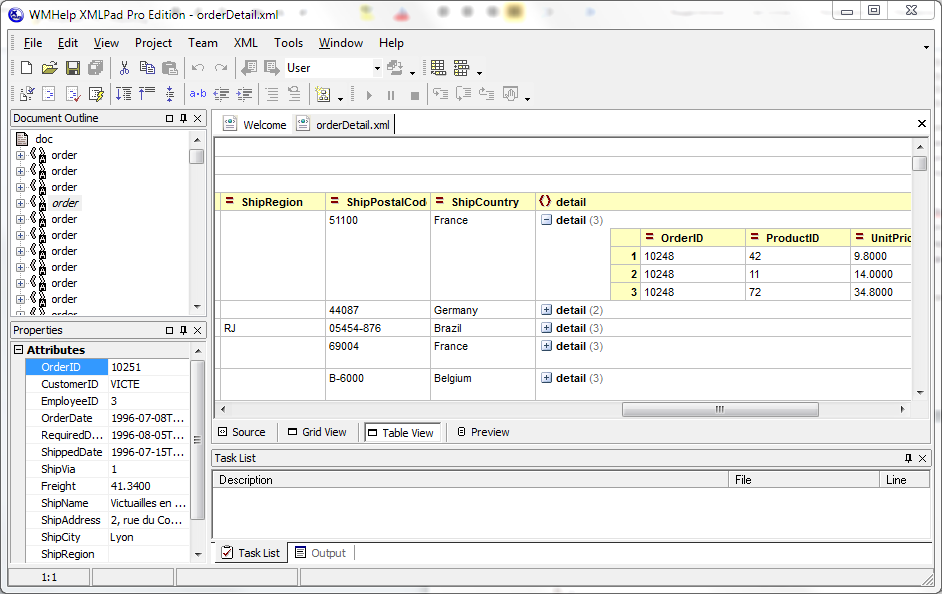
Приведённый выше пример отражает тот факт, что произвольный XML документ можно представить в виде однозначного набора вложенных таблиц. Следовательно, вместо определения проекций для извлечения табличных данных, мы можем автоматически построить соответствующий набор для любого XML документа и использовать его в запросе SQL, применяя детальное соединение для преобразования данных к требуемому виду. Эта идея появилась у автора при написании табличного представления для XmlPad [9] и через какое-то время была реализована в QueryMachine. Ниже будет показано, что этот способ извлечения таблиц является более простым, чем использование оператора XMLTable и позволяет писать компактные и простые запросы.
Чтобы извлечь данные из XML документа в QueryMachine достаточно использовать имя файла с префиксом XML. Полученная таблица будет сгруппирована, как описано выше, или содержать всего одну строку и набор колонок, соответствующий каждому узлу преобразуемой последовательности, если группировку выполнить невозможно. При этом корневой элемент документа (но не атрибуты корневого элемента) отбрасывается. Кроме того, QueryMachine автоматически определяет тип данных каждого поля, предполагая, что исходный XML документ придерживается форматов данных определенных в [10].
Например, следующий запрос сформирует таблицу Orders по файлу OrderDetail.xml:
SELECT * FROM XML:OrderDetail |
Результатом запроса будет представление, состоящее из полей для атрибутов элемента order, и поля detail в котором будет находиться экземпляр класса XmlNodeList – список дочерних элементов detail каждого элемента order. Чтобы выбрать все строки таблицы Order Details, записанные в файл, используем детальное соединение:
SELECT t.* FROM XML:OrderDetail AS o, TABLE o.detail AS t |
При выполнении этого запроса, QueryMachine сначала трансформирует в таблицу записи orders аналогично предыдущему запросу, затем трансформирует каждый получившийся список элементов из поля detail в отдельную детальную таблицу, после чего строит декартово произведение записей мастер таблицы на объединение множества строк каждой детальной таблицы. Таким образом, в QueryMachine трансформация XML документа происходит по мере необходимости, что обеспечивает приемлемую производительность на больших объемах данных.
Чуть более сложный запрос позволяет выбрать из файла OrderDetail.xml агрегированное количество продукции и общую стоимость по заказам в разрезе покупателя и номенклатуры:
SELECT @CustomerID, @ProductID, SUM(@Quantity) AS Quantity, SUM(@Quantity * @UnitPrice) AS Total
FROM XML:OrderDetail AS o, TABLE o.detail AS t GROUPBY @CustomerID, @ProductID |
Обратим внимание, что наш запрос не требует объявления типов данных для полей, поскольку QueryMachine определяет их тип автоматически. Названия полей соответствующих атрибутам элементов имеют префикс «@» (коммерческое at) для того, чтобы в случае обработки элемента содержащего совпадающие по названию атрибуты и дочерние элементы их можно было бы различать.
Аналогичный запрос, выполняющийся в СУБД Оракул с помощью оператора XMLTable, требует использования XQuery и выглядит примерно так:
SELECT CustomerID, ProductID, SUM(Quantity) AS Quantity,
SUM(Quantity * UnitPrice) AS Total
FROM XMLTable(
'for $o in doc("orderDetail.xml")/doc/orderfor $d in $o/detail return
<row CustomerID="{$o/@CustomerID}"
ProductID="{$d/@ProductID}"
Quantity="{$d/@Quantity}"
UnitPrice="{$d/@UnitPrice}"/>'
PASSING OBJECT_VALUE
COLUMNS CustomerID VARCHAR2(5) PATH '@CustomerID',
COLUMNS ProductID NUMBER PATH '@ProductID',
COLUMNS Quantity NUMBER PATH '@Quantity',
COLUMNS UnitPrice NUMBER PATH '@UnitPrice')
GROUPBY CustomerID, ProductID |
Здесь, чтобы не использовать XMLTable два раза, отдельно для таблицы Orders и отдельно для Order Detail, мы выполняем декартово произведение с помощью XQuery и формируем набор промежуточных элементов row, которые оператором XMLTable преобразуем в таблицу и далее средствами SQL выполняем агрегирование и группировку. С точки зрения автора, второй запрос более сложен и менее понятен.
Механизм извлечения табличных данных QueryMachine может использоваться совместно с фильтрацией исходного XML документа (или произвольного фрагмента документа) с помощью выражений XPath. Для этого используется встроенная функция $extract, аргументом которой может быть имя XML документа, ссылка на колонку таблицы или произвольное вычисляемое выражение. Например, чтобы выбрать из рассматриваемого нами файла данных содержимое таблицы Order Details, достаточно выполнить следующий запрос:
SELECT * FROMTABLE $extract(XML:orderDetail, '//detail') |
Рассмотрим более сложный пример. Предположим, что мы имеем набор XML файлов содержащих заказы следующего вида:
<po:purchaseOrder orderDate="2001-01-01" xsi:schemaLocation="http://www.ibm.com PurchaseOrder.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:po="http://www.ibm.com"> <shipTo country="US"> <name>Alice Smith</name> <street>125 Maple Street</street> <city>Mill Valley</city> <state>CA</state> <zip>90952</zip> </shipTo> <billTo country="US"> <name>Robert Smith</name> <street>8 Oak Avenue</street> <city>Old Town</city> <state>PA</state> <zip>95819</zip> </billTo> <po:comment>Hurry, my lawn is going wild!</po:comment> <items> <item partNum="872-AA"> <productName>Lawnmower</productName> <quantity>1</quantity> <USPrice>148.95</USPrice> <po:comment>Confirm this is electric</po:comment> </item> ... <item partNum="ZXC-AB"> <productName>Chip-n-Dale dancer</productName> <quantity>1</quantity> <USPrice>149.99</USPrice> <po:comment>For one hour only!</po:comment> </item> </items> </po:purchaseOrder> |
Приведенный выше файл purchaseOrder.xml – это стандартный пример, используемый компанией IBM для WebSphere.
Далее, предположим, что нам требуется выбрать общую сумму заказов, имеющих конкретный partNum и адресованных получателю, имя которого начинается с Alice. Используя функцию $extract и возможность использовать группы файлов в качестве источника данных, формулируем следующий запрос:
--! <useSampleData/>
SELECT SUM(i.USPrice)
FROM XML:"purchase*.xml" p, TABLE $extract(p.node, '//shipTo/*') AS t,
TABLE $extract(p.node, '//item') AS i
WHERE t.name LIKE 'Alice%' AND i.@partNum='872-AA' |
Группа файлов XML:"purchase*.xml" в запросе отображается на таблицу p, содержащую два поля: name – имя файла и node – XML документ в виде экземпляра класса XmlDocument. Эта таблица с помощью детального соединения обрабатывается XPath выражениями, выделяющими получателя заказа из заголовка документа в таблицу t и позиции заказов как таблицу i. Результирующее множество строк является декартовым произведением строк {p} x {t} x {i} и является объединением данных всех файлов входящих в группу. После этого стандартными средствами SQL осуществляется фильтрация и агрегирование.
Кроме выражений XPath, QueryMachine так же можно использовать запросы XQuery. Выполнение запросов XQuery производиться с помощью отдельного процессора QueryMachine.XQuery детально описанного в [4]. Поддержка XQuery реализована стандартным оператором XMLQuery из спецификации XML/SQL. Этот оператор может использоваться как в части SELECT запроса SQL, так и во FROM внутри выражения TABLE. В последнем случае результаты выполнения запроса XQuery преобразуются в таблицу, так же как и при вычислении выражений XPath.
В качестве примера, рассмотрим запрос, который соберет содержимое заказов группы файлов purchaseOrder в один XML документ, добавив в каждый заказ имя файла, откуда он был прочитан.
--! <useSampleData/>
SELECT XMLRoot(
XMLElement(root,
XMLAgg(XmlQuery(
'declare variable $title as xs:string external;
for $i in //item
return
<item>
{$i/@partNum}
{$i/productName}
{$i/shipDate}
{$i/quantity}
{$i/USPrice}
<comment>
{$i/*:comment/text()}
</comment>
<filename>{$title}</filename>
</item>
' PASSING po.node, $getfilename(name) AS title))))
FROM XML:"purchaseOrder_?.xml" po |
Здесь к каждому выбранному XML документу группы, применяется запрос XQuery, трансформирующий документ к требуемому виду. Далее, полученные результаты аккумулируются в один список с помощью оператора XMLAgg обернутого в XMLRoot и XMLElement, которые порождают сам результирующий документ и его корневой элемент.
Обратим внимание, что документ и соответствующее имя файла передаются в запрос XQuery с помощью конструкции PASSING как контекст и внешняя переменная. Такая возможность является частью спецификации SQL/XML.
В заключение, приведем запрос, агрегирующий содержимое файла OrderDetail.xml при помощи оператора XmlQuery без использования детального соединения:
SELECT @CustomerID, @ProductID, SUM(@Quantity) AS Quantity,
SUM(@Quantity * @UnitPrice) AS Total
FROMTABLE XmlQuery(
'for $o in doc("orderDetail.xml")/doc/orderfor $d in $o/detail return
<row CustomerID="{$o/@CustomerID}"
ProductID="{$d/@ProductID}"
Quantity="{$d/@Quantity}"
UnitPrice="{$d/@UnitPrice}"/>')
GROUPBY @CustomerID, @ProductID |
Библиотека QueryMachine состоит из трех основных сборок: CoreServices.dll – компилятора Лисп, применяемого для динамических вычислений [4]; основной сборки QueryMachine.dll, реализующей процессор SQL и модули обработки данных; сборки Data.Remote.dll – модуль поддержки 32-битовых драйверов ADO.NET в 64-битовых приложениях. Для использования XQuery в запросах, также необходима сборка QueryMachine.XQuery.dll.
Выполнение запросов осуществляется с помощью класса DataEngine.ADO.Command, являющегося наследником стандартного класса System.Data.Common.DbCommand. Так как запросы QueryMachine выполняются в контексте вызывающего потока, класс System.Data.Common.DbConnection не используется. Регистрация и управление соединениями с ADO.NET источниками данных осуществляется классом DataEngine.DatabaseDictionary, экземпляр которого должен присваиваться свойству DatabaseDictionary класса Command при инициализации, по-аналогии со свойством Connection. SQL запросы QueryMachine допускают параметры, обозначаемые с помощью префикса & (amp):
using System.Data.Common;
using DataEngine;
using DataEngine.ADO;
...
DatabaseDictionary dictionary = new DatabaseDictionary();
dictionary.RegisterDataProvider("ORA", false, "System.Data.OracleClient", "Data Source=TNP;User ID=NORTHWND;Password=****;Unicode=True");
dictionary.RegisterDataProvider("MSSQL", false, "System.Data.SqlClient", "Data Source=.\\SQLEXPRESS;AttachDbFilename=NORTHWND.MDF;"+
"Integrated Security=True;Connect Timeout=30;User Instance=True");
Command command = new Command();
command.DatabaseDictionary = dictionary;
command.CommandText = "SELECT * FROM ORA:ORDERS NATURAL JOIN MSSQL:\"Order Details\""+
" WHERE customerid = &customerID";
command.Parameters.AddValue("&customerID", "VINET");
DbDataReader reader = command.ExecuteReader();
while (reader.Read())
{
...
}
reader.Close(); |
Здесь с помощью метода RegisterDataProvider класса DatabaseDictionary описаны соединения с сервером Oracle и SQL Server. Эти соединения назначены префиксам ORA и MSSQL соответственно. Подготовленный таким образом DatabaseDictionary передан классу Command через одноименное свойство. Далее установлено свойство CommandText, связан параметр customerID и вызван стандартный метод ExecuteReader().
Класс DatabaseDictionary так же позволяет настроить путь, в котором система будет искать файлы данных, если в запросе не указано полное имя файла. Свойство DatabaseDictionary.SearchPath содержит список каталогов, разделяемый точкой с запятой, в которых будет производиться поиск файлов.
В QueryMachine встроена функциональность, позволяющая использовать в 64-битовых приложениях 32-битовые драйвера ADO.NET. Дело в том, что многие источники данных, например Microsoft Jet 4.0, необходимый для чтения файлов Excel и формата DBF, являются драйверами OLE/DB, поддерживающими только 32-битовые приложения. Для того чтобы обеспечить возможность использования таких источников данных, QueryMachine создает отдельный 32-битовый процесс ADOHost.exe, который выполняет обращения к драйверам OLE/DB. Обмен данными между приложением, использующим QueryMachine и процессом ADOHost.exe происходит средствами System.Data.Remote по протоколу IPC. В случае, если QueryMachine используется в 32-битовом приложении, указанные драйвера вызываются напрямую.
Встроенный парсер плоских файлов для определения форматов данных, названий и типов полей использует отдельный файл настроек schema.ini, который должен располагаться в том же каталоге, что и файлы данных. По формату он совместим с schema.ini используемым Майкрософт для Text File Driver, который описан в [11]. Этот файл состоит из секций соответствующих каждому файлу и набору ключей, описывающих настройки. Например:
[1.txt]
Format=TabDelimited
ColNameHeader=True
Col1=@partNum Text
Col2=productName Text
Col3=quantity Double
Col4=USPrice Double
Col5="po:comment" Text
Col6=shipDate DateTime |
Утилита QmConsole при выполнении экспорта данных автоматически формирует настройки соответствующие выгружаемым данным. Кроме ключей, описанных в [11], файл schema.ini так же может содержать дополнительные ключи, описанные в следующей таблице.
|
|
|
|
|---|---|---|
|
NullValue |
Выделенное обозначение для пустого поля. |
нет |
|
Encapsulator |
Определяет разделитель полей, используемый в файлах формата CSV, в случаях, когда поле содержит символы разделителя и переводы строк. |
“ (quote) |
|
Escape |
Включает обработку Escape-последовательностей по соглашениям оператора LOAD DATA mySQL. Более подробное описание [12]. Значением ключа является символ, используемый в качестве escape. |
Нет |
|
SequentialProcessing |
Отменяет использование распараллеливания при чтении файла. При использовании распараллеливания не допускаются записи, состоящие из нескольких строк. По умолчанию распараллеливание используется во всех случаях, когда не включена обработка Escape-последовательностей. |
false |
Секции файла schema.ini также могут назначаться группе файлов. В этом случае в названии секции указывается шаблон, содержащий символы *(star) и ?(question).
Например, следующие настройки могут быть использованы для обработки группы лог-файлов ISA Server:
[*FWS_000.w3c] Format=TabDelimited ColNameHeader=True MaxScanRows=0 CharacterSet=ANSI NullValue=- Col1=computer Text Col2=date Text Col3=time Text Col4="IP protocol" Text Col5=source Text Col6=destination Col7="original client IP" Text Col8="source network" Text Col9="destination network" Text Col10=action Text Col11=status Text Col12=rule Text Col13="application protocol" Text Col14="bytes sent" Text Col15="bytes sent intermediate" Text Col16="bytes received" Text Col17="bytes received intermediate" Text Col18="connection time" Text Col19="connection time intermediate" Text Col20=username Text Col21=agent Text Col22="session ID" Text Col23="connection ID" Text |
Хотя библиотека QueryMachine и не является полноценной СУБД, ее архитектура в целом использует подходы, применяемые в обычных базах данных. Соответствующая теория подробно изложена в классической монографии К. Дж. Дейта [13]. Кроме того, хотелось бы отметить блог К. Фридмана [14], который содержит весьма детальное описание основных алгоритмов, использованных командой разработчиков SQL Server, и блог компании Оракул, посвященный оптимизатору СУБД Оракул [15].
Основной идеей, положенной в реализацию QueryMachine (впрочем, как и любой другой СУБД), является трансляция запроса на языке SQL в последовательность шагов, выполняющих основные реляционные операции с табличными данными, такими как проекция, отбор, соединение, агрегация, сортировка, объединение и пересечение. Поскольку соединение, объединение и пересечение являются бинарными операциями – получающееся выражение является деревом.
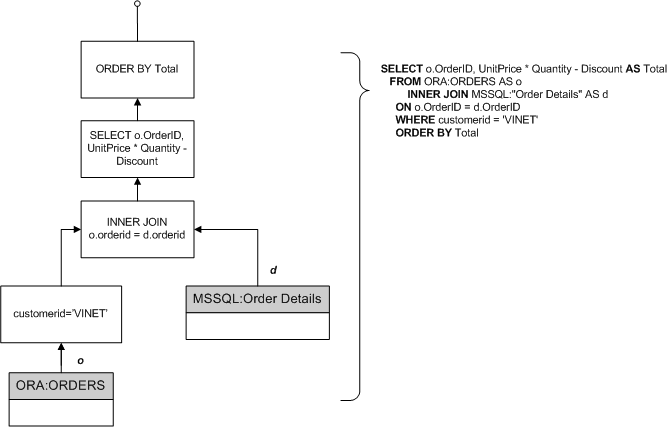
Рисунок 8
На рис.8 представлен пример запроса и соответствующее ему дерево операций. Реляционные операции на схеме представлены прямоугольниками, а порядок вычислений – стрелками. Для упрощения понимания, вычисления можно представлять как конвейер, на каждом шаге которого обрабатывается промежуточная таблица. То есть, возьмем таблицу Orders, применим к ней отбор, получившуюся таблицу соединим с Order Details, и так далее.
В действительности, передавать данные между операциями в виде таблиц неправильно, так как многие операции подразумевают потоковую обработку. Например, при выполнении отбора мы последовательно читаем исходную таблицу и фактически копируем в таблицу результата каждую запись, удовлетворяющую заданному критерию. Другой пример – оператор COUNT(*), который вообще отбрасывает все записи исходной таблицы, возвращая в качестве результата таблицу, содержащую единственную запись. Таким образом, получается, что буферизовать какие либо данные во многих случаях является напрасной тратой ресурсов. Более того, буферизация автоматически означает ограничение на максимальный размер обрабатываемых таблиц, поскольку количество оперативной памяти не является безграничным.
Поэтому в большинстве реализаций между узлами дерева реляционных операций передаются не таблицы целиком, а потоки их записей. При этом каждая операция, по-возможности, должна использовать стратегию отложенных вычислений. Применительно к рассмотренной выше операции отбора это означает, что мы останавливаемся и возвращаем результат всякий раз, когда находим запись, удовлетворяющую заданному условию, давая возможность вышестоящему узлу дерева операций принять решение о необходимости дальнейшей обработки.
С другой стороны, во многих случаях нам все-таки приходиться материализовывать таблицы. В основном это происходит для выполнения сортировки, заданной оператором ORDER BY, или при необходимости использования алгоритма соединения таблиц merge-join. Настоящие «взрослые» СУБД имеют возможность выполнять внешнюю сортировку, не накладывая ограничений на размер обрабатываемых таблиц, связанный с объемом доступной оперативной памяти. Например, СУБД Оракул для этой цели использует сегменты временных данных. QueryMachine не реализует внешнюю сортировку и буферизует все данные целиком, однако при выполнение merge-join, где это возможно, использует сортировку на уровне внешнего источника данных. Например, в рассматриваемом выше примере, таблицы Orders и Order Detail выбираются отсортированными по полю orderid.
Следует заметить, что на самом деле QueryMachine использует чуть более сложную схему обмена данными, которая позволяет избежать излишнего копирования при выполнении фильтрации и соединения. Обратимся к рис.8. После выполнения операции соединения и до выполнения проекции получающаяся виртуальная таблица должна содержать поля обеих соединяемых таблиц. Рассуждая прямолинейно, мы должны создать новый тип записи и скопировать туда все значения полей, поскольку на этом шаге не известно, какие из них используются в дальнейшем. Вместо этого, мы создаем особый тип записи – контейнер, содержащий всего два поля – ссылки на первоначальные записи каждой из таблиц. Таким образом, при выполнении композиции соединений мы копируем содержимое левого и правого контейнера, а не полей исходных таблиц, что позволяет нам на порядок снизить объем копируемых данных. Фильтрация, проекция и агрегирование могут обрабатывать результаты соединения таблиц, поэтому также используют контейнеры.
Механизм обмена данными между операциями в QueryMachine реализован классом Resultset, а сами операции – наследниками класса QueryNode.
public
abstract
class QueryNode
{
public QueryNode();
publicvirtualvoid Prepare();
publicabstract Resultset Get(QueryContext queryContext, object[] parameters);
public QueryNode Parent { get; }
public QueryNodeCollection ChildNodes { get; }
public QueryNode GetNodeByID(object ID);
publicobject NodeID { get; set; }
...
} |
Класс QueryNode содержит свойства Parent и ChildNodes, позволяющие строить иерархию операций, свойство NodeID, используемое для идентификации подзапросов из Lisp выражений, и основной метод Get(), возвращающий результат обработки в виде экземпляра Resultset. Класс Resultset по-существу является очередью записей, способной при необходимости буферизовать данные. Причем, заполнение этой очереди обычно производится по мере чтения данных с помощью наследника класса QueryNode.DemandProcessingContext. То есть большинство операций реализовано таким образом, что вызов метода Get() возвращает незаполненный Resultset, который на этом этапе содержит только метаданные. Далее, при попытке получить очередную запись связанный с операцией экземпляр Resultset выполняет необходимые вычисления, помещает их результат в очередь и возвращает управление. Таким образом, выполнение реляционных операций организовано в виде конвейера записей, неявно включающегося каждый раз при попытке чтения самого верхнего Resultset.
Условимся называть структуру взаимосвязанных классов QueryNodeпланом выполнения SQL запроса. Элементами плана выполнения запроса, кроме реляционных операторов, также выступают узлы – источники данных, являющиеся листьями дерева операций. Такие узлы фактически представляют в виде Resultset содержимое плоских файлов или результат выполнения запроса SQL к внешней базе данных.
Следующая таблица содержит описание элементов плана выполнения запросов, реализованных в QueryMachine:
|
|
|
|
|---|---|---|
|
AdoTableAccessor |
0 |
Представляет в виде Resultset таблицу System.Data.DataTable. |
|
DataAggregator |
1 |
Выполняет агрегацию данных для реализации SQL операторов SUM, MIN, MAX, COUNT, AVG, XmlAgg. |
|
DataCollector |
1 |
Оборачивает запись исходного Resultset в контейнер для дальнейшего использования в DataFilter, DataJoin, DataSelector, DetailJoin, UnionJoin и DataAggregator. |
|
DataConnector |
2 |
Выполняет теоретико-множественные операции соответсвующие SQL операторам UNION, UNION ALL, EXCEPT, INTERSECT. |
|
DataFilter |
1..n |
Выполняет фильтрацию данных в операторах WHERE и HAVING |
|
DataJoin |
2 |
Выполняет операцию соединения таблиц. Поддерживаются следующие алгоритмы: cartesian-join, merge-join, hash-join и distributed-join. |
|
DataProviderQueryAccessor |
0 |
Представляет в виде Resultset результат выполнения SQL запроса к внешней базе данных. SQL запрос задается в виде текстовой строки, формируемой оптимизатором. |
|
DataProviderTableAccessor |
0 |
Представляет в виде Resultset результат выполнения SQL запроса к внешней базе данных. SQL запрос строиться автоматически по заданному имени таблицы, дополнительному условию фильтрации и полям сортировки. |
|
DataSelector |
1..n |
Выполняет проекцию данных, т.е. вычисляет выражение SQL оператора SELECT. |
|
DataSorter |
1 |
Выполняет операцию сортировки, заданной SQL оператором ORDER BY или транслятором для алгоритма merge-join. |
|
DetailJoin |
2..n |
Выполняет операцию детального соединения. |
|
DualNode |
0 |
Создает «dual» таблицу (aka Oracle), содержащую одну строку и одно поле. |
|
FlatFileAccessor |
0 |
Представляет в виде Resultset файл данных или группу файлов данных по имени или маске. Возвращаемые записи содержат экземпляры System.IO.Stream |
|
TextDataAccessor |
1 |
Выполняет парсинг плоских файлов. Исходные файлы представляются в виде потоков, создаваемых FlatFileAccessor. |
|
UnionJoin |
2 |
Реализует оператор SQL-92 UNION JOIN. |
|
XmlDataAccessor |
1 |
Выполняет парсинг и преобразование в каноническую табличную форму XML файлов. Исходные файлы представляются в виде потоков, создаваемых FlatFileAccessor. |
Динамические вычисления, необходимые для выполнения отбора и проекции осуществляется встроенной Лисп-машиной аналогично реализации XQuery. На этапе трансляции части запроса SQL, соответствующие подвыражениям SELECT, WHERE (HAVING) и FROM TABLE, преобразуются в лисп-формы, которые обрабатываются узлами DataSelector, DataFilter и DetailJoin. При наличии подзапросов в операторе SQL в эти узлы также включаются соответствующие дополнительные ветви плана выполнения.
Следует заметить, что в отличие от XQuery, для SQL не нужно реализовывать механизм локальных переменных. Поэтому план выполнения запроса не требуется представлять единым функциональным выражением и каждый узел, осуществляющий вычисления, может использовать собственный экземпляр лисп-машины (класс DataEngine.CoreServices.Executive). Подробное описание используемой реализации Лиспа как платформы для динамических вычислений опубликовано в [4].
Приведенный ниже фрагмент трассировки получен с помощью метода QueryNode.Dump() и позволяет увидеть фактический план выполнения запроса показанного на рис.8.
DataSorter "Total" DataSelector >o.OrderID >[Total]:(- (* UnitPrice Quantity) Discount) DataFilter (eqx o.customerid "VINET") DataJoin Inner,o.OrderID == d.OrderID DataCollector DataProviderTableAccessor System.Data.OracleClient, ORDERS (eqx o.customerid "VINET") DataCollector DataProviderTableAccessor System.Data.SqlClient, [ORDER DETAILS] |
Корневым узлом рассматриваемого плана выполнения запроса является экземпляр класса DataSorter, осуществляющий сортировку результатов по возрастанию поля Total. Дочерним элементом этого узла является экземпляр класса DataSelector, формирующий таблицу результата и вычисляющей лисп-форму для Total. Подчиненным узлом для DataSelector является узел DataFilter, осуществляющий отбор результатов соединения таблиц, выполняемых шагом ниже узлом DataJoin. Этот узел имеет две дочерние ветви, в каждой из которых находится экземпляр DataCollector подготавливающий контейнерные записи. Терминальными узлами плана выполнения являются экземпляры DataProviderTableAccessor осуществляющие чтение данных из СУБД Oracle и SQL Server.
Обратим внимание, что отбор записей осуществляется после выполнения соединения, что на первый взгляд является крайне неэффективным решением. Однако на самом деле, такой же критерий отбора присутствует и в качестве параметра соответствующего узла DataProviderTableAccessor. Этот отбор реализуется генерацией условия в запросе SQL к источнику данных и таким образом уже перед выполнением соединения данные таблицы Orders удовлетворяют заданному критерию. Описанная ситуация происходит из-за особенностей оптимизатора, который с целью упрощения реализации вместо преобразования исходных логических выражений производит их анализ, и, где это возможно, накладывает дополнительные ограничения на сами источники данных. Причем, эти ограничения могут быть более слабыми, чем первоначальное условие, поэтому в общем случае и требуется двойная проверка условий: на источнике данных и в самой QueryMachine. Некоторая избыточность этого подхода с лихвой компенсируется уменьшением объема обрабатываемых данных и возможностью косвенно использовать индексацию на стороне СУБД.
В целом подготовку и выполнение запроса SQL QueryMachine можно разделить на следующие основные фазы:
Детальное описание выбранного внутреннего представления семантики, механизмов разбора и трансляции выходит за рамки настоящей статьи. QueryMachine использует таблично-управляемый восходящий алгоритм разбора на основе грамматики LR(1), опубликованной [5]. Применяемый алгоритм разбора подробно описан в [16]. Результатом разбора оператора SQL является экземпляр класса Notation, который последовательно обрабатывается на этапе оптимизации и связывания, а затем транслируется в план выполнения запроса. Особенностью реализации является то, что внутреннее представление запроса в любой момент может быть преобразовано обратно в SQL с помощью класса SqlWriter. При этом указания оптимизатора и связи отображаются с помощью специального синтаксиса. QueryMachine не имеет доступа к внутренней статистике и индексам таблиц, поэтому применяемый оптимизатор является ориентированным на правила (rule-based optimizer) и выполняет следующие функции:
Таким образом, результатом работы оптимизатора является трансформированный SQL запрос, содержащий дополнительные реквизиты, управляющие его трансляцией. Следует заметить, что в настоящий момент QueryMachine не делегирует подзапросы на источники данных. То есть, либо весь запрос будет выполнен источником данных, либо будет сгенерирован план выполнения, обрабатывающий все подзапросы, даже если какие-либо из них могли быть выполнены на уровне СУБД.
Для последующей обработки запроса QueryMachine перед выполнением трансляции осуществляет связывание подзапросов, которое сводится к анализу и замене в подзапросах полей внешних (относительно подзапроса) таблиц на параметры. Следующий рисунок показывает результат оптимизации и связывания запроса, содержащего коррелирующий подзапрос:

Рисунок 9
Здесь мы видим, что ссылка на колонку o.OrderID из внешнего запроса после связывания заменена на позиционный параметр $1, определяемый реквизитом bind. Подготовленный таким образом запрос будет транслирован в приведенный ниже план выполнения. Как видно из трассировки, узел DataFilter, соответствующий основному запросу, также содержит дополнительную ветвь для подзапроса. В лисп-форме он идентифицируется атомом _SQuery2. Функция squery, вызываемая для каждой строки основного запроса, находит нужную ветвь плана выполнения по свойству NodeID и вызывает подзапрос с заданными значениями параметров, возвращая результат в виде экземпляра класса Resultset в функцию exists,которая и проверяет условие отбора. Реквизит оптимизатора filter при трансляции накладывает на источник данных дополнительное условие фильтрации.
Также отметим, что классом ResultsetCache в QueryMachine реализовано внутреннее кэширование результатов выполнения подзапросов. Иногда этот механизм существенно ускоряет обработку, однако все равно уступает методу, применяемому в «больших» СУБД – преобразованию исходного запроса с использованием соединения semi-join [14].
DataSelector
*
DataFilter (exist (squery _SQuery2 (list o.OrderID)))
DataCollector
DataProviderTableAccessor System.Data.SqlClient,[ORDERS]
DataSelector
>OrderID
DataFilter (eqx d.OrderID (pref 1))
DataCollector
DataProviderTableAccessor System.Data.SqlClient,[ORDER DETAILS] (eqx d.OrderID (pref 1)) |
Поскольку на стадии оптимизации мы не извлекаем из используемых СУБД метаданные, выбор алгоритма соединения происходит непосредственно узлом DataJoin при вызове метода Get(), который использует один из следующих реализованных алгоритмов: cartesian-join, merge-join, hash-join и distributed-join.
Метод distributed-join придуман автором для тех случаев, когда требуется соединить очень большую и сравнительно малую таблицы, причем большая таблица находится в СУБД, поддерживающей SQL. Например, требуется соединить большую таблицу Оракул, содержащую пару миллионов записей, с файлом данных, представляющим собой список ключей в несколько сотен записей. Использование любого из традиционных алгоритмов требует как минимум одного полного прохода по большой таблице, что является совершенно неприемлемым. Вместо этого QueryMachine разбивает записи малой таблицы на блоки по 64 записи, с помощью SQL выбирает для каждого блока соответствующие критерию соединения записи большой таблицы, а затем соединяет полученные данные картезианским (декартовым) произведением.
Выбор алгоритма соединения происходит по следующим правилам:
Описанная выше стратегия нуждается в некоторых пояснениях. Во-первых, для выполнения соединений в наихудшем случае всегда требуется буферизация, так как декартово произведение с последующей фильтрацией на существенных объемах данных работает неприемлемо медленно (можно принять, что не работает вообще). Во-вторых, учитывая, что в QueryMachine не реализована внешняя сортировка, метод merge-join целесообразно использовать только если одна из таблиц уже отсортирована источником данных; во всех остальных случаях более предпочтителен hash-join.
Оценка размера таблицы, хранящейся в СУБД, требует учета специфики каждой конкретной базы данных. Действительно, самый очевидный способ – выполнить запрос SELECT COUNT(*) FROM… является самым неправильным, так как во многих СУБД будет требовать сканирования всей таблицы, и таким образом сильно замедлит обработку (в частности так работает Оракул). Оценка размера таблиц по метаданным или статистике оптимизатора требует относительно сложных настроек и специальных полномочий доступа к СУБД, что так же не всегда возможно. Поэтому QueryMachine не пытается вычислить точное количество записей в каждой из таблиц, а лишь оценивает, что одна таблица существенно больше другой.
Идея проста. Практически для каждой СУБД существует синтаксис SQL, позволяющий ограничить количество записей, обрабатываемых запросом. Поэтому, мы можем попытаться подсчитать записи в таблице, ограничив их максимально возможное количество. Например:
-- Oracle
SELECT
COUNT(*) FROMTableWHERE ROWNUM < 1000 |
Далее, мы последовательно пробуем пороги в 10000, 50000 и 150000 записей для каждой из таблиц, используемых в соединении, и либо устанавливаем, что одна из них существенно больше другой, либо считаем, что обе таблицы большие и наш метод не приемлем. При этом, в случае, когда только одна из таблиц поддерживает SQL, для оценки размера внутренней таблицы мы просто буферизуем ее содержимое и определяем точное количество записей.
Специфические настройки QueryMachine для каждого источника данных хранятся в конфигурационном файле SQLX.Config.xml. Этот файл содержит небольшое количество настроек, которые невозможно извлечь из провайдера ADO.NET. Следующая таблица документирует используемые элементы настроек:
|
|
|
|
|---|---|---|
|
qualifer |
Символ-разделитель компонентов имени в SQL. Используется для генерации составных имен ([каталог[.схема].]имя_таблицы) |
. (точка) |
|
stringSeparator |
Символ-разделитель строковых констант |
' (апостроф) |
|
leftQuote |
Символ, обозначающий начало идентификатора (имени). Используется при необходимости в зависимости от метаданных, предоставляемых провайдером ADO.NET |
[ (левая квадратная скобка) |
|
rightQuote |
Символ, обозначающий конец идентификатора (имени) |
] (правая квадратная скобка) |
|
parameterMarkerFormat |
Формат именованных параметров в запросе SQL, если именованные параметры поддерживаются. Значением параметра является строка форматирования для функции String.Format |
@{0} |
|
dateFormat |
Формат констант для типа System.DateTime, используемых в запросе SQL. QueryMachine преобразует все даты методом ToString("u") после чего они форматируются вызовом функции String.Format со строкой форматирования, указанной в параметре |
{{ts '{0}'}} |
|
rowCountQuery |
Запрос для оценки размера таблиц. Если параметр не указан – источник данных не используется для distributed-join. Значением параметра является строка форматирования для функции String.Format. Первый параметр – количество записей, второй – имя таблицы, сформатированное в соответствии с используемым диалектом SQL |
SELECT COUNT(*) FROM |
|
updateBatchSize |
Размер пакета при блочной записи |
100 |
Файл настроек используется классом DataProviderHelper, предназначенным для форматирования литералов и идентификаторов в соответствии с диалектом SQL, поддерживаемым заданным провайдером ADO.NET. Если система не находит указанный файл в каталоге сборки QueryMachine.dll, загружается файл из ресурса, содержащий настройки для Oracle, MSSQL, MS JET 4.0 и MySQL. Указанная информация используется совместно с метаданными, предоставляемыми провайдером через вызовы GetSchema("DataSourceInformation") и GetSchema("ReservedWords").
QueryMachine изначально задумывался как инструмент для извлечения табличных данных из XML файлов для XMLPad. Однако в процессе разработки, на взгляд автора, получилась целая платформа, способная в комбинации с XQuery решать разнообразные задачи. Не претендуя на какие-то инновации, хотелось бы отметить, что представленная реализация является весьма компактным и функциональным решением и практически не имеет аналогов.