16 аппаратных потоков — полёт нормальный.
На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
Выход запланирован на вторую половину следующего года. Дизайн уже готов.
Здравствуйте, remark, Вы писали:
R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов.
Я где то читал про 1.9 млрд.
R> Новый северный мост QuickPath (бывший CSI).
Не северный мост, а часть процессора. Как у AMD. Даже по твоей ссылке об этом сказано.
R>Выход запланирован на вторую половину следующего года.
На 2009. Если ты не понял — Nehalem будет производится по 32 нм технологии, а пока даже 45 нм не продается.
... << RSDN@Home 1.2.0 alpha rev. 725 on Windows Vista 6.0.6000.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, remark, Вы писали:
R>>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов.
AVK>Я где то читал про 1.9 млрд.
R>> Новый северный мост QuickPath (бывший CSI).
AVK>Не северный мост, а часть процессора. Как у AMD. Даже по твоей ссылке об этом сказано.
R>>Выход запланирован на вторую половину следующего года.
AVK>На 2009. Если ты не понял — Nehalem будет производится по 32 нм технологии, а пока даже 45 нм не продается.
... могу сказать только то, что я сам ничего не выдумывал.
Вот цитата из Tech Report, датированная 18 сентября 2007, исходящая от сотрудника Intel:
The design is now complete, and Otellini claimed it's on track for delivery in the second half of 2008. In fact, he displayed a wafer of Nehalem chips and reported that each chip will be comprised of approximately 731 million transistors.
Здравствуйте, remark, Вы писали:
R>16 аппаратных потоков — полёт нормальный. R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>Выход запланирован на вторую половину следующего года. Дизайн уже готов.
R>Оригинал здесь. Правда подробностей там не много.
R>
Ну и что?
Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
Здравствуйте, iZEN, Вы писали:
R>>16 аппаратных потоков — полёт нормальный. R>>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>>Выход запланирован на вторую половину следующего года. Дизайн уже готов.
R>>Оригинал здесь. Правда подробностей там не много.
ZEN>Ну и что? ZEN>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
Ну как это что?!
Разве на T1 Windows работает?
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, iZEN, Вы писали:
ZEN>Здравствуйте, remark, Вы писали:
R>>16 аппаратных потоков — полёт нормальный. R>>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>>Выход запланирован на вторую половину следующего года. Дизайн уже готов.
R>>Оригинал здесь. Правда подробностей там не много.
R>>
ZEN>Ну и что? ZEN>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
Это процессор другого класса. Ты никогда не купишь в супермаркете компьютер с UltraSPARC T1.
З.ы. у Cisco уже некоторое время есть процессор с 188 ядрами. НО это специализированные packet-processing RISC ядра. Мне от этого не холодно и не горячо.
Здравствуйте, eao197, Вы писали:
iZEN>>Ну и что? iZEN>>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
E>Ну как это что?! E>Разве на T1 Windows работает?
А зачем нужна Windows?
У меня на обоих домашних компьютерах FreeBSD 6.2-STABLE. У сестры — Xubuntu Linux.
Sun UltraSPARC T1 поддерживает FreeBSD.
Здравствуйте, iZEN, Вы писали:
ZEN>Здравствуйте, eao197, Вы писали:
iZEN>>>Ну и что? iZEN>>>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
E>>Ну как это что?! E>>Разве на T1 Windows работает? ZEN>А зачем нужна Windows? ZEN>У меня на обоих домашних компьютерах FreeBSD 6.2-STABLE. У сестры — Xubuntu Linux. ZEN>Sun UltraSPARC T1 поддерживает FreeBSD.
Ну? И что? У тебя дома стоит Niagara?
Можешь ещё себе домой купить Cisco Packet Processor. Действительно, Windows же нам не нужна! Поставить себе Cisco IOS XR.
Здравствуйте, remark, Вы писали:
R>Ну? И что? У тебя дома стоит Niagara? R>Можешь ещё себе домой купить Cisco Packet Processor. Действительно, Windows же нам не нужна! Поставить себе Cisco IOS XR.
Да не в том дело. Просто не надо ограничивать себя како-то одной операционной системой.
Windows ещё надо допиливать до такого состояния, чтобы она смогла поддержать работу 8 ядер, ведь в пока что мультипроцессорное ядро Windows умеет хорошо работать только с четырьмя ядрами.
Здравствуйте, iZEN, Вы писали:
ZEN>Здравствуйте, remark, Вы писали:
R>>Ну? И что? У тебя дома стоит Niagara? R>>Можешь ещё себе домой купить Cisco Packet Processor. Действительно, Windows же нам не нужна! Поставить себе Cisco IOS XR.
ZEN>Да не в том дело. Просто не надо ограничивать себя како-то одной операционной системой.
ZEN>Windows ещё надо допиливать до такого состояния, чтобы она смогла поддержать работу 8 ядер, ведь в пока что мультипроцессорное ядро Windows умеет хорошо работать только с четырьмя ядрами.
Они уже серьёзно доработали ядро для Vista. И можно с уверенностью сказать, что сейчас они работают над этим дальше.
Имхо основная проблема не в ОС. ОС и сейчас имеют делать все основные необходимые функции касательно многоядерных процессоров. Основные проблема, что надо весь *существующий* софт переделывать, и весь новый софт делать с поддержкой многоядерности. И сейчас это практически никто не умеет делать...
А ОС... ну а что ОС? В ней никогда не сделают ничего такого, что магически заставит существующую "одноядерную" программу магически масштабироваться.
R>А ОС... ну а что ОС? В ней никогда не сделают ничего такого, что магически заставит существующую "одноядерную" программу магически масштабироваться.
ОС — весьма узкое место. Сколько-сколько стоит 32-процессорная винда? ОС ведь такая же программа, как и другие, только побольше. Вон, Intel 16 потоков маскирует под двумя процессорами скорее всего только потому, что современные ОСи до 16 ядер не доросли
Здравствуйте, Mamut, Вы писали:
R>>А ОС... ну а что ОС? В ней никогда не сделают ничего такого, что магически заставит существующую "одноядерную" программу магически масштабироваться.
M>ОС — весьма узкое место. Сколько-сколько стоит 32-процессорная винда? ОС ведь такая же программа, как и другие, только побольше. Вон, Intel 16 потоков маскирует под двумя процессорами скорее всего только потому, что современные ОСи до 16 ядер не доросли
"Современные ОСи" не входят в TOP500?
Не надо говорить за всех, хорошо.
Здравствуйте, iZEN, Вы писали:
ZEN>Windows ещё надо допиливать до такого состояния, чтобы она смогла поддержать работу 8 ядер, ведь в пока что мультипроцессорное ядро Windows умеет хорошо работать только с четырьмя ядрами.
А ссылочку какую-нибудь по теме можно? Откуда это могическое число — 4? Что с ней такого происходит при переходе к большему количеству?
Здравствуйте, remark, Вы писали:
R>16 аппаратных потоков — полёт нормальный. R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>
Здравствуйте, _Obelisk_, Вы писали:
_O_>Здравствуйте, remark, Вы писали:
R>>16 аппаратных потоков — полёт нормальный. R>>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
_O_>Вот ёлки-палки, а я только 4-х ядерный проц купил
Я думаю, это ничего страшного
Во-первых, когда он только появится, то он будет дорогой. А во-вторых, как заметил Michael Suess, кол-во ядер стало удваиваться каждый год с момента появления первого двухядерного процессора. А теперь так похоже вообще каждый год оно будет учетверяться. Так что всё равно не угонишься
Т.е. сейчас это как раньше пытаться гнаться за самым быстрым процессором. Купишь самый быстрый, а уже анонсирован выход ещё более быстрого...
Здравствуйте, Стэн, Вы писали:
С>Здравствуйте, iZEN, Вы писали:
iZEN>>Windows ещё надо допиливать до такого состояния, чтобы она смогла поддержать работу 8 ядер, ведь в пока что мультипроцессорное ядро Windows умеет хорошо работать только с четырьмя ядрами. С>А ссылочку какую-нибудь по теме можно? Откуда это могическое число — 4? Что с ней такого происходит при переходе к большему количеству?
Ссылочку привести не могу, потому что я не видел 8-процессорных серверов на Windows.
Здравствуйте, iZEN, Вы писали:
ZEN>Ссылочку привести не могу, потому что я не видел 8-процессорных серверов на Windows.
А откуда знаешь, что более чем с 4-мя ядрами не работает нормально?
Здравствуйте, Стэн, Вы писали:
С>Здравствуйте, iZEN, Вы писали:
ZEN>>Ссылочку привести не могу, потому что я не видел 8-процессорных серверов на Windows. С>А откуда знаешь, что более чем с 4-мя ядрами не работает нормально?
http://www.coversant.net/Coversant/Blogs/tabid/88/EntryID/10/Default.aspx
Chris Mullins описывает как они тестировали свой IM сервер под Windows на системе с 16-ю процессорами Itanium2.
Сервер полностью написан на C# и на такой системе держал до 500000 клиентских tcp соединений. Да, не каждая ось похвастается выдерживанием такой нагрузки
Здравствуйте, remark, Вы писали:
R>16 аппаратных потоков — полёт нормальный. R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>Выход запланирован на вторую половину следующего года. Дизайн уже готов.
R>Оригинал здесь. Правда подробностей там не много.
R>
Здравствуйте, remark, Вы писали:
R>Здравствуйте, anton_t, Вы писали:
_>>Улыбнуло: _>>
640 cores should be enough for anybody!
R>По некоторым авторитетным прогнозам это нас ждёт в очень ближайшем будущем. R>Так что лучше не улыбаться, а учиться создавать масштабируемые системы R>
Учиться?
У меня не получается писать однопоточные приложения с 2000 года -- все мои приложения содержат больше одного потоа выполнения.
Что я делаю не так?
Диспетчеризация потоков выполнения на нескольких физических процессорах -- это прерогатива исключительно операционной системы и/или VM. Так что перекладывать всю ответственность за эффективность функционирования приложения на прикладного программиста -- моветон.
R>>По некоторым авторитетным прогнозам это нас ждёт в очень ближайшем будущем. R>>Так что лучше не улыбаться, а учиться создавать масштабируемые системы R>>
ZEN>Учиться?
Да, батен'ка: учиться, учиться и еще раз учиться!
ZEN>У меня не получается писать однопоточные приложения с 2000 года -- все мои приложения содержат больше одного потоа выполнения. ZEN>Что я делаю не так?
многопоточные приложения != масштабируемые системы
ZEN>Диспетчеризация потоков выполнения на нескольких физических процессорах -- это прерогатива исключительно операционной системы и/или VM. Так что перекладывать всю ответственность за эффективность функционирования приложения на прикладного программиста -- моветон.
Да, программистам давно пора снять с себя всяку ответственность за глючность, ресурсоемкость и тормознутось программ. Поддерживаю!
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, iZEN, Вы писали:
ZEN>Здравствуйте, remark, Вы писали:
R>>Здравствуйте, anton_t, Вы писали:
_>>>Улыбнуло: _>>>
640 cores should be enough for anybody!
R>>По некоторым авторитетным прогнозам это нас ждёт в очень ближайшем будущем. R>>Так что лучше не улыбаться, а учиться создавать масштабируемые системы R>>
ZEN>Учиться? ZEN>У меня не получается писать однопоточные приложения с 2000 года -- все мои приложения содержат больше одного потоа выполнения. ZEN>Что я делаю не так?
Это совершенно ничего не значит. Вполне возможно, что эти программы будут работать значительно медленее на многопроцессорной машине, чем на однопроцессорной. Количество потоков тут совершенно ни при чём.
Есть две совершенно разные вещи, между которыми пропасть. Их надо строго разделять.
1. Многопоточность на одном ядре
2. Многопоточность на множестве ядер
Первое — это просто для удобства программирования и/или для скрытия латентности блокирующих операций. Это то, что умеет значительное кол-во людей. И то, что мы делали десятилетиями.
Второе — производительность и масштабируемость.
Первое никак автоматически не перейдёт во второе.
ZEN>Диспетчеризация потоков выполнения на нескольких физических процессорах -- это прерогатива исключительно операционной системы и/или VM. Так что перекладывать всю ответственность за эффективность функционирования приложения на прикладного программиста -- моветон.
Это всё равно, что сказать "TCP/IP стек — прерогатива операционной системы, поэтому можно *любым* образом использовать API сокетов, и ты получишь эффективную программу". Бред! Надо много знать про реализацию сокетов, TCP/IP, возможности и засады ОС, иметь достаточно опыта, приложить много усилий и времени и тогда получится эффективная работа с сокетами.
А если я сделаю поток-на-сокет, и буду отправлять и принимать по одному байту через блокирующие операции, то получится ***ня.
При этом я могу возмущаться "ну у меня же много сокетов и много потоков, почему это работает медленно и не масштабируется! Наверное баг где-то в ОС"
Здравствуйте, remark, Вы писали:
R>>>По некоторым авторитетным прогнозам это нас ждёт в очень ближайшем будущем. R>>>Так что лучше не улыбаться, а учиться создавать масштабируемые системы R>>>
iZEN>>Учиться? iZEN>>У меня не получается писать однопоточные приложения с 2000 года -- все мои приложения содержат больше одного потоа выполнения. iZEN>>Что я делаю не так? R>Это совершенно ничего не значит. Вполне возможно, что эти программы будут работать значительно медленее на многопроцессорной машине, чем на однопроцессорной. Количество потоков тут совершенно ни при чём.
А что "причём"?
Семантики вычислительного ресурса (в данном случае, физического процессора, их множественности) и нитей вычисления определены задолго до появления многопроцессорных машин на столах пользователей. Все программисты писали многонитиевые приложения задолго до использования реальной многозадачности, эмулируя её на однопроцессорной машине в режиме вытесняющей многозадачности (справедливости ради, серверные приложения работали всегда в реальной многопроцессорной среде, на машинах с количеством процессоров больше, чем один).
И фдрук, после того, как многоядерные машины появились на столах пользователей, все очень быстро поняли, что не умеют писать масштабируемые приложения.
Не бывает! Такого не может быть. Лапшу на уши можно вешать долго и непринуждённо только в окончательно зашоренной атмосфере бытия, но не в IT-отрасли.
R>Есть две совершенно разные вещи, между которыми пропасть. Их надо строго разделять. R>1. Многопоточность на одном ядре R>2. Многопоточность на множестве ядер
Нет. Идиомы везде одни и те же: есть один или несколько процессоров, есть одна или несколько нитей -- их нужно раскидать равномерно по ядрам, чтобы ни одно ядро не простаивало, и, в то же время, обеспечить отклик системы на интерактивное взаимодействие. Всё прекрасно известно и прекрасно отработано на высоком уровне с начала 80-х (если не раньше на IBM/360). Задача распределения вычислительных потоков, их динамичская приоритезация и диспетчеризация -- это задача шедулера, оторый -- часть операционной системы!
Если в MS не могут сделать систему, которая эффективно работает на столах пользователей с 4 и более ядрами, то это, очевидно, роблемы Microsoft, а не прикладных программистов.
R>Первое — это просто для удобства программирования и/или для скрытия латентности блокирующих операций. Это то, что умеет значительное кол-во людей. И то, что мы делали десятилетиями.
Определённо да.
R>Второе — производительность и масштабируемость.
Проблемы негров не волнуют белых людей?
R>Первое никак автоматически не перейдёт во второе.
А должно. По идеям, которые нам вдалбливали с детства.
iZEN>>Диспетчеризация потоков выполнения на нескольких физических процессорах -- это прерогатива исключительно операционной системы и/или VM. Так что перекладывать всю ответственность за эффективность функционирования приложения на прикладного программиста -- моветон.
R>Это всё равно, что сказать "TCP/IP стек — прерогатива операционной системы, поэтому можно *любым* образом использовать API сокетов, и ты получишь эффективную программу". Бред! Надо много знать про реализацию сокетов, TCP/IP, возможности и засады ОС, иметь достаточно опыта, приложить много усилий и времени и тогда получится эффективная работа с сокетами.
Это не бред. И TCP/IP здесь совершенно не к месту. Общие задачи планирования вычислений часто решаются на прикладном уровне, но нельзя позволять прикладному уровню отбирать системные ресурсы у уровня аппаратных абстракций, иначе придём к кооперативной многозадачности.
R>А если я сделаю поток-на-сокет, и буду отправлять и принимать по одному байту через блокирующие операции, то получится ***ня. R>При этом я могу возмущаться "ну у меня же много сокетов и много потоков, почему это работает медленно и не масштабируется! Наверное баг где-то в ОС"
А что, это нельзя сделать на однопроцессорной машине?
я почему-то сразу понял о чем они (remark, eao197). Они о том, что interlocked/mutexes могут убить производительность _всей_ системы, а не твоего приложения. Даже не убить, а просто сделать так, что у тебя _не будет_ этих нескольких ядер, а все будет работать, как будто оно у тебя одно. Из-за того, что трэды будут постоянно сбрасывать кеши проца и висеть на объектах синхронизации. При многоядерности вероятность столкновения трэдов гораздо больше. Мы тут не про affinity говорим и не про ручной шедулинг. Это и так понятно, что ОС может лучше разрулить.
Здравствуйте, iZEN, Вы писали:
ZEN>Нет. Идиомы везде одни и те же: есть один или несколько процессоров, есть одна или несколько нитей -- их нужно раскидать равномерно по ядрам, чтобы ни одно ядро не простаивало, и, в то же время, обеспечить отклик системы на интерактивное взаимодействие. Всё прекрасно известно и прекрасно отработано на высоком уровне с начала 80-х (если не раньше на IBM/360).
Только вот более 8-ми ядер в SMP бывает крайне редко. Дальше либо NUMA, либо вообще кластеры. Шедулер конечно что то там под NUMA сможет подогнать, но эффективно задействовать ресурсы системы это вряд ли поможет. Поэтому конкретное приложение должно это самое NUMA учитывать, например при помощи TCP affinity, как это делает сиквел.
Здравствуйте, remark, Вы писали:
R>16 аппаратных потоков — полёт нормальный. R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре.
Наткнулся сегодня на блог Timothy Mattson, одного из Intel-овских инженеров. Вот его интересные соображения о параллельном программировании и многоядерности:
We need to spend less time creating new languages and more time making the languages we have work. This is why anytime I hear someone talk about their great new language, I pretty much ignore them. Tell me how to make OpenMP work. Tell me how to fix MPI so it runs with equal efficiency on shared memory and distributed memory systems. Help me figure out how to get pthreads and OpenMP components to work together. Help me understand solution frameworks so high level programmers can create the software they need without becoming parallel algorithm experts. But don’t waste my time with new languages. With hundreds of languages and API’s out there, is anyone really dumb enough to think “yet another one” will fix our parallel programming problems?
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, eao197, Вы писали:
E>Вот, для затравки, цитата из последнего поста: E>
E>We need to spend less time creating new languages and more time making the languages we have work. This is why anytime I hear someone talk about their great new language, I pretty much ignore them. Tell me how to make OpenMP work. Tell me how to fix MPI so it runs with equal efficiency on shared memory and distributed memory systems. Help me figure out how to get pthreads and OpenMP components to work together. Help me understand solution frameworks so high level programmers can create the software they need without becoming parallel algorithm experts. But don’t waste my time with new languages. With hundreds of languages and API’s out there, is anyone really dumb enough to think “yet another one” will fix our parallel programming problems?
ассенизатор вычерпивает яму с дерьмом, поднимает ведро наверх, а там его помошник каждый раз хоть понемногу, но прольёт на патрона. тот кряхтит:
— учись, Петька, а то всю жизнь так в помошниках и проходишь!
видимо я как раз "достаточно туп" для того, чтобы не замечать никаких проблем с организацией многозадачности в своём любимом хаскеле. так и прохожу всю жизнь
Здравствуйте, BulatZiganshin, Вы писали:
BZ>ассенизатор вычерпивает яму с дерьмом, поднимает ведро наверх, а там его помошник каждый раз хоть понемногу, но прольёт на патрона. тот кряхтит: BZ>- учись, Петька, а то всю жизнь так в помошниках и проходишь!
Мне больше нравится другая версия этого анекдота:
Из открытого канализационного люка во все стороны разливается дерьмо. Рядом с люком нерешительно мнется молодой сантехник -- не знает, что делать.
Подходит его пожилой напарник, не долго думая ныряет в люк и что-то там ремонтирует. Время от времени он выныривает и молодой подает ему ключи разных размеров.
В конце-концов авария устранена, пожилой отряхивается и с довольным видом говорит:
-- учись, Петька, а то всю жизнь ключи подавать будешь!
BZ>видимо я как раз "достаточно туп" для того, чтобы не замечать никаких проблем с организацией многозадачности в своём любимом хаскеле. так и прохожу всю жизнь
Будучи еще более тупым чем вы (неспособность изучить Haskell тому доказательство) я, тем не менее, понимаю, что вам вряд ли приходилось сталкиваться со всеми типами задач, требующих распараллеливания. Поэтому и судите вы всего лишь на основании своего ограниченного опыта. И то, что до сих пор вы не сталкивались с проблемами на Haskell-е вовсе не означает, что их вообще нет -- просто вы с ними еще не сталкивались.
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
M>>ОС — весьма узкое место. Сколько-сколько стоит 32-процессорная винда? ОС ведь такая же программа, как и другие, только побольше. Вон, Intel 16 потоков маскирует под двумя процессорами скорее всего только потому, что современные ОСи до 16 ядер не доросли ZEN>"Современные ОСи" не входят в TOP500?
Здравствуйте, iZEN, Вы писали:
iZEN>>>Учиться? iZEN>>>У меня не получается писать однопоточные приложения с 2000 года -- все мои приложения содержат больше одного потоа выполнения. iZEN>>>Что я делаю не так? R>>Это совершенно ничего не значит. Вполне возможно, что эти программы будут работать значительно медленее на многопроцессорной машине, чем на однопроцессорной. Количество потоков тут совершенно ни при чём.
ZEN>А что "причём"?
Я высказал свои мысли по этому поводу более подробно здесь
.
Ты с 2000 года с лёгкостью делаешь то, о чём я там говорю? Если да, то я удивляюсь, почему ты ещё что-то пишешь на rsdn, а не спокойно отдыхаешь на своей вилле на канарах.
Я прочитал.
Многие посылки неверные. Скорее всего они основываются на неудачной модели вытесняющей многозадачности Windows, которая не может эффективно распараллелить задачи на 4 и более процессорных ядер. К тому же, слабо учитывает разницу между NUMA- и UMA-архитектурами процессоров (AMD и Intel, соответсвенно).
То, что не умеет Windows, давно и успешно используется в операционных системах Solaris 9 и 10 на процессорах UltraSPARC.
R>Ты с 2000 года с лёгкостью делаешь то, о чём я там говорю? Если да, то я удивляюсь, почему ты ещё что-то пишешь на rsdn, а не спокойно отдыхаешь на своей вилле на канарах. R>
Может потому, что я не заморачиваюсь и не привязываюсь к Windows и пишу так, как мне удобно, я пребываю всё время в таком жалком состоянии?
.
ZEN>Я прочитал. ZEN>Многие посылки неверные. Скорее всего они основываются на неудачной модели вытесняющей многозадачности Windows, которая не может эффективно распараллелить задачи на 4 и более процессорных ядер. К тому же, слабо учитывает разницу между NUMA- и UMA-архитектурами процессоров (AMD и Intel, соответсвенно).
Как она будет это делать, если _сама_ программа не позволяет это делать?
Здравствуйте, iZEN, Вы писали:
ZEN>Я прочитал. ZEN>Многие посылки неверные. Скорее всего они основываются на неудачной модели вытесняющей многозадачности Windows, которая не может эффективно распараллелить задачи на 4 и более процессорных ядер. К тому же, слабо учитывает разницу между NUMA- и UMA-архитектурами процессоров (AMD и Intel, соответсвенно).
ZEN>То, что не умеет Windows, давно и успешно используется в операционных системах Solaris 9 и 10 на процессорах UltraSPARC.
ZEN>Может потому, что я не заморачиваюсь и не привязываюсь к Windows и пишу так, как мне удобно, я пребываю всё время в таком жалком состоянии?
Да, да, во всей кривизне всегда виновата Windows. Я тоже так считаю, потому что это профессионально.
Здравствуйте, remark, Вы писали:
R>16 аппаратных потоков — полёт нормальный. R>На днях Intel анонсировала свой новый процессор следующего поколения. Nehalem. 8 ядер. По 2 аппаратных потока на каждом ядре. 731 миллион транзисторов. Новый северный мост QuickPath (бывший CSI).
R>Выход запланирован на вторую половину следующего года. Дизайн уже готов.
R>Оригинал здесь. Правда подробностей там не много.
Nehalem Disclosures
In addition to discussing Penryn, Intel also confirmed information that was known about Nehalem, while adding some new details. Nehalem will be released in late 2008 and will use a microarchitecture that is somewhat similar to Merom/Penryn – it will be quad issue/execute/retire. Nehalem will also feature a new instruction set extension, which Intel called “ATA”, on top of SSE4. Unsurprisingly, simultaneous multithreading will make a come back, with each core supporting two logical processors. It will be interesting to see how resources are partitioned, as that was one of the critical problems in the Pentium 4, and later processors have shown much larger gains than the best case 20% that was reported for the P4. Intel describes Nehalem as dynamically managing cores, threads, cache, external interfaces and power – which certainly hints at more intelligent partitioning than the static division of resources in the P4.
There will be product baseds on Nehalem that offer from 1-8 cores, with different cache sizes, memory and interconnect bandwidth, etc. to fulfill different market requirements. The two other expected revelations were that Nehalem will use the Common System Interface to connect elements of a system, and that Nehalem will feature an integrated DDR3 memory controller. One surprise was that Intel’s integrated graphics will be integrated into the same package for some desktop and notebook products. Intel has clearly state that they prefer package integration to chip level integration for a graphics processor. However, Intel might have opted for a discrete northbridge with integrated graphics. Integrating the CPU and GPU on the same package is certainly preferable from an OEM’s point of view; it substantially reduces the chip count, which in turn reduces the complexity of the board. The only down side is that the OEM’s will have a slightly harder time differentiating their products.
Intel has also promised more information in mid-April, when the IDF in Beijing kicks off. However, this is still enough news to digest over the next few weeks.
Ну, блокирующие участки кода должны быть по-возможности короткими, понятное дело, не всё же время поток в блокировке проводит. В многоядерной системе нужен аппаратный шедуллер и аппаратные же примитивы синхронизации, как это было уже однажды сделано Cray.
Здравствуйте, iZEN, Вы писали:
ZEN>Да не в том дело. Просто не надо ограничивать себя како-то одной операционной системой.
Ага. Но надо ограничивать себя обсуждаемой темой. Эта тема была про процессор.
Лично ты никогда себе Спарк домой не поставишь. Так что кончай очередной гон.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Mamut, Вы писали:
R>>А ОС... ну а что ОС? В ней никогда не сделают ничего такого, что магически заставит существующую "одноядерную" программу магически масштабироваться.
M>Сколько-сколько стоит 32-процессорная винда?
Винда лицензируется на камни, а не на ядра. Так что если в одном или двух камнях будет 32 ядра, то стоить она будет как обычная винда.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
R>По некоторым авторитетным прогнозам это нас ждёт в очень ближайшем будущем. R>Так что лучше не улыбаться, а учиться создавать масштабируемые системы R>
Это шутка юмора. Давным давно когда вышел IBM PC с 640 килобайтами памяти Бел Гейтс имен неосторожность ляпнуть фразу "640 kilobytes should be enough for anybody!". Буквально через несколько лет над этим высказыванием смеялись все компьютерщики. Так что данная шутка высмеивает разговоры о на тему "зачем нужно много ядер".
ЗЫ
Говорил ли реально Гейтс данную фразу я не знаю.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, iZEN, Вы писали:
ZEN>>Да не в том дело. Просто не надо ограничивать себя како-то одной операционной системой. VD>Ага. Но надо ограничивать себя обсуждаемой темой. Эта тема была про процессор.
Согласен.
И как же Windows решает проблемы диспетчерезиции процессов на Nehalem? http://citcity.ru/18760/
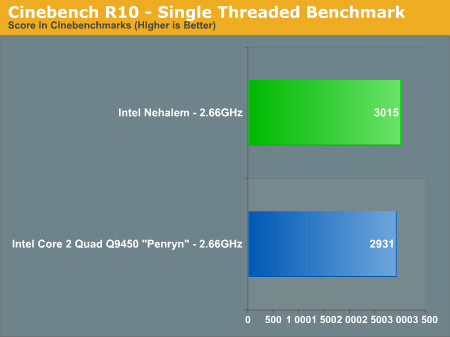
Сотрудники Anandtech в ходе тестирования использовали образец чипа Nehalem с частотой 2,66 ГГц, произведенный по 45-нанометрой технологии и снабженный 8 Мб кэш-памяти третьего уровня. Процессор был установлен в компьютер на базе операционной системы Microsoft Windows Vista Ultimate, оборудованный 2 Гб оперативной памяти.
Согласно результатам, полученным специалистами Anandtech, процессоры Nehalem, в зависимости от типа выполняемой задачи, по производительности на 20-50% опережают современные процессоры Penryn с такой же тактовой частотой. Так, например, в приложении 3dsmax 9 чип Intel Nehalem обгоняет процессор Core 2 Quad Q9450 с частотой 2,66 ГГц на 40%, а в программе Cinebench — на 20%. При этом Nehalem потребляет только на 10% больше энергии по сравнению с чипами Penryn.
Пока никак? Масштабируемость никакая: 40% — это ничто (нормально будет: 100..300% в зависимости от количества ядер).
Вот то-то же...
VD>Лично ты никогда себе Спарк домой не поставишь. Так что кончай очередной гон.
Знаю про списанные, но ещё живые СПАРКи, которые находятся у некоторых товарищей дома.
Чисто по приколу могу себе позволить Sony PlayStation3 с Yellow Dog Linux на борту и процессором Cell.
Но это ничего не значит — могу я поставить себе SPARC домой или не могу. Вопрос в другом: А надо ли?
Здравствуйте, iZEN, Вы писали:
ZEN>Пока никак? Масштабируемость никакая: 40% — это ничто (нормально будет: 100..300% в зависимости от количества ядер).
Одна незадача — тот процессор, что тестировался, имел 4 ядра.
... <<RSDN@Home 1.2.0 alpha 4 rev. 1090 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, iZEN, Вы писали:
ZEN>>Пока никак? Масштабируемость никакая: 40% — это ничто (нормально будет: 100..300% в зависимости от количества ядер).
AVK>Одна незадача — тот процессор, что тестировался, имел 4 ядра.
Видимо, это младшая модель. Они добавили L3 кэш и HT (гипер-тридинг), но ядер по прежнему 4...
Не понятно, за счёт чего прирост производительности — из-за L3 кэша, или HT, или ещё чего-то. Но если за счёт HT, то 40% — это очень и очень хорошо. Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
Здравствуйте, remark, Вы писали:
R>Не понятно, за счёт чего прирост производительности — из-за L3 кэша, или HT, или ещё чего-то.
Снижена на 30% латентность доступа к L2 и памяти, добавлена специальная логика, позволяющая значительно снизить проблемы из-за невыровненных по линиям кеша данных (на тестах, это меряющих, производительность растет на 150 и более процентов на одной частоте по сравнению с Penryn). Наконец там не два чипа с медленной шиной между ними, как в yorkfield, а все на одном чипе.
R> Но если за счёт HT, то 40% — это очень и очень хорошо.
Вряд ли.
R> Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
HT есть у Atom, и там, судя по тестам, эффект от него весьма приличный.
... <<RSDN@Home 1.2.0 alpha 4 rev. 1090 on Windows Vista 6.0.6001.65536>>
Здравствуйте, iZEN, Вы писали:
R>>16 аппаратных потоков — полёт нормальный.
Улыбнуло
ZEN>Ну и что? ZEN>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже.
А когда Нехалем выйдет — Сан сделает уже третью Ниагару.
Здравствуйте, Gaperton, Вы писали:
G>Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже.
Ниагара весьма неспешная в однопоточной работе. Оно идеально подходит для серверов приложений с кучей потоков, но однопоточная производительность — ниже плинтуса.
И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться.
Здравствуйте, Cyberax, Вы писали:
G>>Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже. C>Ниагара весьма неспешная в однопоточной работе. Оно идеально подходит для серверов приложений с кучей потоков, но однопоточная производительность — ниже плинтуса.
C>И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться.
Никакой идиот не будет тебе совмещать аппаратную многопоточность и суперскаляр (только Intel один раз попробовал в P4 — с тех пор так не делает). Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой.
Здравствуйте, Gaperton, Вы писали:
C>>И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться. G>Никакой идиот не будет тебе совмещать аппаратную многопоточность и суперскаляр (только Intel один раз попробовал в P4 — с тех пор так не делает).
Уже делает — в Nehalem'е. Идея, на самом деле, здравая. Вместо того, чтобы бесцельно тратить время во время cache miss — процессор будет переключаться на другой поток.
G>Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой.
Разве? Из статьи в Вики видно, что оно будет продолжением Core2.
Здравствуйте, Cyberax, Вы писали:
G>>Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой. C>Разве? Из статьи в Вики видно, что оно будет продолжением Core2.
Из статьи в вики на самом деле непонятно, сколько инструкций может выдавать одно ядро. На картинках реально присутствует Reorder Buffer, что может говорить о суперскалярном выполнении. И он довольно глубокий. На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано.
Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит.
Здравствуйте, Gaperton, Вы писали:
G>Из статьи в вики на самом деле непонятно, сколько инструкций может выдавать одно ядро. На картинках реально присутствует Reorder Buffer, что может говорить о суперскалярном выполнении. И он довольно глубокий.
Ещё и Memory Order Buffer.
G>На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано.
Два аппаратных потока не должны конкурировать — переключение между ними будет происходит, когда процессору нужно ждать из-за промаха по кэшу или какого-то pipeline stall. Это принципиальное различие между Ниагарой и Нехалемом.
G>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит.
Обещают, что будет не хуже Core2.
Здравствуйте, Cyberax, Вы писали:
G>>На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано. C>Два аппаратных потока не должны конкурировать — переключение между ними будет происходит, когда процессору нужно ждать из-за промаха по кэшу или какого-то pipeline stall. Это принципиальное различие между Ниагарой и Нехалемом.
Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине. Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку.
Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам.
G>>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит. C>Обещают, что будет не хуже Core2.
Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже.
Здравствуйте, Gaperton, Вы писали:
G>Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине.
В Ниагаре "револьверная" система, когда каждый поток получает один слот в "револьвере". Ну и, естественно, на заткнувшийся по cache miss поток оно просто переключать не будет.
G>Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку.
Во время первого HyperThreading'а оно работало именно как я сказал. Что вполне логично, переключения потока всегда происходит по событиям, при которых всё равно нужно pipeline перестраивать — так что всю систему с декодерами операций можно разделять между потоками, она не будет использоваться конкуррентно. Достаточно только сохранять регистры, по сути. На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
G>Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам. http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так.
C>>Обещают, что будет не хуже Core2. G>Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже.
Обещают лучше
Здравствуйте, Cyberax, Вы писали:
G>>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит. C>Обещают, что будет не хуже Core2.
Посмотрел подробно. 3 канала там всего — два сумматора да один умножитель. Слабее там одно ядро, чем Core 2 — три операции в пике. Пика, впрочем, они должны достигать часто, потому что замешивают в reorder buffer два независимых по регистрам потока. Если, конечно, умножений попадется достаточно. Если, конечно, не будет промахов в кэш .
Короче, не было бы ничего особенного, но каждый из трех каналов — SSE шириной 128 бит. На векторных SSE операциях эта машинка будет реально рвать. Ацкая числодробилка, вот что это такое.
Здравствуйте, Cyberax, Вы писали:
C>На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
Хотел написать "Register Allocation Table", которых тоже два
Здравствуйте, Gaperton, Вы писали:
G>Посмотрел подробно. 3 канала там всего — два сумматора да один умножитель. Слабее там одно ядро, чем Core 2 — три операции в пике. Пика, впрочем, они должны достигать часто, потому что замешивают в reorder buffer два независимых по регистрам потока. Если, конечно, умножений попадется достаточно. Если, конечно, не будет промахов в кэш .
Мне всё же кажется, что не замешивают. А на один поток 3 ALU — самое то, как раз.
G>Короче, не было бы ничего особенного, но каждый из трех каналов — SSE шириной 128 бит. На векторных SSE операциях эта машинка будет реально рвать. Ацкая числодробилка, вот что это такое.
SSE — фигня Скоро будет http://en.wikipedia.org/wiki/Advanced_Vector_Extensions с 256-битным каналом (в будущем до 512 бит).
Здравствуйте, Cyberax, Вы писали:
C>Здравствуйте, Gaperton, Вы писали:
G>>Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине. C>В Ниагаре "револьверная" система, когда каждый поток получает один слот в "револьвере". Ну и, естественно, на заткнувшийся по cache miss поток оно просто переключать не будет.
По факту это работает именно так — заполняется дырка в конвейре при промахе в кэш или любой другой причине.
G>>Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку. C>Во время первого HyperThreading'а оно работало именно как я сказал.
гипертрединг — это маркетинговый термин Интела. Аппаратный мультитрединг может быть устроен совершенно по разному, в том числе и у них. Первый гипертрединг у них вообще был ошибкой природы.
C>Что вполне логично, переключения потока всегда происходит по событиям, при которых всё равно нужно pipeline перестраивать — так что всю систему с декодерами операций можно разделять между потоками, она не будет использоваться конкуррентно.
Не всегда. Надо различать промах в кэш команд и в кэш данных. Первое происходит редко, потому что branch prediction в современных процах ацкий, работает с вероятностями более 96-98% и умеет даже косвенные переходы предсказывать. Второе — чаще, но оно лечится суперскаляром и предвыборкой. Как ты думаешь, зачем там reorder buffer глубиной в 128 команд? Грубо — в том числе чтобы выполнять эти команды на фоне ожидания загрузки в регистр при промахе в кэш. Во втором случае у тебя исполнительный конвейер будет с высокой вероятностью разогрет даже при промахе в кэш. Именно поэтому первый гипертрединг и был таким отстоем — толку с него при наличии мощного суперскаляра — почти ноль.
C> Достаточно только сохранять регистры, по сути.
В суперскаляре — не достаточно. У тебя глубоко конвейеризованная арифметика и байпасы. Плюс — состояние станций резервирования, на которых операции ждут операндов. Плюс — состояние исполнительного конвейра. Короче, состояние распылено по самым разным блокам, и его сохранение — реальный challenge, это просто нельзя сделать мгновенно. В Ниагаре таких проблем нет — она single issue, все тупо. И правильно. Так и надо.
C> На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
Непонятно.
G>>Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам. C>http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так.
Напрасно на это смотришь. У них это в разных процах сделано по разному стопудов.
C>>>Обещают, что будет не хуже Core2. G>>Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже. C>Обещают лучше
Увидим.
Здравствуйте, AndrewVK, Вы писали:
G>>Слабее там одно ядро, чем Core 2
Чудес не бывает. Nehalem выдает всего три арифметических инструкции за такт в пике, но зато каждая из них — SSE, в отличии от Core 2. А этот тест скорее всего с SSE инструкциями. Больно название у него подозрительное.
AVK>
Здравствуйте, AndrewVK, Вы писали:
R>> Но если за счёт HT, то 40% — это очень и очень хорошо.
AVK>Вряд ли.
R>> Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
AVK>HT есть у Atom, и там, судя по тестам, эффект от него весьма приличный.
А сколько тогда процентов будет очень и очень хорошо (для процессора типа Интела — всеядного зверя, которому приходится рассчитывать на все типы нагрузок, в т.ч. и на однопоточные приложения)? 100?
Моё понимание такое, что HT — это не основной конёк Интел, это просто способ выжать дополнительные Х% производительности за дополнительные 10% пространства. Они и делают всего 2 аппаратных потока на ядро, а не 8 как Sun.
В таком контексте, мне кажется, дополнительные 30-40% это вполне хорошо. Это как 8 лет назад 1.4ГГц, а не 1.0ГГц.
Здравствуйте, Gaperton, Вы писали:
C>>Во время первого HyperThreading'а оно работало именно как я сказал. G>гипертрединг — это маркетинговый термин Интела. Аппаратный мультитрединг может быть устроен совершенно по разному, в том числе и у них. Первый гипертрединг у них вообще был ошибкой природы.
Первый гипертрединг был вполне неплохой вещью, а вот P4 в целом — ошибкой природы.
То что аппаратный мультитрединг по-разному можно сделать — так я про это и говорю.
G>Не всегда. Надо различать промах в кэш команд и в кэш данных. Первое происходит редко, потому что branch prediction в современных процах ацкий, работает с вероятностями более 96-98% и умеет даже косвенные переходы предсказывать. Второе — чаще, но оно лечится суперскаляром и предвыборкой.
Однако, по меркам общей системы оно происходит очень часто. И это как раз прекрасный повод перключиться на другой поток.
G>Как ты думаешь, зачем там reorder buffer глубиной в 128 команд? Грубо — в том числе чтобы выполнять эти команды на фоне ожидания загрузки в регистр при промахе в кэш. Во втором случае у тебя исполнительный конвейер будет с высокой вероятностью разогрет даже при промахе в кэш.
Это понятно. Но что делать с зависимыми данными? А их ведь в реальности очень много.
G>Именно поэтому первый гипертрединг и был таким отстоем — толку с него при наличии мощного суперскаляра — почти ноль.
На P4 слишком глубокий pipeline был, он всё портил.
C>> Достаточно только сохранять регистры, по сути. G>В суперскаляре — не достаточно. У тебя глубоко конвейеризованная арифметика и байпасы. Плюс — состояние станций резервирования, на которых операции ждут операндов. Плюс — состояние исполнительного конвейра. Короче, состояние распылено по самым разным блокам, и его сохранение — реальный challenge, это просто нельзя сделать мгновенно.
Я предполагаю, что как раз переключение потоков как раз происходит при событиях, когда вся конвееризированая система летит к чёрту. Т.е. когда нечего терять от повторного построения конвейера команд для другого потока, так как это и так придётся сделать.
C>>http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так. G>Напрасно на это смотришь. У них это в разных процах сделано по разному стопудов.
Почему?
Здравствуйте, Cyberax, Вы писали:
G>>Посмотрел подробно. 3 канала там всего — два сумматора да один умножитель. Слабее там одно ядро, чем Core 2 — три операции в пике. Пика, впрочем, они должны достигать часто, потому что замешивают в reorder buffer два независимых по регистрам потока. Если, конечно, умножений попадется достаточно. Если, конечно, не будет промахов в кэш . C>Мне всё же кажется, что не замешивают. А на один поток 3 ALU — самое то, как раз.
Узнаем, когда они детальные спеки опубликуют. Сейчас тупо информации не хватает, только гадать остается. Там, я чувствую, что-то нетривиальное у них. Кстати, я бы заключил пари на 1000 руб, что у них там замес двух потоков в общий reorder buffer, а не переключение потоков. Ты готов?
Здравствуйте, Gaperton, Вы писали:
C>>Мне всё же кажется, что не замешивают. А на один поток 3 ALU — самое то, как раз.
G>Узнаем, когда они детальные спеки опубликуют. Сейчас тупо информации не хватает, только гадать остается. Там, я чувствую, что-то нетривиальное у них. Кстати, я бы заключил пари на 1000 руб, что у них там замес двух потоков в общий reorder buffer, а не переключение потоков. Ты готов?
Секундантом предлагаю thesz — он, во-первых, человек строгих моральных правил, и подойдет к вопросу беспристрастно, во-вторых — круто шарит в теме (в архитектурах процов — он писал нашу модель 4-way суперскалярного MIPS, и вообще много как отличился), и установит победителя. В третьих — он просто очень крупный специалист — весит он больше 100 кг и жим штанги у него 120 .
Здравствуйте, Gaperton, Вы писали:
G>Узнаем, когда они детальные спеки опубликуют. Сейчас тупо информации не хватает, только гадать остается. Там, я чувствую, что-то нетривиальное у них. Кстати, я бы заключил пари на 1000 руб, что у них там замес двух потоков в общий reorder buffer, а не переключение потоков. Ты готов?
Да без проблем, давай.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Gaperton, Вы писали:
G>>Чудес не бывает. Nehalem выдает всего три арифметических инструкции за такт в пике
AVK>Я бы не был так уверен. Никакой достоверной информации о том, что реально будет продаваться, пока нет.
Если не изменяет память, то в Pentium4 целочисленное АЛУ для простых операций работало на удвоенной частоте. Соотв. Кол-во целочисленных операций за такт было не равно кол-ву целочисленных АЛУ.
G>Секундантом предлагаю thesz — он, во-первых, человек строгих моральных правил, и подойдет к вопросу беспристрастно, во-вторых — круто шарит в теме (в архитектурах процов — он писал нашу модель 4-way суперскалярного MIPS...
4-way в смысле 4-ёх процессорный SMP?
Это оно: http://mskhug.ru/wiki/MskHUG1_1
?
Было бы интересно посмотреть на моделирование SMP, но там вроде нет упоминаний...
Здравствуйте, remark, Вы писали:
R>Если не изменяет память, то в Pentium4 целочисленное АЛУ для простых операций работало на удвоенной частоте. Соотв. Кол-во целочисленных операций за такт было не равно кол-ву целочисленных АЛУ.
Ну это дичь.
Операция на одном устройстве может занимать разное количество тактов — это запросто. Я конечно не специалист по арифметике, но уверен, целочисленное АЛУ не может работать на удвоенной частоте для простых операций. Современные процессоры имеют т.н. синхронный дизайн — на выходе блока стоят "защелки" из триггеров, которые срабатывают по сигналам clock tree, и времена работы блоков рассчитаны статически. Удваивать частоту в зависимости от операции геморройно и лишено смысла — все равно остальная часть системы не сможет воспользоваться этим результатом раньше, чем начнется ее такт. Впрочем, приведи ссылку, посмотрим.
R>А кстати, на текущих Core сколько АЛУ?
Посмотрел. Арифметики у него столько же и такой же, сколько и у Нехалема. То есть три "полезных" юнита SSE-128 бит. Но выполнять они могут за такт больше — до 5-6 операций x86. Они клеят пары операций вместе — macro-fusion, не пропадать же 128-битным АЛУ без SSE-команд. При этом, конвейр там способен выдавать 4 инструкции за такт. Короче, все ни разу не просто, но главное — на самом деле они с Нехалем во многом одинаковы, по крайней мере в части арифметики. Что подтверждается и тестами. Это не укоцанные ядра. Удивительное рядом, блин.
Здравствуйте, Cyberax, Вы писали:
G>>Узнаем, когда они детальные спеки опубликуют. Сейчас тупо информации не хватает, только гадать остается. Там, я чувствую, что-то нетривиальное у них. Кстати, я бы заключил пари на 1000 руб, что у них там замес двух потоков в общий reorder buffer, а не переключение потоков. Ты готов? C>Да без проблем, давай.
Здравствуйте, AndrewVK, Вы писали:
G>>Чудес не бывает. Nehalem выдает всего три арифметических инструкции за такт в пике
AVK>Я бы не был так уверен. Никакой достоверной информации о том, что реально будет продаваться, пока нет.
Ну да, чудеса бывают . Я посмотрел, как устроен Core. Они в части арифметики оказывается очень похожи с Nehalem, и умеют клеить операции в пары. Что подтверждает твой тест. Так что на самом деле там до 6 обычных инструкций за такт, и до 3-х SSE инструкций.
Здравствуйте, iZEN, Вы писали:
VD>>Ага. Но надо ограничивать себя обсуждаемой темой. Эта тема была про процессор.
ZEN>Согласен.
Ну, и замечательно. Продолжай обсуждать процессор, а не ОС.
ZEN>И как же Windows решает проблемы диспетчерезиции процессов на Nehalem?
Открою тебе один небольшой сикрет. ОС фактически плевать на то сколько процессоров в системе. Две абсолютно независимых задачи будут работать так как будто они живут на двух разны машинах, а 8 как на восьми (если есть 8 ядер). Но все это будет только при одном условии. У этих задач не должно быть точек соприкоснования в которых они обращаются к одним и тем же ресурсам. А вот это как раз очень сложно. В системе общая память, общий винт, общие шины. Вот это и тормозит работу. А Виндовс тут мало чем отличается от любой другой многозадачной ОС.
В большинстве случаев производительность зависит не от ОС, а от программ.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Gaperton, Вы писали:
G>Здравствуйте, remark, Вы писали:
R>>Если не изменяет память, то в Pentium4 целочисленное АЛУ для простых операций работало на удвоенной частоте. Соотв. Кол-во целочисленных операций за такт было не равно кол-ву целочисленных АЛУ.
G>Ну это дичь.
G>Операция на одном устройстве может занимать разное количество тактов — это запросто. Я конечно не специалист по арифметике, но уверен, целочисленное АЛУ не может работать на удвоенной частоте для простых операций. Современные процессоры имеют т.н. синхронный дизайн — на выходе блока стоят "защелки" из триггеров, которые срабатывают по сигналам clock tree, и времена работы блоков рассчитаны статически. Удваивать частоту в зависимости от операции геморройно и лишено смысла — все равно остальная часть системы не сможет воспользоваться этим результатом раньше, чем начнется ее такт. Впрочем, приведи ссылку, посмотрим.
Сейчас попробовать погуглить...
Насколько помню там было не удвоение частоты блока, а просто отдельное алу, которое способно выполнять подмножество команд, *всегда* работает на удвоенной частоте.
R>>А кстати, на текущих Core сколько АЛУ?
G>Посмотрел. Арифметики у него столько же и такой же, сколько и у Нехалема. То есть три "полезных" юнита SSE-128 бит. Но выполнять они могут за такт больше — до 5-6 операций x86. Они клеят пары операций вместе — macro-fusion, не пропадать же 128-битным АЛУ без SSE-команд. При этом, конвейр там способен выдавать 4 инструкции за такт. Короче, все ни разу не просто, но главное — на самом деле они с Нехалем во многом одинаковы, по крайней мере в части арифметики. Что подтверждается и тестами. Это не укоцанные ядра. Удивительное рядом, блин.
Насколько помню доки, micro-fusion и macro-fusion работают только для достаточно ограниченных случаев, поэтому считать их в общем случае не очень честно. Да и в Нахелеме они остались.
Здравствуйте, remark, Вы писали:
R>Здравствуйте, Gaperton, Вы писали:
G>>Секундантом предлагаю thesz — он, во-первых, человек строгих моральных правил, и подойдет к вопросу беспристрастно, во-вторых — круто шарит в теме (в архитектурах процов — он писал нашу модель 4-way суперскалярного MIPS...
R>4-way в смысле 4-ёх процессорный SMP?
Нет, речь об однопоточном процес, который умеет выполнять до 4-х инструкций за такт.
R>Это оно: R>http://mskhug.ru/wiki/MskHUG1_1
VD>Открою тебе один небольшой сикрет. ОС фактически плевать на то сколько процессоров в системе. Две абсолютно независимых задачи будут работать так как будто они живут на двух разны машинах...
Я думаю, что две абсолютно независимых будут очень сильно конкурировать внутри ядра ОС, если будут, например, создавать объекты ядра. Объекты исключительно "программные", ну например семафоры.
Здравствуйте, Gaperton, Вы писали:
G>Ну это дичь.
G>Операция на одном устройстве может занимать разное количество тактов — это запросто. Я конечно не специалист по арифметике, но уверен, целочисленное АЛУ не может работать на удвоенной частоте для простых операций. Современные процессоры имеют т.н. синхронный дизайн — на выходе блока стоят "защелки" из триггеров, которые срабатывают по сигналам clock tree, и времена работы блоков рассчитаны статически. Удваивать частоту в зависимости от операции геморройно и лишено смысла — все равно остальная часть системы не сможет воспользоваться этим результатом раньше, чем начнется ее такт. Впрочем, приведи ссылку, посмотрим.
ABSTRACT
To meet the demands of low-latency integer operations,
the Intel Pentium® 4 processor architecture implements
fast integer operations using a 2x frequency core clock.
The frequency advances enabled by Intel’s new 90nm
technology when paired with a 2x frequency multiplier
require novel circuit topologies if latency is to be
optimized. The discussed solution uses unprecedented
levels of small signal random logic to implement a double
frequency X86 integer core. This circuit technology,
termed “Low-Voltage Swing” (LVS) enables the Pentium
4 processor [1] to take full advantage of Intel’s new 90nm
technology [2].
Здравствуйте, VladD2, Вы писали:
VD>Открою тебе один небольшой сикрет. ОС фактически плевать на то сколько процессоров в системе. Две абсолютно независимых задачи будут работать так как будто они живут на двух разны машинах, а 8 как на восьми (если есть 8 ядер). Но все это будет только при одном условии. У этих задач не должно быть точек соприкоснования в которых они обращаются к одним и тем же ресурсам. А вот это как раз очень сложно. В системе общая память, общий винт, общие шины. Вот это и тормозит работу. А Виндовс тут мало чем отличается от любой другой многозадачной ОС.
Вообще говоря, от ОС как раз очень многое зависит при большом количестве процессоров. Так как проявляются очень многие bottleneck'и, незаметные на малом числе CPU.
Например, безобидная блокировка в ядерном менеджере памяти на 64 процессорах вызвать жуткие тормоза. Или глюки в планировщике могут вызывать большую латентность и т.п.
Здравствуйте, remark, Вы писали:
R>Здравствуйте, Gaperton, Вы писали:
G>>Ну это дичь.
G>>Операция на одном устройстве может занимать разное количество тактов — это запросто. Я конечно не специалист по арифметике, но уверен, целочисленное АЛУ не может работать на удвоенной частоте для простых операций. Современные процессоры имеют т.н. синхронный дизайн — на выходе блока стоят "защелки" из триггеров, которые срабатывают по сигналам clock tree, и времена работы блоков рассчитаны статически. Удваивать частоту в зависимости от операции геморройно и лишено смысла — все равно остальная часть системы не сможет воспользоваться этим результатом раньше, чем начнется ее такт. Впрочем, приведи ссылку, посмотрим.
Дык это не дичь. Эта статья о жостких аналоговых оптимизациях LVS, применяемых в Интеле, с целью сократить латентность выполнения целочесленных операций. То, что там _внутри_ блоков частота удваивается — это частность и особенности технологии LVS, темп выдачи информации _наружу_ из АЛУ все равно соответствует общесистемной частоте. Что они эти достигают — они сокращают _латентность_ арифметических операций. Но не _темп_ выдачи результатов. Поэтому на _пиковую_ производительность это никак не влияет. Об этом, кстати, в самом начале и говорится.
Здравствуйте, Gaperton, Вы писали:
G>Дык это не дичь. Эта статья о жостких аналоговых оптимизациях LVS, применяемых в Интеле, с целью сократить латентность выполнения целочесленных операций. То, что там _внутри_ блоков частота удваивается — это частность и особенности технологии LVS, темп выдачи информации _наружу_ из АЛУ все равно соответствует общесистемной частоте. Что они эти достигают — они сокращают _латентность_ арифметических операций. Но не _темп_ выдачи результатов. Поэтому на _пиковую_ производительность это никак не влияет. Об этом, кстати, в самом начале и говорится.
Значит я не так понял...
А какая тогда конечная цель этого удвоения частоты?
Здравствуйте, remark, Вы писали:
R>Значит я не так понял... R>А какая тогда конечная цель этого удвоения частоты?
Конвейер короче становится на арифметике. Работает быстрее — требуется меньше стадий.
Здравствуйте, Cyberax, Вы писали:
C>Здравствуйте, Gaperton, Вы писали:
G>>Узнаем, когда они детальные спеки опубликуют. Сейчас тупо информации не хватает, только гадать остается. Там, я чувствую, что-то нетривиальное у них. Кстати, я бы заключил пари на 1000 руб, что у них там замес двух потоков в общий reorder buffer, а не переключение потоков. Ты готов?
C>Да без проблем, давай.
Я спорить не буду, но мне тоже кажется, что будет замес двух потоков в одном конвеере.
Во-первых, если промах мимо L2$ или L3$ не вызывает проблем, то промах мимо L1$ с одной стороны слишком короткий, что бы затевать что-то грандиозное, а с другой всё-таки не хочется терять его время.
Во-вторых, промах мимо любого кэша не вызывает сброс конвеера, что бы можно было делать заполнение конвеера другим потоком. Команды зависимые от загружаемых данных надо просто приостановить.
В-третьих, если конвеер мы всё равно сбрасываем из-за неправильно предсказанного перехода, то в принципе всё равно каким потоком заполнять конвеер по-новой — новым потоком или текущим. Я не вижу тут ничего, откуда может взяться какой-то выигрыш.
В-четвёртых, при замесе двух потоков эффективная длина конвеера получается меньше, т.к. сбрасывать из него надо только часть команд, которые относятся к потоку, который вызвал сброс. Что в общем-то хорошо.
Здравствуйте, remark, Вы писали:
R>В-четвёртых, при замесе двух потоков эффективная длина конвеера получается меньше, т.к. сбрасывать из него надо только часть команд, которые относятся к потоку, который вызвал сброс. Что в общем-то хорошо.
С другой стороны, из-за этих всех эффектов мы потеряем в однопоточной производительности.
Здравствуйте, Cyberax, Вы писали:
R>>В-четвёртых, при замесе двух потоков эффективная длина конвеера получается меньше, т.к. сбрасывать из него надо только часть команд, которые относятся к потоку, который вызвал сброс. Что в общем-то хорошо. C>С другой стороны, из-за этих всех эффектов мы потеряем в однопоточной производительности.
C>Поэтому я и сомневаюсь, что оно так работает.
Ну, с другой стороны — ты представляешь, насколько дорого поток переключить при таком глубоком конвейре? Это примерно то же самое, что обеспечить точную обработку исключения. Вторая проблема — тебе надо понять, когда его переключать, а это не так просто. Единичный паромах в кэш данных не может являться поводом для переключения — с ним легко справится суперскаляр. Более того — конвейер глубокий, и в случае промаха в кэш данных ты слишком поздно поймешь, что пора переключать поток, и у тебя будет "пузырь". Вариант без "пузыря" — это уметь подавать в конвейер команды с другого потока, пока в конвейере все еще есть команды первого потока — не сбрасывая конвейер. Делается это просто — достаточно сделать разные физические адреса регистров двух потоков в общем регистровом файле.
Здравствуйте, Gaperton, Вы писали:
G>Ну, с другой стороны — ты представляешь, насколько дорого поток переключить при таком глубоком конвейре?
А он не глубокий. Точной информации нет, но он в 14 команд всего в Core2 и вряд ли сильно изменится в Nehalem. Это не P4 с его конвейером в 30 команд.
G>Это примерно то же самое, что обеспечить точную обработку исключения. Вторая проблема — тебе надо понять, когда его переключать, а это не так просто. Единичный паромах в кэш данных не может являться поводом для переключения — с ним легко справится суперскаляр.
При branch misprediction — не справится. При обычном промахе — тоже, скорее всего, из-за зависимостей по данным.
А ещё есть lookup'ы в таблице страниц при промахах в TLB и прочие совсем уж жуткие вещи.
G>Более того — конвейер глубокий, и в случае промаха в кэш данных ты слишком поздно поймешь, что пора переключать поток, и у тебя будет "пузырь". Вариант без "пузыря" — это уметь подавать в конвейер команды с другого потока, пока в конвейере все еще есть команды первого потока — не сбрасывая конвейер. Делается это просто — достаточно сделать разные физические адреса регистров двух потоков в общем регистровом файле.
Это уже как-то более похоже на правду звучит — выполнение команд другого потока не всё время, а только в случае образования "пузырей". Это будет однозначно эффективнее моего изначального предположения. Но потребует больше ресурсов, так как нужно параллельно уметь выбирать и декодировать команды двух потоков.
Здравствуйте, Cyberax, Вы писали:
G>>Более того — конвейер глубокий, и в случае промаха в кэш данных ты слишком поздно поймешь, что пора переключать поток, и у тебя будет "пузырь". Вариант без "пузыря" — это уметь подавать в конвейер команды с другого потока, пока в конвейере все еще есть команды первого потока — не сбрасывая конвейер. Делается это просто — достаточно сделать разные физические адреса регистров двух потоков в общем регистровом файле. C>Это уже как-то более похоже на правду звучит — выполнение команд другого потока не всё время, а только в случае образования "пузырей". Это будет однозначно эффективнее моего изначального предположения. Но потребует больше ресурсов, так как нужно параллельно уметь выбирать и декодировать команды двух потоков.
Смори, как там _может_ быть. АЛУ все SSE-шные, шириной 128 бит, так? При этом, fuse может быть устроен так, что пытается клеить обычные 64-х битные команды в пары — чтобы как следует нагрузить это АЛУ — а то его половина будет простаивать. При этом, одного потока, чтобы сделать такой Fuse, будет маловато — и в Core 2 так не делаетася. А вот если у нас будут готовые к выполнению инструкции с двух потоков, независимых по регистрам?
При этом, читать команды одновременно с двух потоков не надо — достаточно применить при выборке команд револьверную систему.
Здравствуйте, Cyberax, Вы писали:
C>Здравствуйте, remark, Вы писали:
R>>В-четвёртых, при замесе двух потоков эффективная длина конвеера получается меньше, т.к. сбрасывать из него надо только часть команд, которые относятся к потоку, который вызвал сброс. Что в общем-то хорошо.
C>С другой стороны, из-за этих всех эффектов мы потеряем в однопоточной производительности.
А почему?
Моё наивное видение такое, что если второго потока нет, то всё будет отдано под первый, и он будет выполняться так как будто HT нет.
Здравствуйте, remark, Вы писали:
R>>>В-четвёртых, при замесе двух потоков эффективная длина конвеера получается меньше, т.к. сбрасывать из него надо только часть команд, которые относятся к потоку, который вызвал сброс. Что в общем-то хорошо.
C>>С другой стороны, из-за этих всех эффектов мы потеряем в однопоточной производительности.
R>А почему? R>Моё наивное видение такое, что если второго потока нет, то всё будет отдано под первый, и он будет выполняться так как будто HT нет.
Скажу больше. А если он, второй поток — есть, то его выполнение один хрен замедлит выполнение первого потока, как их не переключай, хоть раз в 15 мсек. А вот при замесе — одновременное выполнение будет эффективнее.
R>Не понятно, за счёт чего прирост производительности — из-за L3 кэша, или HT, или ещё чего-то. Но если за счёт HT, то 40% — это очень и очень хорошо. Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
у меня HT на P4 давал прирост близкий к 100% (криптография).