Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, borisman3, Вы писали:
B>>Из реальной всамделишной практики: Серсвисно-Ориентированные Архитектуры (SOA) имеют громадное преимущество над просто ООП за счет: B>>1) Активной реакции сервиса на подключение B>>2) Сокрытия реализации сервиса за интерфейсом
AVK>Круто. Вот только п.1 ООП перпендикулярен, а п.2 — один из базовых принципов ООП.
Да, к сожалению тут мы говорим об одной штуке(SOA) реализованной поверх другой штуки (ООП) и потому трудно понять что-ж это я имел в виду. Поясню.
1) ооп
IMyService s = new MyService();
2) SOA
IMyService s = serviceDiscovery.requireService(IMyService.class);
Первый вариант намертво закрепляет реализацию в компайл-тайме, второй — позволяет ее менять в рантайме. Ну и дальше понятно. Конечно Вы можете сказать что мол вариант 1) это не ООП, что в хорошей ООП программе надо делать по другому и т.д. и т.п. Заранее соглашаюсь, все так. И один из способов в ООП программе сделать все как надо — это SOA.
Re[4]: Заметка: Компонентная философия и реализация
Здравствуйте, borisman3, Вы писали:
B>Да, к сожалению тут мы говорим об одной штуке(SOA) реализованной поверх другой штуки (ООП) и потому трудно понять что-ж это я имел в виду. Поясню.
B>1) ооп B>IMyService s = new MyService();
B>2) SOA B>IMyService s = serviceDiscovery.requireService(IMyService.class);
Ужась. Пункт 2 в ООП называется абстрактная фабрика, а точнее паттерн service locator. И, кстати, к SOA вообще никакого отношения не имеет.анет.
B>Первый вариант намертво закрепляет реализацию в компайл-тайме, второй — позволяет ее менять в рантайме.
Ага. Один из основных принципов ООП.
B>что в хорошей ООП программе надо делать по другому и т.д. и т.п. Заранее соглашаюсь, все так. И один из способов в ООП программе сделать все как надо — это SOA.
SOA совсем о другом. Основное отличие SOA от внутрипрограммного ООП состоит в отсутствии навигационного доступа. Т.е. в SOA нельзя из метода возвращать полноценные объекты, у которых удаленно можно позвать свои методы. Эта специфика связана с тем, что такое плохо работает в распределенных системах. А способ создания экземпляра класса по контракту никакого отношения к SOA не имеет.
... << RSDN@Home 1.2.0 alpha 5 rev. 66 on Windows 8 6.2.9200.0>>
Здравствуйте, AlexRK, Вы писали:
V>>Да всё-равно не выйдет. Программа целиком и есть семантика. ARK>Почему же, в ограниченном диапазоне — вполне выйдет. Design by contract, особенно статический — это же мега-круто.
Почти весь этот design by contract можно вложить в систему типов хотя бы С++ еще аж прошлого стандарта безо-всякого abstraction penalty. То бишь, это всё костыли для недостаточно выразительных систем типов в координатах лямбда-куба. В системах можно выразить вообще весь design by contract. С++ относится к системе типов Лw.
В любом случае, я бы не стал ограничения на входные и выходные данные приравнивать к семантике.
ARK>Ну а семантику прям всей программы рассматривать, ИМХО, не стоит.
Ну ОК, тогда не стоит пользоваться термином "семантика" для описания того, что же нам гарантируют типизированные интерфейсы. Собсно, об этом я и говорил.
V>>Я еще не смотрел, но почему-то уверен, что когда посмотрю, то за пару минут придумаю, как без проблем удовлетворить любой контракт, но при этом нарушить исходную семантику. )) ARK>Не сомневаюсь. Но в любом случае, чем больше проверок — тем лучше.
Ага, т.е. чем "жирнее" интерфейс, тем меньше вероятность его "случайной" реализации, не?
Я примерно так себе и представляю причину, почему идея разбить кортеж ф-ий контракта на относительно независимые сигналы встречает инстинктивное сопротивление (не ты первый). Ведь кортеж — уже некое ограничение само по себе.
V>>Это зависит от модели расрпостранения сигналов. Если синхронная модель — то последовательность вызовов имеет смысл. Если асинхронная, то тоже имеет, но уже по-другому (реакция лишь на изменения значения, а не на факт поступления 2-в-1-м — сигнала+события). ARK>Так. Как я понимаю, это в программе будет выглядеть примерно таким образом — в теле какой-то функции мы должны дергать выходы компонента в определенном порядке (так же, как в императивном программировании — сперва открываем файл, потом читаем из него). Контракты совсем бы не помешали, чтобы проконтролировать это (сперва читай этот выход, потом этот).
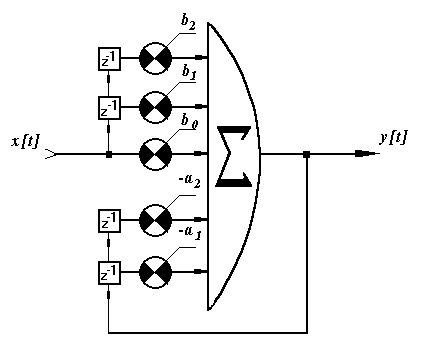
Боюсь, лучшим выходом здесь будут не контракты, предписывающие что в каком порядке дергать, а декларативность. Угу, в сочетании с изменяемым состоянием. Необходимо описать реакцию на входное воздействие. Т.к. низлежащий вычислитель будет гарантировать отсутствие гонок, то эта реакция вполне может пользоваться персистентными данными (сохраняемыми от вызова к вызову). Поэтому становится возможным реализовать, например, рекурсивный цифровой фильтр:
И вообще любой классический автомат, который имеет конечное время реакции на воздействие.
V>>Я, вообще-то за то, чтобы компоненты могли (при надобности) иметь состояние. ARK>Тогда внутри компонента с состоянием будет куча локов-синхронизаций?
Не внутри, а снаружи. Синхронизация в пользовательском коде — самый быстрый путь к дедлокам. ))
Я уже не говорю о провальной получаемой эффективности, если решать вопросы синхронизации "по-месту" и таких мест набирается немеряно.
ARK>Т.е. вы определяете в своей модели набор примитивных типов (ну и один структурный примитив "кортеж").
Типы — ес-но. Просто хотел бы иметь некую иерархию типов: данные отдельно, "вычислители" — отдельно. И разные правила для разных сортов типов.
V>>"Пробрасывается" не значение, а сам пин в момент соединения компонент. Значение потом идёт напрямую от источника к приемнику, игнорируя уровни иерархии дизайна. ARK>Ну да, я так и понял. ИМХО, концептуально может быть и копирование значения (если это упрощает модель). А на деле копирование убирается компилятором.
Копирование компилятором не убирается, потому что его просто нет. )))
Сфокусируйся, плиз: выходной пин сигнального типа — это точка для подачи callback-листенера (см. IObservable, например), то бишь некое входное проперти/метод с т.з. "традиционного" ООП. Наоборот, входной пин — это выходное проперти, которое возвращает экземпляр листенера. Так вот, входной пин компонента на сколь угодно глубоком уровне иерархии можно протащить куда угодно наверх и затем обратно куда угодно в глубь другой иерархии. Такое протаскивание выполняется только в момент построения топологии схемы, а затем сигналы идут непосредственно от источника к приемнику.
В общем, сегодня за привычные ООП иерархии мы расплачиваемся эффективностью и действительно полагаемся на компилятор. Вот меня всегда жаба и давила, что электронщики за иерархии ничем не расплачиваются. Ведь все иерархии — они сугубо умозрительные на стадии дизайна.
ARK>Я лично считаю, что ссылочные типы не нужны.
Ссылочные типы позволяют избежать лишнего копирования. Но требуют ограничения на операции с ними.
Суть желаемого ограничения на типы-данные сводится к следующему: мутабельный тип — это явная ячейка для хранения иммутабельного значения.
Псевдокод:
data T {...}; // immutable data typemutable<T> var1 = T(); // mutable cell named var1
Проникнись на досуге, что будет в случае составного T. Т.е. с одной стороны, вроде бы и мутабельность есть, с другой стороны, любая мутабельность "транзакционна", т.к. в (предполагаемом) языке нет возможности описать составной мутабельный тип. Зато можно описать мутабельную переменную для хранения значения составного типа "целиком". У тебя не будет возможности подать мутабельную ссылку на часть значения "куда-то" и не знать, что же "где-то там" происходит с частью твоего значения. Ты сможешь подать только иммутабельную ссылку. Прямо отсюда становится возможным применять наработки автоматной теории к императивной программе .
Вот причем тут ссылочные типы в условиях мутабельности. Для иммутабельных значений ссылочный тип или нессылочный — не важно. В итоге это всё ведет к детерминированности и применимости наработок автоматной теории к программе. (На сегодня её применять в полный рост нельзя — из-за врожденной недетерминированности кода, порождаемого современными императивными ЯВУ).
ARK>Вопрос только — что будет, если пересчитать не успели, а пришел новый сигнал? В теории можно обрубить вычисления, если результатом их не предполагается побочного эффекта.
Я же сказал — зависит от модели. В базисе сидит простая реактивная модель распространения сигнала. Но на пути его распространения ты можешь ставить дополнительные блоки/компоненты, которые могут превратить простую реактивную модель в некую более сложную. Например, поставь м/у приемником и получателем очередь (т.н. mail-box или channel), и введи новый дополнительный логический поток, который будет выгребать из всех входных мейлбоксов компонента и делать push в этом логическом потоке — вот тебе уже полноценная асинхронная агентская среда. Оно же COM STA в своё время — неимоверно удобно. А для многих сценариев подходящи более простые политики, чем бесконечная по размеру очередь событий, например — вырожденная очередь с 1-м элементом без потерь (блокирующая очередь), либо неблокирующая вырожденная очередь опять с 1-м элементом, но уже с потерей (перезаписью) старого значения. Пример для последнего — посылка оповещений о прогрессе некоей операции в поток GUI для отображения через progress-bar. Или например, у меня для целей обработки сигналов в каждом "разъеме" сидит защелка, а сами вычисления двухтактные: в первом такте происходит вычисление выходных значений всех компонент в зависимости от входных (формирование выхода), а в следующем такте эти вычисленные выходные значения запоминаются на защелках и попадают на входные пины целевых компонент. Таким образом, зацикливание есть, но оно потактовое, а не бесконечное (как ты опасался). А зацикливание это нужно обязательно — хотя бы на примере обычного затухающего эха. В простейшем варианте эхо реализуется на линии задержки с обратной связью.
В общем, обрати внимание на важный момент во всех этих реактивных/агенстких/тому_подобных_схемах — что в самой топологии связей и в политике доставки событий сидит львиная доля семантики конечной программы. Т.е. изкаробки даётся то, что сегодня составляет приличную часть кода многопоточных программ (где каждый программист решает одни и те же типовые задачи в меру своей испорченности, бесконечно дублируя друг друга и отрасль в целом). И еще заметь, что любые "политики" могут быть реализованы просто как промежуточные блоки/компоненты дизайна на пути распространения сигнала, то бишь, с одной стороны — универсальность, с другой стороны (двигаясь дальше в рассуждениях) наделять семантикой можно сами связи либо аппартаменты, в которых живут объекты. Опять на помню про COM/DCOM и предоставляемый автоматический маршаллинг для типов данных OLE и составных из них. Прикол в том, что описание маршаллинга декларативно, а задается отношениями аппартаметнов, в коорых живут компоненты. В общем, на COM/DCOM/OLE надо смотреть не только на интерфейс IUnknown, ес-но. На сегодня это самая развитая компонентная архитектура. Скажем так, CORBA или джавовские и дотнетные фреймворки по полноте охвата проблемы и близко не валялись. Если не веришь — попробуй на досуге накарябать GUI out of proc server.
ARK>Только будет ли компилятор достаточно умен, чтобы отслеживать такие вещи...
Не будет и не должен — это же часть семантики. По мне, дело "идеального" компилятора — предоставить удобные ср-ва для управления этой семантикой + некий фреймворк с кучей уже реализованных политик + возможность добавлять свои.
V>>Логику можно усложнить. Например, реагировать не на факт подачи сигнала, а лишь на изменение входного значения. ARK>ИМХО, имеет смысл реагировать только на изменение — во всех случаях.
Пример банального звукового кодека показывает — почему нет. Ведь важен каждый входной звуковой отсчет.
К сожалению, всё что я видел из готового на эту тему обычно обыгрывают какую-то одну модель распространения сигналов из перечисленных, так что любую другую модель приходится долго и нудно кодить ручками, как в обычном ООП.
V>>Кстате, для эрудиции, базовый в схемотехнике RS-триггер — это классический асинхронный автомат, то бишь, автомат, выполненый на "чистых" функциях — логических вентилях. ARK>Да, кое-что слышал об этом.
V>>Прямо отсюда должно быть понятно, почему я не сильно отличаю императивный и функциональный подход. Подобные устойчивые системы могут быть гораздо более сложными, чем RS-триггер. Могут состоять из кучи абсолютно чистых ф-ий, но при этом обладать изменяемым состоянием. Достаточно в ФП-программе суметь создать, например, циклическую структуру данных — и ву а ля, вот тебе изменяемое состояние из бесконечно считаемых по кругу ф-ий. Текущее устойчивое значение ф-ии на каждом витке вполне можно принять за состояние (как это есть в RS-триггере). Например, в упрощенном виде такая циклическая структура дана в виде монады IO в Хаскеле (при том, что её зацикливание выполняется внешним, по отношению к программе, вычислителем).
ARK>Тут уже появляется новая сущность — некое "устойчивое состояние" системы. ИМХО, это сильно усложняет понимание программы.
Ну как бы считается, что система должна переходить из одного устойчивого состояния в другое, в этом цель. Собсно, то, что называют "устойчивым к исключению кодом" с разными по силе гарантиями — это лишь разные градации приближения к обсуждаемому.
V>>Если компонент может сигнализировать об ошибке — пусть у него будет под это специальный пин. ARK>А если мы забудем поверить этот специальный пин?
А в 90% слчаев — и ради бога. Строй семантику как угодно. Например, ты можешь протянуть сигнал об ошибке на самый верх и реагировать на нее сразу, не дожидаясь обработки ошибки от нижних слоев. Эффект похож на достигаемый через исключения с одним отличием — детерминированность. Ведь подобная ошибка — это такой же "очередной" сигнал, а не "внеочередной", как исключения в менйстриме. Т.е. с одной стороны — такая же детерминированность как при пользовании кодами возвратов, с другой стороны — точно так же можно огранизовать топологию распространения сигнала ошибки сквозь уровни иерархий, как в механизме исключений.
V>>Если речь о зависимых типах, то мы просто не сможем подать на такой входной пин неподходящий выходной. Система типов не даст. ARK>Вот это интересный момент. Как вы себе это представляете? Это же те самые контракты.
Ну так ограничения, которые можно огранизовать через систему типов зависят исключительно от вида этой системы (от координаты в лямбда-кубе по ссылке). Введи себе параметризуемость термами в систему типов компоент и строй себе зависимые ограничения. Какие проблемы?
V>>Это цикл, а не короткое замыкание. Короткое замыкание — это когда гонки. А цикл — это очень полезная структура. )) ARK>Ну окей, пусть цикл. По-моему, возможность зацикливания надо бы устранить, нет?
Рекурсивные цифровые фильтры, фленжеры, ревербераторы и т.д. — это всё примеры зацикленных алгоритмов.
Я понимаю, о чем ты, просто прямое реактивное распростраение событий — это лишь базис, сверхку которого можно накладывать эффекты на распростраение сигнала. Например, возьми программную модель RS-триггера. В реальности логические ключи как бы "вычисляют" выходную ф-ию от входа непрерывно и постоянно. Но при моделировании в ПО, нет смысла пересчитывать бесконечно по кругу состояния вентилей триггера, если каждый новый пересчет не обновляет их выходы. На то оно и устойчивое состояние, что переходные процессы завершились. Вот он, переход от чистых ф-ий к памяти. Память — это всего лишь св-во устойчивости бесконечных вычислений.
Re[5]: Заметка: Компонентная философия и реализация
Большое спасибо за развернутый ответ.
V>Почти весь этот design by contract можно вложить в систему типов хотя бы С++ еще аж прошлого стандарта безо-всякого abstraction penalty. То бишь, это всё костыли для недостаточно выразительных систем типов в координатах лямбда-куба. В системах можно выразить вообще весь design by contract. С++ относится к системе типов Лw.
Я немного интересовался зависимыми типами, в принципе, они позволяют проверить многое. Но на С++ вряд ли возможно реализовать даже малую часть DBC. Как статически проверить штуки типа "параметр > 3"?
V>В любом случае, я бы не стал ограничения на входные и выходные данные приравнивать к семантике. V>Ну ОК, тогда не стоит пользоваться термином "семантика" для описания того, что же нам гарантируют типизированные интерфейсы. Собсно, об этом я и говорил.
Как я понимаю, семантика в более широком смысле — это нечто типа такой ситуации: в методе 4-этажная формула, определенная комбинация параметров в которой приводит к делению на ноль. В результате предусловием метода является еще более адская формула, обратная первой (получается, что смысла в такой проверке не много). Или речь не о том?
V>Ага, т.е. чем "жирнее" интерфейс, тем меньше вероятность его "случайной" реализации, не?
Разумеется.
V>Я примерно так себе и представляю причину, почему идея разбить кортеж ф-ий контракта на относительно независимые сигналы встречает инстинктивное сопротивление (не ты первый). Ведь кортеж — уже некое ограничение само по себе.
Можно предложить ввести поверх независимых сигналов несколько "сценариев использования" (необязательных). Типа интерфейсов, но с использованием одних и тех же входов-выходов, определяющих последовательность дергания и все такое. Соответственно, если хоть один сценарий такой определен, то мимо него с компонентом работать нельзя.
V>>>Это зависит от модели расрпостранения сигналов. Если синхронная модель — то последовательность вызовов имеет смысл. Если асинхронная, то тоже имеет, но уже по-другому (реакция лишь на изменения значения, а не на факт поступления 2-в-1-м — сигнала+события).
Вы предполагаете использование обеих моделей? Или все равно в конце концов должна быть выбрана какая-то одна? По-моему, код программы должен писаться строго под какую-то одну. Базис, наверное, все же синхронный, стало быть последовательность вызовов контролировать было бы неплохо.
V>Боюсь, лучшим выходом здесь будут не контракты, предписывающие что в каком порядке дергать, а декларативность. Угу, в сочетании с изменяемым состоянием. Необходимо описать реакцию на входное воздействие. Т.к. низлежащий вычислитель будет гарантировать отсутствие гонок, то эта реакция вполне может пользоваться персистентными данными (сохраняемыми от вызова к вызову). Поэтому становится возможным реализовать, например, рекурсивный цифровой фильтр:
Хм, тогда получается, что почти всегда должен быть выход "ошибка", если функция не определена при определенных комбинациях входов — ведь реакция должна быть всегда. ИМХО, явный запрет на встраивание компонента "неправильным образом" повысило бы надежность системы.
V>Не внутри, а снаружи. Синхронизация в пользовательском коде — самый быстрый путь к дедлокам. )) V>Я уже не говорю о провальной получаемой эффективности, если решать вопросы синхронизации "по-месту" и таких мест набирается немеряно.
Тогда тут надо прояснить, в каком виде вы предполагаете иметь изменяемое состояние:
1. Обычные "поля с данными", а-ля ООП. Как тут внешнюю синхронизацию сделать, я не знаю.
2. Хранение состояния через ввод "устойчивого состояния системы". Тут вся синхронизация автоматически обеспечивается внешним вычислителем.
V>Типы — ес-но. Просто хотел бы иметь некую иерархию типов: данные отдельно, "вычислители" — отдельно. И разные правила для разных сортов типов.
Есть еще вот такой момент. Мыслю с точки зрения обычного ООП. Например, мне нужна в моем компоненте работа с файлом. Значит я должен ввести кучу пинов, к которым подключаю компонент, работающий с файлами. Т.к. все пины только примитивных типов, то их будет куча для каждого мало-мальски сложного объекта. Нет ли тут проблемы?
V>Копирование компилятором не убирается, потому что его просто нет. )))
Ну, если в модели нет, то ради бога.
V>Такое протаскивание выполняется только в момент построения топологии схемы, а затем сигналы идут непосредственно от источника к приемнику.
Да, это я понял.
V>Суть желаемого ограничения на типы-данные сводится к следующему: мутабельный тип — это явная ячейка для хранения иммутабельного значения. V>Проникнись на досуге, что будет в случае составного T. Т.е. с одной стороны, вроде бы и мутабельность есть, с другой стороны, любая мутабельность "транзакционна", т.к. в (предполагаемом) языке нет возможности описать составной мутабельный тип. Зато можно описать мутабельную переменную для хранения значения составного типа "целиком". У тебя не будет возможности подать мутабельную ссылку на часть значения "куда-то" и не знать, что же "где-то там" происходит с частью твоего значения. Ты сможешь подать только иммутабельную ссылку. Прямо отсюда становится возможным применять наработки автоматной теории к императивной программе .
Понятно. Хотя я не вижу, где в вашей модели нужна мутабельность, кроме как в переменных внутри метода для простоты программирования.
V>Я же сказал — зависит от модели. В базисе сидит простая реактивная модель распространения сигнала. Но на пути его распространения ты можешь ставить дополнительные блоки/компоненты, которые могут превратить простую реактивную модель в некую более сложную. Например, поставь м/у приемником и получателем очередь (т.н. mail-box или channel), и введи новый дополнительный логический поток, который будет выгребать из всех входных мейлбоксов компонента и делать push в этом логическом потоке — вот тебе уже полноценная асинхронная агентская среда. Оно же COM STA в своё время — неимоверно удобно. А для многих сценариев подходящи более простые политики, чем бесконечная по размеру очередь событий, например — вырожденная очередь с 1-м элементом без потерь (блокирующая очередь), либо неблокирующая вырожденная очередь опять с 1-м элементом, но уже с потерей (перезаписью) старого значения. Пример для последнего — посылка оповещений о прогрессе некоей операции в поток GUI для отображения через progress-bar. Или например, у меня для целей обработки сигналов в каждом "разъеме" сидит защелка, а сами вычисления двухтактные: в первом такте происходит вычисление выходных значений всех компонент в зависимости от входных (формирование выхода), а в следующем такте эти вычисленные выходные значения запоминаются на защелках и попадают на входные пины целевых компонент. Таким образом, зацикливание есть, но оно потактовое, а не бесконечное (как ты опасался). А зацикливание это нужно обязательно — хотя бы на примере обычного затухающего эха. В простейшем варианте эхо реализуется на линии задержки с обратной связью.
Если я правильно понял, то в модели автоматическое отсечение ненужных вычислений не предполагается. В принципе, это разумно, потому что это всего лишь оптимизация.
ARK>>Только будет ли компилятор достаточно умен, чтобы отслеживать такие вещи... V>Не будет и не должен — это же часть семантики. По мне, дело "идеального" компилятора — предоставить удобные ср-ва для управления этой семантикой + некий фреймворк с кучей уже реализованных политик + возможность добавлять свои.
Да нет, не часть семантики, в том-то и дело. Я говорю о 100% бесполезных вычислениях (потерявших актуальность в результате прихода нового сигнала). А бесполезные они или нет — определяется как раз топологией соединения. Или я чего-то не понимаю.
V>Пример банального звукового кодека показывает — почему нет. Ведь важен каждый входной звуковой отсчет.
Да, совершенно верно.
V>>>Если компонент может сигнализировать об ошибке — пусть у него будет под это специальный пин. ARK>>А если мы забудем поверить этот специальный пин? V>А в 90% слчаев — и ради бога. Строй семантику как угодно. Например, ты можешь протянуть сигнал об ошибке на самый верх и реагировать на нее сразу, не дожидаясь обработки ошибки от нижних слоев. Эффект похож на достигаемый через исключения с одним отличием — детерминированность. Ведь подобная ошибка — это такой же "очередной" сигнал, а не "внеочередной", как исключения в менйстриме. Т.е. с одной стороны — такая же детерминированность как при пользовании кодами возвратов, с другой стороны — точно так же можно огранизовать топологию распространения сигнала ошибки сквозь уровни иерархий, как в механизме исключений.
Вот не нравится мне этот момент. Я, как программист, могу просто забыть этот пин проверить. Это как возврат кода ошибки в С. А результат функция все равно вернет, причем валидный — просто какое-то дефолтное значение. Аналог — в дотнете вызываем Int32.TryParse(str, out val) и берем val, не проверив результат функции. В val всегда что-то будет, но блин — это же неправильно.
А вот если бы TryParse возвращал (None | Some Int32), то все — не отвертишься, ошибку надо проверить.
Или содержал предусловие IsValidString(), которое обязывало бы программиста вызвать этот самый IsValidString перед вызовом Parse.
V>Ну так ограничения, которые можно огранизовать через систему типов зависят исключительно от вида этой системы (от координаты в лямбда-кубе по ссылке). Введи себе параметризуемость термами в систему типов компоент и строй себе зависимые ограничения. Какие проблемы?
Понял. Т.е. этот момент вы рассматриваете отдельно от модели. Поэтому мои рассуждения выше, похоже, не в тему.
V>Я понимаю, о чем ты, просто прямое реактивное распростраение событий — это лишь базис, сверхку которого можно накладывать эффекты на распростраение сигнала. Например, возьми программную модель RS-триггера. В реальности логические ключи как бы "вычисляют" выходную ф-ию от входа непрерывно и постоянно. Но при моделировании в ПО, нет смысла пересчитывать бесконечно по кругу состояния вентилей триггера, если каждый новый пересчет не обновляет их выходы. На то оно и устойчивое состояние, что переходные процессы завершились. Вот он, переход от чистых ф-ий к памяти. Память — это всего лишь св-во устойчивости бесконечных вычислений.
Понятно.
Еще пришло в голову вот что: можно ли подключить к одному выходу произвольное количество входов? Типа multicast delegate в дотнете.
Если нет, то такое ограничение вроде как бесполезно: мы ведь всегда можем сделать разветвитель, тупо пробрасывающий один вход на произвольное количество выходов?
Re[21]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
AC>У меня есть и поля(забегая немного вперёд — у меня, интерфейсы(публичные контракты) состоят только из полей, а методы это поля функционального типа(которым могут присваиваться функции)). AVK>>У меня тот же. Я вот только не пойму что ты подразумеваешь под потоками данных. К примеру, поток координат и нажатий кнопок от мыша — это поток данных или нет? AC>Да, это поток данных(а точнее сообщений), извлекаемых main thread'ом из очереди, в цикле без callback'ов.
Извлекает у тебя диспетчер (алгоритм из ровно 2-х строчек), который затем раздает сообщения целевым оконным ф-иям. Каждая такая оконная ф-ия — классический callback.
Re[22]: Заметка: Компонентная философия и реализация
AVK>>>У меня тот же. Я вот только не пойму что ты подразумеваешь под потоками данных. К примеру, поток координат и нажатий кнопок от мыша — это поток данных или нет? AC>>Да, это поток данных(а точнее сообщений), извлекаемых main thread'ом из очереди, в цикле без callback'ов. V>Извлекает у тебя диспетчер (алгоритм из ровно 2-х строчек), который затем раздает сообщения целевым оконным ф-иям. Каждая такая оконная ф-ия — классический callback.
Вообще из 4-х строк(две другие — while и TranslateMessage()), но не суть, это я к тому, что callback'и не единственной способ реализовать реакцию на сообщение.
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Re[23]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
V>>Извлекает у тебя диспетчер (алгоритм из ровно 2-х строчек), который затем раздает сообщения целевым оконным ф-иям. Каждая такая оконная ф-ия — классический callback. AC>Вообще из 4-х строк(две другие — while и TranslateMessage()), но не суть, это я к тому, что callback'и не единственной способ реализовать реакцию на сообщение.
Ес-но не единственный... Есть еще poll-схема вычислений (как раз эти 4 строчки), и большинство кода на сегодня написано именно в poll-стиле. Но попробуй написать всё GUI-приложение в этом poll-цикле диспетчеризации сообщений и ты увидишь, что местами push-схема удобней многократно. Хоть она и сложнее (требует инфраструктуру/поддержку).
Считай, что твои 4 строчи кода и DispatchMessage — это и есть инфраструктура для подержки реактивного подхода к построению программы.
Re[20]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexRK, Вы писали:
ARK>>>А если мы забудем поверить этот специальный пин? V>>А в 90% слчаев — и ради бога. Строй семантику как угодно. Например, ты можешь протянуть сигнал об ошибке на самый верх и реагировать на нее сразу, не дожидаясь обработки ошибки от нижних слоев. Эффект похож на достигаемый через исключения с одним отличием — детерминированность. Ведь подобная ошибка — это такой же "очередной" сигнал, а не "внеочередной", как исключения в менйстриме. Т.е. с одной стороны — такая же детерминированность как при пользовании кодами возвратов, с другой стороны — точно так же можно огранизовать топологию распространения сигнала ошибки сквозь уровни иерархий, как в механизме исключений.
ARK>Вот не нравится мне этот момент. Я, как программист, могу просто забыть этот пин проверить.
Не забудешь, ты же его не опрашиваешь, он пришлет тебе в стиле push оповещение. А если тебе нужны ограничения — то можно задать ограничение на запрет "висячего" состояния этого пина в компоненте-источнике. )) И тогда, чтобы намеренно проигнорировать этот пин, тебе придется явно подключить к нему каку-нить заглушку.
Сорри, я просто не знаю с какой степенью подробностей это всё объяснять — мне многое кажетсяи так понятным. Представь, что ты электронщик и собираешь из "рассыпухи" (кучи компонент) целевую схему. Некоторые компоненты могут давать сигнал ошибки, некоторые — нет. Например, сумматор может давать признак переноса, и ты можешь считать его согласно своей логики за ошибку (потерю значения) или нет, если это счетчик фазы, например, тогда переполнение до фени.. Просто ты согласно спецификации "протягиваешь" на выход сигнал, который для тебя является ошибкой. Как внести порядок в случай, когда у нас много таких источников? Например, ставишь некоторую логическую схему (приоритетную, скажем), на входах которой упорядочиваешь сигналы ошибок от "рассыпухи", а выход этой приоритетной схемы подаешь как выход ошибки компонента либо напрямую, либо обогащая некотороей "высокоуровневой" информацией уровня уже целого компонента.
Фильтрация исключений на стороне их перехвата в современном ПО делает тоже самое: выполняет некую логику по обслуживанию ошибок низлежащих компонент и формирует из них более высокоуровневые ошибки.
ARK>Это как возврат кода ошибки в С.
Дык, синхронные исключения (как в Java/C#) — это тоже как возврат кода ошибки, если смотреть на происходящее. Просто за синтаксисом ловли исключений catch и за иерархией самих объектов-исключений прячется точно такая же механика приоритизированных хуков — КОЛБЕКОВ! ))) Разве что спрятанная от тебя механика по выбору нужного хука проверяет не пользовательский числовой код, как в C, а некий внутренний числовой код — метку/хендл рантайм-типа проброшенного объекта-исключения...
А теперь информация к медитации: когда числодробилка на C++ построена на пустых throw() (объявляет, что ф-ия не выкидывает исключения), то она работает до 15%-25% быстрее, чем с включенными исключениями. А если отключить асинхронные исключения (SEH), то еще на 5% быстрее... Т.е. не бесплатно это всё.. надо же еще стек при этом раскручивать, так? Ведь выход из хука может вести на другой фрейм стека в иерархии вызовов. В С++ это делается неявным кодом, раскручивающим стек, в дотнете для аналогичного надо сказать компилятору using (транслируемый в finally), иначе содержимое фрейма молча отбрасывается. Поэтому в C#/Java исключения обычно дешевле плюсовых, если не посыпать код обильно try/catch... но зато запросто можно забыть о ресурсах (о using).
ARK>А результат функция все равно вернет, причем валидный — просто какое-то дефолтное значение.
Что захочешь, то и вернет. Не нужен отдельный "асинхронный" пин, рапортующий об ошибке? — сделай тип сигнала maybe<int>.
ARK>А вот если бы TryParse возвращал (None | Some Int32), то все — не отвертишься, ошибку надо проверить. ARK>Или содержал предусловие IsValidString(), которое обязывало бы программиста вызвать этот самый IsValidString перед вызовом Parse.
В случае maybe случае ты протягиваешь ошибку по "основному" каналу. Но дело дизайна, то бишь вкуса. Если нужна именно такая логика — ради бога. В другом месте может оказаться нужнее быстрее протянуть ошибку на нужный сколь угодно выскоий уровень по совсем другому пути, чем по логике основного сигнала. Т.е. я предлагаю по-сути механизм, аналогичный исключениям, только на порядки более гибкий... И да, ошибиться всегда тем легче, чем гибче.
V>>Ну так ограничения, которые можно огранизовать через систему типов зависят исключительно от вида этой системы (от координаты в лямбда-кубе по ссылке). Введи себе параметризуемость термами в систему типов компоент и строй себе зависимые ограничения. Какие проблемы?
ARK>Понял. Т.е. этот момент вы рассматриваете отдельно от модели. Поэтому мои рассуждения выше, похоже, не в тему.
С одной стороны — да, не в тему, бо для реализации реактивной среды нужен самый минимум в системе типов (достаточно умения косвенного вызова ф-ий, то бишь пойдёт любой язык с с возможностью косвенных вызовов процедур (ЯП с указателями на ф-ии, либо ООП, либо ФП).
С другой стороны, ограничения, выраженные через систему типов — это интересная тема сама по себе, в обсуждении которой я тоже обычно с удовольствием участвую. Просто эта тема ортогональна реактивности, бо эти же ограничения действуют и в "привычно-построенной" программе.
V>>Я понимаю, о чем ты, просто прямое реактивное распростраение событий — это лишь базис, сверхку которого можно накладывать эффекты на распростраение сигнала. Например, возьми программную модель RS-триггера. В реальности логические ключи как бы "вычисляют" выходную ф-ию от входа непрерывно и постоянно. Но при моделировании в ПО, нет смысла пересчитывать бесконечно по кругу состояния вентилей триггера, если каждый новый пересчет не обновляет их выходы. На то оно и устойчивое состояние, что переходные процессы завершились. Вот он, переход от чистых ф-ий к памяти. Память — это всего лишь св-во устойчивости бесконечных вычислений.
ARK>Понятно.
ARK>Еще пришло в голову вот что: можно ли подключить к одному выходу произвольное количество входов? Типа multicast delegate в дотнете.
Можно, такой multicast-callback называется паттерном Observer, и есть целый дотнетный фреймворк вокруг него для типа IObservable<>.
Это обратное подключение — зло. Ну реально, все "ужасы императива", которыми пугают нас функциональщики, связаны с тем, что одно и то же состояние может быть скрыто изменено. Почему так происходит? Потому что ссылка на состояние размножена по программе, .е. есть возможность асихронной подачи воздействий из разных мест. ИМХО, такая возможность не должна быть by default, как оно есть сейчас в многопоточном императивном ПО. Именно "агентские" среды и прочие конструкторы пытаются решить все эти проблемы случайных гонок, дав надежную асинхронную среду. Тут на сайте лежит перевод статьи по Сингулярити, есть о чем почитать на эту тему.
ARK>Если нет, то такое ограничение вроде как бесполезно: мы ведь всегда можем сделать разветвитель, тупо пробрасывающий один вход на произвольное количество выходов?
Именно так. Поэтому я в своих поделках всегда даю singlecast-callback, а "разветвитель" идет отдельным компонентом, дополняющим обычный callback до observer. Впрочем, я уже об этом писал: http://www.rsdn.ru/forum/philosophy/4957810.1
Здравствуйте, vdimas, Вы писали:
V>Строй семантику как угодно. Например, ты можешь протянуть сигнал об ошибке на самый верх и реагировать на нее сразу, не дожидаясь обработки ошибки от нижних слоев. Эффект похож на достигаемый через исключения с одним отличием — детерминированность. Ведь подобная ошибка — это такой же "очередной" сигнал, а не "внеочередной", как исключения в менйстриме. Т.е. с одной стороны — такая же детерминированность как при пользовании кодами возвратов, с другой стороны — точно так же можно огранизовать топологию распространения сигнала ошибки сквозь уровни иерархий, как в механизме исключений.
Да, это все верно. Главное, чтобы работа с этими детерминированными линиями ошибки не слишком засоряла основной функционал (этого как раз пытаются обычно достичь с помощью исключений).
V>Не забудешь, ты же его не опрашиваешь, он пришлет тебе в стиле push оповещение.
Ну на самом-то деле все равно где-то будет программный код — в описании функционала выходов. И в этом коде программист как раз должен "дергать" выходы другого компонента, возможно, при особых условиях.
Например. Есть компонент с двумя входами — A и B, одним выходом — C. Значение C = A / B.
Да, я могу запрограммировать C как "return (B != 0) ? (A / B) : 0", но я этого не хочу. Я хочу, чтобы C имел смысл только в случае, когда B != 0.
Таким образом, мы не можем подключить наш компонент как попало. Например, мы не имеем права поставить на вход B заглушку, подающую константу "0" (это не имеющий смысла пример, вырожденный случай) — программа не должна скомпилироваться.
V>А если тебе нужны ограничения — то можно задать ограничение на запрет "висячего" состояния этого пина в компоненте-источнике. )) И тогда, чтобы намеренно проигнорировать этот пин, тебе придется явно подключить к нему каку-нить заглушку.
Но ограничения могут быть более комплексными, чем просто запрет висячего провода.
V>Некоторые компоненты могут давать сигнал ошибки, некоторые — нет. Например, сумматор может давать признак переноса, и ты можешь считать его согласно своей логики за ошибку (потерю значения) или нет, если это счетчик фазы, например, тогда переполнение до фени.
А вдруг компонент не просто выдает опциональный сигнал ошибки, а требует, чтобы этот сигнал нельзя было проигнорировать?
ARK>>Это как возврат кода ошибки в С.
V>Дык, синхронные исключения (как в Java/C#) — это тоже как возврат кода ошибки, если смотреть на происходящее. Просто за синтаксисом ловли исключений catch и за иерархией самих объектов-исключений прячется точно такая же механика приоритизированных хуков — КОЛБЕКОВ! ))) Разве что спрятанная от тебя механика по выбору нужного хука проверяет не пользовательский числовой код, как в C, а некий внутренний числовой код — метку/хендл рантайм-типа проброшенного объекта-исключения...
Ну, что в самом низу, для верхнего программиста не так важно. Разница в том, что исключение все эти штуки делает за сценой, плюс его нельзя проигнорировать, в отличие от кодов ошибок.
V>Что захочешь, то и вернет. Не нужен отдельный "асинхронный" пин, рапортующий об ошибке? — сделай тип сигнала maybe<int>.
Maybe — это достаточно простая вещь, хотя и очень полезная. Кстати, а какие еще примитивные типы вы предполагаете использовать?
Но ограничения могут быть в теории гораздо более комплексные, чем maybe... Например, затрагивающие сразу несколько пинов.
V>С другой стороны, ограничения, выраженные через систему типов — это интересная тема сама по себе, в обсуждении которой я тоже обычно с удовольствием участвую. Просто эта тема ортогональна реактивности, бо эти же ограничения действуют и в "привычно-построенной" программе.
Да, это верно и для обычного программирования. Просто как-то мне кажется, что на реактивно-компонентную модель они могут лечь более естественно. Превращаются в этакие правила совместимости компонентов. Как разъем HDMI нельзя воткнуть в DVI.
Да, и все-таки интересно было бы услышать ваше мнение по поводу двух вопросов из прошлого моего поста:
Изменяемое состояние у вас предполагается в виде "устойчивых состояний системы"? (Выше по треду об этом был разговор на примере RS-триггера.) Или будет какой-то аналог полей-атрибутов из ООП (во что слабо верится)?
и
"Есть еще вот такой момент. Мыслю с точки зрения обычного ООП. Например, мне нужна в моем компоненте работа с файлом. Значит я должен ввести кучу пинов, к которым подключаю компонент, работающий с файлами. Т.к. все пины только примитивных типов, то их будет куча для каждого мало-мальски сложного объекта. Нет ли тут проблемы?"
Т.е. вопрос в том, не возникнет ли чрезмерного количества пинов у сложных компонентов из-за отсутствия абстрагирующих сложность сущностей типа ООП-шных объектов?
Здравствуйте, AlexCab, Вы писали:
AC>В этой заметке я расскажу, каким мне представляется программирование в недалёком будущем.
Ну это не совсем будущее, скорее начало 90х, OLE, вот это все
Будущее, как мне кажется, за технологиями, которые позволят легко программировать то, что сейчас программировать очень сложно, либо вообще невозможно, либо позволят вообще не программировать.
Например, такие вещи как MATLAB, R или Mathematica для целого круга задач подходят куда лучше чем обычные языки программирования. Иногда бывает так, что вместо разработки своего велосипеда, решающего некую проблему, намного проще, быстрее и эффективнее написать страницу кода на R и заинтерфейсить его из своего приложения.
В общем, я за специализированые инструменты и против серебрянных пуль в любом виде
Re[2]: Заметка: Компонентная философия и реализация
Здравствуйте, Lazin, Вы писали: L>Будущее, как мне кажется, за технологиями, которые позволят легко программировать то, что сейчас программировать очень сложно, либо вообще невозможно, либо позволят вообще не программировать.
Как раз над этим и работаю L>Например, такие вещи как MATLAB, R или Mathematica для целого круга задач подходят куда лучше чем обычные языки программирования. Иногда бывает так, что вместо разработки своего велосипеда, решающего некую проблему, намного проще, быстрее и эффективнее написать страницу кода на R и заинтерфейсить его из своего приложения.
MATLAB замечательный пример комбайна, создание и интегрирование которых, с помощью КОП, станет проще. L>В общем, я за специализированые инструменты и против серебрянных пуль в любом виде
Не согласен. Если цена использования универсального инструмента на множестве решаемых задач(M) равна или меньше цени использования множества специальных инструментов на M, лучше выбрать универсальный.
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Re[3]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
AC>MATLAB замечательный пример комбайна, создание и интегрирование которых, с помощью КОП, станет проще.
У матлаба уже есть своя компонентная модель, которая на мой взгляд намного лучше предложенной в статье. Компоненты, описаные в сатье похожи на обычные объекты, у которых есть интерфейсы, методы и тд. Т.е. сложный, структурированный интерфейс. Я могу их комбинировать самым обычнм образом. Это очень низкоуровневый инструмент, возможно он поможет писать код, но код мы и так писать умеем.
В матлабе же есть множество тулбоксов, каждый тулбокс содержит набор функций, имеет документацию и тд, но это не объект. Все функции, которые содержит тублокс работают с общими типами и доступны из их скриптового языка, с помощью которого выполняется комбинирование компонентов. Скажем, я могу взять OPC toolbox, получить данные в виде обычного вектора и далее, передать эти данные в simulink модель, построенную с помощью другого тулбокса(simulink). Нет никаких интерфейсов и хитрого способа получить OPCDataStream, реализующий IDataStream, который можно передать в метод SimulinkModel.SetInput(IDataStream) xD Но тем не менее все очень хорошо работает и комбинируется между собой. На самом деле, такой уровень удобства комбинирования различных компонентов как в MATLAB мало где можно встретить.
А компонентная модель из статьи породит огромное количество сущьностей и будет сложна в поддержке. Я так и не понял, в чем е поинт, она позволяет стандартизировать ABI, как COM, или упрощает программирование? Для чего она? (я правда все не осилил, может как-нибудь потом)
AC>Не согласен. Если цена использования универсального инструмента на множестве решаемых задач(M) равна или меньше цени использования множества специальных инструментов на M, лучше выбрать универсальный.
Ну, современные тенденции показывают, что специализированные инструменты обычно лучше решают задачу, нежели универсальлные. Скажем, erlang для разработки распределенных систем, ANTLR для создания парсеров и тд.
Re[4]: Заметка: Компонентная философия и реализация
AC>>MATLAB замечательный пример комбайна, создание и интегрирование которых, с помощью КОП, станет проще. L>У матлаба уже есть своя компонентная модель, которая на мой взгляд намного лучше предложенной в статье. Компоненты, описаные в сатье похожи на обычные объекты, у которых есть интерфейсы, методы и тд. Т.е. сложный, структурированный интерфейс.
Вам, как пользователю ПО, будет совершенно не обязательно знать об этом. Это нужно только разработчикам компонентов. L>Я могу их комбинировать самым обычнм образом.
Имея готовый набор компонентов(такой, как например MATLAB), вы сможете комбинировать их каким угодно образом или даже "позволить" им комбинироваться самостоятельно(разумеется если это предусмотрено разробами). L>Это очень низкоуровневый инструмент, возможно он поможет писать код, но код мы и так писать умеем.
Важно понимать что это(как и другие ЯП) всё таки инструмент для создания инструментов, а не для решения непосредственно прикладных задач, т.е. он не может быть "высокоуровневым". L>В матлабе же есть множество тулбоксов, каждый тулбокс содержит набор функций, имеет документацию и тд, но это не объект.
Да, это компоненты(хоть и примитивные). L>Все функции, которые содержит тублокс работают с общими типами и доступны из их скриптового языка, с помощью которого выполняется комбинирование компонентов. Скажем, я могу взять OPC toolbox, получить данные в виде обычного вектора и далее, передать эти данные в simulink модель, построенную с помощью другого тулбокса(simulink). Нет никаких интерфейсов и хитрого способа получить OPCDataStream, реализующий IDataStream, который можно передать в метод SimulinkModel.SetInput(IDataStream) xD Но тем не менее все очень хорошо работает и комбинируется между собой.
Видите как сложно, а моглибы просто написать "connect IData of OPCtoolbox to simulink", или соединить пару прямоугольников на диаграмме. L>На самом деле, такой уровень удобства комбинирования различных компонентов как в MATLAB мало где можно встретить.
Это пока, но скоро... L>А компонентная модель из статьи породит огромное количество сущьностей и будет сложна в поддержке.
Почему вы так считаете? L>Я так и не понял, в чем е поинт, она позволяет стандартизировать ABI, как COM, или упрощает программирование?
Both. L>Для чего она? (я правда все не осилил, может как-нибудь потом)
Для облегчения разработки компонентного ПО.
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Re[5]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
AC>Вам, как пользователю ПО, будет совершенно не обязательно знать об этом. Это нужно только разработчикам компонентов.
Я сужу с позиции разработчика а не пользователя.
L>>Это очень низкоуровневый инструмент, возможно он поможет писать код, но код мы и так писать умеем. AC>Важно понимать что это(как и другие ЯП) всё таки инструмент для создания инструментов, а не для решения непосредственно прикладных задач, т.е. он не может быть "высокоуровневым".
Ну так мы же говорим о "компонентах" приложения, компоненты должны быть высокоуровневыми сущностями в моем представлении. Компоненты — coarse grained штука, объекты ООП — fine grained. Тащить компонетны на уровень ниже на мой взгляд не имеет особого смысла, так как на этом уровне их потребуется слишком много. Допустим, на создание компонента нужно потратить столько же времени, сколько и на создание обычного класса + время на создание некоторой обвязки для поддержки компонентности + время на повторное использование(компонент нужно как минимум описать). Если абсолютно все представлять в виде компонентов, то можно получить весьма существенный оверхед на время разработки.
AC>Видите как сложно, а моглибы просто написать "connect IData of OPCtoolbox to simulink", или соединить пару прямоугольников на диаграмме.
Для этого где-то должны быть описаны IData и connect. В случае же матлаба, все всегда представлено в виде матриц и для связи компонентов нужно просто тупо передать матрицу из одного компонента в другой.
AC>Почему вы так считаете?
Я уже выше написал, она вводит доп. оверхед на разработку, если компоненты будут слишком низкоуровневыми, то они внесут значительный оверхед на разработку. Ну это как если бы мы вдруг решили использовать вместо обычных классов — COM компоненты. Можно сразу пойти и застрелиться. В статье копоненты живут на достаточно низком уровне, IMO, чтобы пойти и застрелиться
Re[6]: Заметка: Компонентная философия и реализация
AC>>Важно понимать что это(как и другие ЯП) всё таки инструмент для создания инструментов, а не для решения непосредственно прикладных задач, т.е. он не может быть "высокоуровневым". L>Ну так мы же говорим о "компонентах" приложения, компоненты должны быть высокоуровневыми сущностями в моем представлении. Компоненты — coarse grained штука, объекты ООП — fine grained.
В предлагаемой модели высокоуровневыми(coarse grained) являются сборки(компоненты из компонентов). Внутри компонентов(fine grained) — примитивные значения(как например int в Java). Т.е. всё что внутри(по отношению к компоненту) — примитивные значения, всё что снаружи — компоненты. Сами компоненты занимают как-бы промежуточный уровень, ввдение которого позволит реализовать "2)"(см.ниже).
L>Тащить компонетны на уровень ниже на мой взгляд не имеет особого смысла, так как на этом уровне их потребуется слишком много. Допустим, на создание компонента нужно потратить столько же времени, сколько и на создание обычного класса + время на создание некоторой обвязки для поддержки компонентности + время на повторное использование(компонент нужно как минимум описать). Если абсолютно все представлять в виде компонентов, то можно получить весьма существенный оверхед на время разработки.
1)Всё что целесообразно представить в виде примитивных значений(символы, числа, функции etc.) и их коллекций(строки, массивы данных/функций etc.), стоит представить именно так.
2)Компоненты и/или всё приложение может быть полностью или частично собрано из готовых компонентов(так же, как сейчас их собирают из готовых объектов, но проще).
AC>>Видите как сложно, а моглибы просто написать "connect IData of OPCtoolbox to simulink", или соединить пару прямоугольников на диаграмме. L>Для этого где-то должны быть описаны IData и connect. В случае же матлаба, все всегда представлено в виде матриц и для связи компонентов нужно просто тупо передать матрицу из одного компонента в другой.
Если бы... то: Матрица это тип примитивных данных (или прототип компонента) определённый разработчиками Matlab'а, в том числе для обмена между плагинами. IData это интерфейс определённый разработчиком simulink'а. Разработчик OPCtoolbox нашёл IData в документации и подумал: "было-бы хорошо чтобы мой компонент мог передавать матрицу прямиком в simulink-модель" и, реализовал комплимент к IData. А connect это оператор ЯП, он используется для подключения любых интерфейсов.
L>Я уже выше написал, она вводит доп. оверхед на разработку, если компоненты будут слишком низкоуровневыми, то они внесут значительный оверхед на разработку. Ну это как если бы мы вдруг решили использовать вместо обычных классов — COM компоненты. Можно сразу пойти и застрелиться.
Компоненты из заметки это _не_ COM-компоненты, они сами по себе проще, не говоря уж о использовании готовых.
L>В статье копоненты живут на достаточно низком уровне, IMO, чтобы пойти и застрелиться
Думаю, просто вы мыслете на "низком уровне", как если бы в восьмидесятые вы говорили: "Вздор! Как могут, динамические структуры с данными и указателями на функции, сделать программирование проще!?"
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Re[7]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
L>>Ну так мы же говорим о "компонентах" приложения, компоненты должны быть высокоуровневыми сущностями в моем представлении. Компоненты — coarse grained штука, объекты ООП — fine grained. AC>В предлагаемой модели высокоуровневыми(coarse grained) являются сборки(компоненты из компонентов). Внутри компонентов(fine grained) — примитивные значения(как например int в Java). Т.е. всё что внутри(по отношению к компоненту) — примитивные значения, всё что снаружи — компоненты. Сами компоненты занимают как-бы промежуточный уровень, ввдение которого позволит реализовать "2)"(см.ниже).
По моему таки низкоуровневый. Вот в примере http сервера, все компоненты — достаточно низкоуровневые сущности, например connection. Connection это никак не компонент, это обычный объект. Компонент это весь http сервер например.
AC>1)Всё что целесообразно представить в виде примитивных значений(символы, числа, функции etc.) и их коллекций(строки, массивы данных/функций etc.), стоит представить именно так. AC>2)Компоненты и/или всё приложение может быть полностью или частично собрано из готовых компонентов(так же, как сейчас их собирают из готовых объектов, но проще).
Сложнее. Например связи между компонентами. Вы предлагаете управлять памятью вручную, мало того, явно специфицировать тип соединения — статическое оно или динамическое. Мало того, что такой подход усложняет программирование. Он еще и усложняет или даже делает невозможным autowiring a-la spring и тд. Механизма интроспекции мною замечено небыло. Механизма управления ресурсами тоже (только временем жизни объектов).
AC>>>Видите как сложно, а моглибы просто написать "connect IData of OPCtoolbox to simulink", или соединить пару прямоугольников на диаграмме. L>>Для этого где-то должны быть описаны IData и connect. В случае же матлаба, все всегда представлено в виде матриц и для связи компонентов нужно просто тупо передать матрицу из одного компонента в другой. AC>Если бы... то: Матрица это тип примитивных данных (или прототип компонента) определённый разработчиками Matlab'а, в том числе для обмена между плагинами. IData это интерфейс определённый разработчиком simulink'а. Разработчик OPCtoolbox нашёл IData в документации и подумал: "было-бы хорошо чтобы мой компонент мог передавать матрицу прямиком в simulink-модель" и, реализовал комплимент к IData. А connect это оператор ЯП, он используется для подключения любых интерфейсов.
Я тут не очень понял. Какой еще IData в симулинке?
Вообще, я тут давно пытаюсь на одну простую мысль навести, но без толку. Прмер 1: есть много компонентов, у них есть множество интерфейсов, glue code должен соединять входы и выходы, возможно описывать какие либо адаптеры для преобразования интерфейсов. Это как если бы у нас была куча оборудования, у каждого устройства был бы свой тип разъема и мы все соединяли бы кабелями, иногда используя переходники. Пример 2: подход матлаба и некоторых других продуктов. У нас есть общая шина — в случае матлаба это workspace. По этой шине не передаются всякие сложные типы, вроде структур, только ограниченый набор примитивных типов, например числа, строки, массивы и словари. Ну а передача данных от компонента к компоненту может выполняться уже с помощью m-script. Это как если бы все наше оборудование подключалось бы к одной общей шине, а не друг к другу.
L>>В статье копоненты живут на достаточно низком уровне, IMO, чтобы пойти и застрелиться AC>Думаю, просто вы мыслете на "низком уровне", как если бы в восьмидесятые вы говорили: "Вздор! Как могут, динамические структуры с данными и указателями на функции, сделать программирование проще!?"
Наоборот, пока что вы придумали недо-COM. Идеи, реализованные в COM — куда более прогрессивны, там например нет привязки к языку, стандартизирван ABI, есть поддержка сложной динам. диспетчеризации, есть поддержка многопоточности(аппартаменты/маршалинг и все такое). COM — по настоящему модульная штука, а то что описано в статье — не очень.
Re[8]: Заметка: Компонентная философия и реализация
L>По моему таки низкоуровневый. Вот в примере http сервера, все компоненты — достаточно низкоуровневые сущности, например connection. Connection это никак не компонент, это обычный объект.
Какой же он объект У него нет ни полей ни методов, его нужно только создать и передать нач. параметры, а дальше он будет работать сам(т.е. им не нужно управлять).
(но вообще-то я стараюсь сделать компоненты более похожими на объекты, чтобы переход к компонентному программированию был более простым) L>Компонент это весь http сервер например.
Достаточно просто, упаковать все составляющие компоненты в сборку, и можно работать с сервером как с монолитной, единственной сущностью. AC>>2)Компоненты и/или всё приложение может быть полностью или частично собрано из готовых компонентов(так же, как сейчас их собирают из готовых объектов, но проще). L>Сложнее. Например связи между компонентами. Вы предлагаете управлять памятью вручную,
Ни в коем случае, нужно управлять только связями компонентов, а в идеале даже этого не требуется т.к. хорошим стилем считается разработка компонентов, которые самостоятельно управляют своими связями. L>мало того, явно специфицировать тип соединения — статическое оно или динамическое.
Нет, соединения компонентов всегда динамические(или вы мели ввиду что-то другое?). L>Мало того, что такой подход усложняет программирование. Он еще и усложняет или даже делает невозможным autowiring a-la spring и тд.
Насколько я понял, autowiring это возможность позволяющая автоматически заполнять поля объекта ссылками на другие объекты, для того чтобы сделать их доступными в контексте объекта. В КОП используется другой механизм, чтобы сделать один компонент доступным другому, необходимо соединить(подключить) их интерфейсы. L>Механизма интроспекции мною замечено небыло.
Непосредственно ЯП не поддерживается, но может быть реализована, например в виде интерфейса IComponentInfo. L>Механизма управления ресурсами тоже (только временем жизни объектов).
Управление ресурсами (кроме памяти) по идее должно выполняется компонентами, ответственными за эти ресурсы. Освобождение ресурсов в таких компонентах может выполнятся в деконструкторе, автоматически вызываемом при разрушении компонента. L>Я тут не очень понял. Какой еще IData в симулинке?
Это я описал как было бы, если б Matlab был построен по принципам КОП-модели из заметки. L>Вообще, я тут давно пытаюсь на одну простую мысль навести, но без толку. Прмер 1: есть много компонентов, у них есть множество интерфейсов, glue code должен соединять входы и выходы, возможно описывать какие либо адаптеры для преобразования интерфейсов. Это как если бы у нас была куча оборудования, у каждого устройства был бы свой тип разъема и мы все соединяли бы кабелями, иногда используя переходники.
Именно такой подход используется в переложенной модели, плюс компоненты могут соединятся самостоятельно(в этом случае glue code не нуже). L>Пример 2: подход матлаба и некоторых других продуктов. У нас есть общая шина — в случае матлаба это workspace. По этой шине не передаются всякие сложные типы, вроде структур, только ограниченый набор примитивных типов, например числа, строки, массивы и словари. Ну а передача данных от компонента к компоненту может выполняться уже с помощью m-script. Это как если бы все наше оборудование подключалось бы к одной общей шине, а не друг к другу.
Без проблем реализуется: один из компонентов — общая шина. L>Наоборот, пока что вы придумали недо-COM. Идеи, реализованные в COM — куда более прогрессивны, там например нет привязки к языку,
IDL? L>стандартизирван ABI,
Собственно для этого COM и созавался L>есть поддержка сложной динам. диспетчеризации,
Что имеется ввиду? L>есть поддержка многопоточности(аппартаменты/маршалинг и все такое).
Хочу сделать многокрасочность как в Go: каждый вызов функции в новом потоке. L>COM — по настоящему модульная штука, а то что описано в статье — не очень.
Да, COM хорошая штука, но он бинарный и он сложен в использовании.
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Re[9]: Заметка: Компонентная философия и реализация
Здравствуйте, AlexCab, Вы писали:
L>>Connection это никак не компонент, это обычный объект. AC>Какой же он объект У него нет ни полей ни методов, его нужно только создать и передать нач. параметры, а дальше он будет работать сам(т.е. им не нужно управлять).
Connection, в голове любого программиста, это соединение по какому-нибудь протоколу, которое умеет send/recv/close/shutdown. Код, который знает детали протокола обмена обычно вызывает эти методы, обмениваясь данными с удаленным хостом. Не понимаю как это "не нужно управлять".
L>>Компонент это весь http сервер например. AC>Достаточно просто, упаковать все составляющие компоненты в сборку, и можно работать с сервером как с монолитной, единственной сущностью.
А зачем тогда все делается на компонентах?
L>>мало того, явно специфицировать тип соединения — статическое оно или динамическое. AC>Нет, соединения компонентов всегда динамические(или вы мели ввиду что-то другое?).
Ну в статье идет речь о статических и динамических связях между компонентами, в разделе "управление памятью". Мне кажется делить связи по типам — излишнее усложнение.
L>>Мало того, что такой подход усложняет программирование. Он еще и усложняет или даже делает невозможным autowiring a-la spring и тд. AC>Насколько я понял, autowiring это возможность позволяющая автоматически заполнять поля объекта ссылками на другие объекты, для того чтобы сделать их доступными в контексте объекта. В КОП используется другой механизм, чтобы сделать один компонент доступным другому, необходимо соединить(подключить) их интерфейсы.
Я программист, я не хочу ничего писать, я хочу юзать готовое!
L>>Механизма интроспекции мною замечено небыло. AC>Непосредственно ЯП не поддерживается, но может быть реализована, например в виде интерфейса IComponentInfo.
Я программист, я не хочу ничего писать, я хочу юзать готовое!
AC>Управление ресурсами (кроме памяти) по идее должно выполняется компонентами, ответственными за эти ресурсы. Освобождение ресурсов в таких компонентах может выполнятся в деконструкторе, автоматически вызываемом при разрушении компонента.
Я программист, я не хочу ничего писать, я хочу юзать готовое!
AC>Без проблем реализуется: один из компонентов — общая шина.
Я программист, я не хочу ничего писать, я хочу юзать готовое!
L>>есть поддержка сложной динам. диспетчеризации, AC>Что имеется ввиду?
Я имел ввиду IDispatch.
L>>есть поддержка многопоточности(аппартаменты/маршалинг и все такое). AC>Хочу сделать многокрасочность как в Go: каждый вызов функции в новом потоке.
Это что-то странное, AFAIK, go так не работает. Там есть пулл потоков, но методы по дефолту не пушатся в пулл потоков, это не эффективно же!
AC>Да, COM хорошая штука, но он бинарный и он сложен в использовании.
Так у вас тоже не просто все. COM компоненты гораздо проще писать на .net например. И даже на С++ в студии, с использованием визардов и библиотеки ATL тоже не сказать что очень сложно. Но, по крайней мере COM существует в реальности. Поддерживается инструментами разработки. Многие продукты умеют работать как COM-сервер, например тот же MS Word. Поэтому, имеет смысл либо использовать COM, либо, обеспечить interop с ним.




 можно выразить вообще весь design by contract. С++ относится к системе типов Лw.
можно выразить вообще весь design by contract. С++ относится к системе типов Лw.